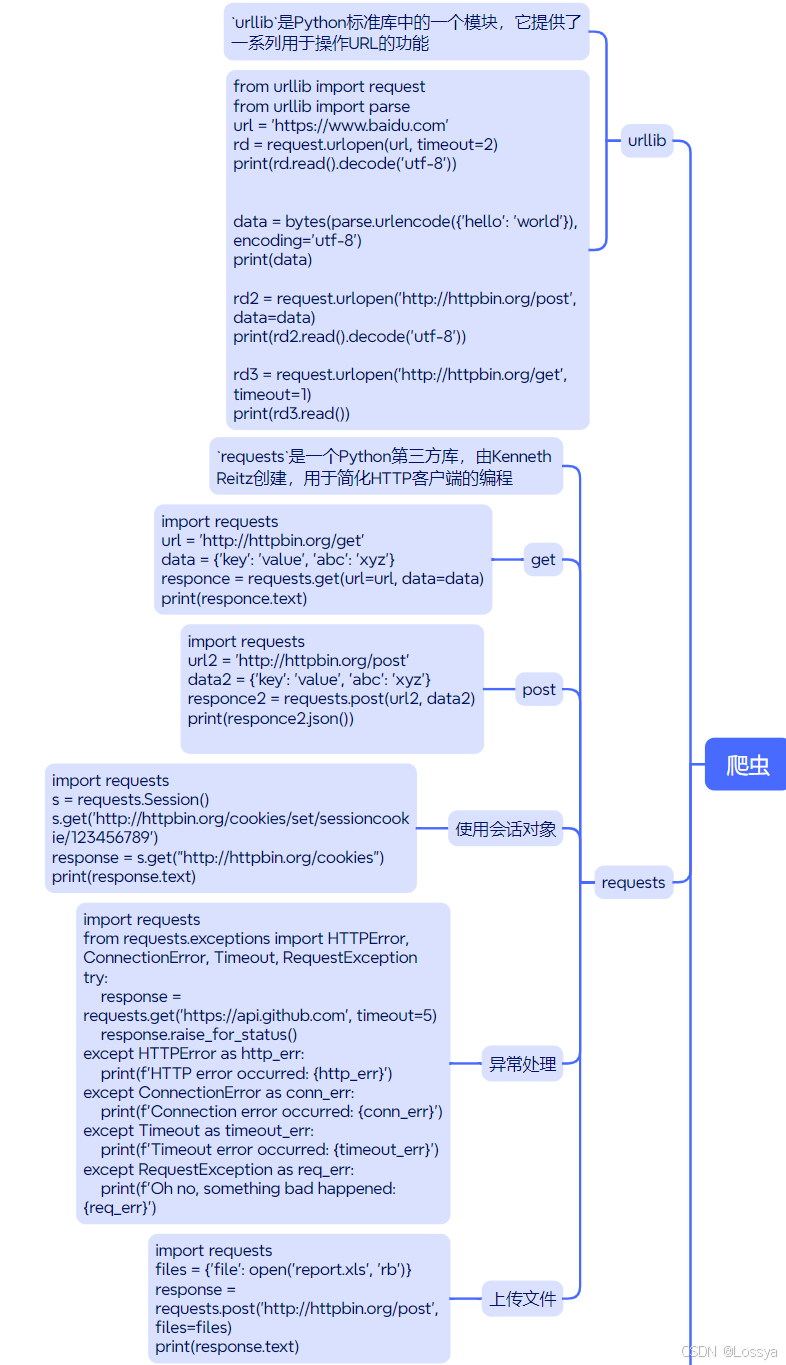
【python学习】爬虫中常使用的urllib和requests库的的背景、定义、特点、功能、代码示例以及两者的区别
引言
urllib是Python标准库中的一个模块,它提供了一系列用于操作URL的功能requests是一个Python第三方库,由Kenneth Reitz创建,用于简化HTTP客户端的编程
一、urllib的定义
urllib可以操作url,主要分为以下几个子模块:
1.1 urllib.request
用于打开和读取URLs
1.2 urllib.error
包含urllib.request引发的异常
1.3 urllib.parse
用于解析URLs
1.4 urllib.robotparser
用于解析robots.txt文件
二、urllib的特点
2.1 内置
urllib是Python标准库的一部分,因此不需要额外安装
2.2 功能全面
支持多种网络协议,包括HTTP、HTTPS、FTP等
2.3 易于使用
提供了简单易用的API,适合进行简单的网络请求操作
三、urllib的功能
3.1 打开URLs
使用urllib.request.urlopen()函数可以轻松打开一个URL
3.2 发送请求
支持发送GET、POST等HTTP请求
3.3 处理异常
urllib.error模块可以捕获和处理网络请求过程中出现的异常
3.4 解析URLs
urllib.parse模块可以解析和构造URLs
3.5 遵守robots.txt
urllib.robotparser模块可以帮助遵守网站的爬虫访问规则
四、urllib的代码示例
以下是使用urllib模块进行网络请求的几个示例:
4.1 发送GET请求
import urllib.request # 发送GET请求 with urllib.request.urlopen('http://www.example.com') as response: html = response.read() print(html.decode('utf-8')) 4.2 发送POST请求
import urllib.request import urllib.parse url = 'http://httpbin.org/post' values = {'key': 'value'} data = urllib.parse.urlencode(values) data = data.encode('utf-8') # data should be bytes req = urllib.request.Request(url, data=data, method='POST') with urllib.request.urlopen(req) as response: print(response.read().decode('utf-8')) 4.3 处理异常
import urllib.request import urllib.error try: response = urllib.request.urlopen('http://www.example.com/404') except urllib.error.HTTPError as e: print(f'HTTPError: {e.code} {e.reason}') except urllib.error.URLError as e: print(f'URLError: {e.reason}') 4.4 解析URLs
from urllib.parse import urlparse result = urlparse('http://www.example.com/index.html;user?id=5#comment') print(result) # 输出:ParseResult(scheme='http', netloc='www.example.com', path='/index.html', params='user', query='id=5', fragment='comment') 以上示例展示了urllib库的一些基本用法,包括如何发送HTTP请求、如何处理请求异常以及如何解析URLs。由于urllib库功能丰富,这些示例只是冰山一角。
五、requests的定义
requests是基于urllib3,提供了一个更加用户友好的API来发送HTTP/1.1请求
六、requests的特点
6.1 简洁易用
requests的API设计简洁直观,易于上手和使用
6.2 功能丰富
支持HTTP连接保持和连接池,支持SSL/TLS验证,支持国际化和本地化等
6.3 无需手动处理编码
自动处理HTTP响应内容的编码问题
6.4 支持会话与 cookies
能够使用会话对象来跨请求保持某些参数,如cookies
6.5 支持插件
requests支持插件,可以轻松扩展其功能
七、requests的功能
7.1 发送各种HTTP请求(GET, POST, PUT, DELETE, HEAD, OPTIONS等)
7.2 处理请求参数、URL、头信息和内容数据
7.3 处理HTTP响应内容,包括JSON、XML、HTML等
7.4 使用会话对象来跨请求保持某些参数
7.5 上传文件
7.6 处理SSL证书验证
7.7 设置代理
7.8 异常处理
八、requests的安装
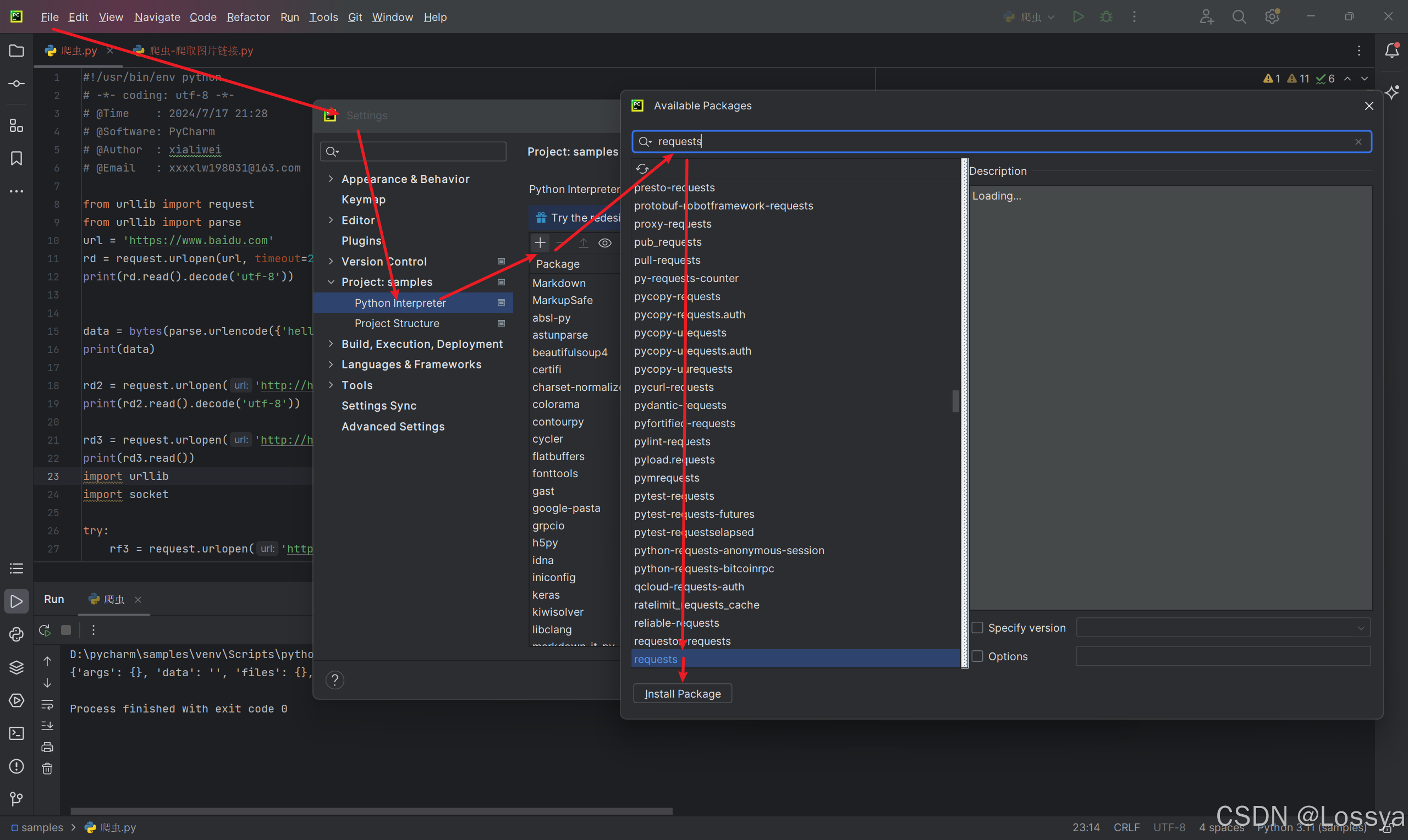
8.1 requests不是Python标准库的一部分,需要通过以下命令安装:
pip install requests 8.2 若是在pycharm中则按下图所示操作:
九、requests的代码示例
以下是使用requests库进行网络请求的几个示例:
9.1 发送GET请求
import requests response = requests.get('https://api.github.com/user', params={'username': 'example'}) print(response.json()) 9.2 发送POST请求
import requests data = {'key1': 'value1', 'key2': 'value2'} response = requests.post('http://httpbin.org/post', data=data) print(response.text) 9.3 使用会话对象
import requests s = requests.Session() s.get('http://httpbin.org/cookies/set/sessioncookie/123456789') response = s.get("http://httpbin.org/cookies") print(response.text) 9.4 异常处理
import requests from requests.exceptions import HTTPError, ConnectionError, Timeout, RequestException try: response = requests.get('https://api.github.com', timeout=5) response.raise_for_status() except HTTPError as http_err: print(f'HTTP error occurred: {http_err}') except ConnectionError as conn_err: print(f'Connection error occurred: {conn_err}') except Timeout as timeout_err: print(f'Timeout error occurred: {timeout_err}') except RequestException as req_err: print(f'Oh no, something bad happened: {req_err}') 9.5 上传文件
import requests files = {'file': open('report.xls', 'rb')} response = requests.post('http://httpbin.org/post', files=files) print(response.text) 这些示例展示了requests库的几个核心功能
- 发送请求
- 处理响应
- 使用会话
- 异常处理
- 上传文件
requests库因其简洁和强大而成为Python中处理HTTP请求的常用库
十、urllib和requests的区别
urllib和requests都是Python中用于发送HTTP请求的库,但它们在API设计、易用性、功能性和社区支持等方面存在一些显著的区别
10.1 API设计和易用性
- urllib:
- 作为Python标准库的一部分,无需额外安装
- 提供了较低级别的API,使用起来较为复杂,需要编写更多的代码来完成相同的任务
- 异常处理较为分散,需要分别捕获不同类型的异常
- requests:
- 需要单独安装,不是Python标准库的一部分
- 提供了简洁、直观的API,使得发送请求和处理响应变得极其简单
- 异常处理更加统一,通过
requests.exceptions模块来捕获和处理各种异常
10.2 功能性
- urllib:
- 功能相对基础,适合进行简单的请求
- 对于复杂的任务,如会话保持、cookie处理、SSL验证等,需要更多的手动操作
- requests:
- 功能更加全面,内置了会话对象、cookie持久化、SSL验证、连接池、JSON响应解析等高级功能
- 支持插件,可以轻松扩展其功能
10.3 社区支持
- urllib:
- 作为标准库的一部分,更新周期与Python相同,通常较为稳定
- 社区支持主要通过Python官方渠道
- requests:
- 社区驱动,更新频繁,社区支持广泛
- 由于是第三方库,可能包含更多最新的特性和改进
10.4 性能
- urllib:
- 对于简单的请求,性能通常足够
- 对于复杂的请求或并发操作,可能需要额外的库(如
http.client)来优化
- requests:
- 内部使用了
urllib3,因此在性能上有所优化,尤其是在并发请求时
- 内部使用了
示例对比
以下是使用urllib和requests发送GET请求的简单示例对比:
使用urllib发送GET请求:
import urllib.request import urllib.error try: with urllib.request.urlopen('http://example.com') as response: data = response.read() print(data.decode('utf-8')) except urllib.error.HTTPError as e: print(f'HTTPError: {e.code} {e.reason}') except urllib.error.URLError as e: print(f'URLError: {e.reason}') 使用requests发送GET请求:
import requests response = requests.get('http://example.com') print(response.text) 使用
requests发送网络请求通常更加简洁明了
然而,由于urllib是Python标准库的一部分,因此在不允许安装第三方库的环境中,urllib可能是唯一的选择
十一、总结(思维导图)