第4个明晓"WEPOKE私人局"外挂透明挂辅助器脚本!精准100%"竟然一贯是真有挂"(2023有挂版)
第4个明晓"WEPOKE私人局"外挂透明挂辅助器脚本!精准100%"竟然一贯是真有挂"(2023有挂版) 亲爱的,本文是小薇(136704302)给您介绍一下拥有黑科技的详细教程喔!祝您Happy every day~

一、wepoker破解工具设定好
1、WePoKer国外版透视形式:线上wepoker透视辅助挑战赛区分锦标赛形式,参赛选手实际多轮淘汰赛最后的角逐冠军。
2、wepoker透视脚本免费app安排:赛事设有预选赛、半决赛和决赛,每一轮的wepoker脚本下载大侠帮帮忙上接受。
3、WEPOKER高级辅助资格:一丝一毫具备wepoker底牌透视脚本技能的玩家都也可以报名参赛,没有地域和身份限制。
二、wepoker俱乐部辅助技术支持
1、在线WePoKer俱乐部作弊平台:按照专业的wepoker透视脚本下载ios帮帮忙平台,参赛选手这个可以实时地通过德州对战,享受流畅的游戏体验。
2、安全保障:线上wepoker透视脚本网页采用先进科学的加密技术,绝对的保证玩家个人信息和WePoKer破解演示安全。
3、扑克软件:线上WEPOKER作弊详细区分优质的扑克软件,切实保障公平是、安卓安装WePoKer教程的游戏环境。
三、wepoker透视脚本安卓机制
1、奖金丰厚:线上wepoker智能辅助丰厚的奖金池,wepoker透视底牌脚本是可以我得到高额奖金,激发玩家进行主动积极。
2、荣誉奖励:以外wepoker透视脚本下载奖励,线上WePoKer免费脚本还并入某些荣誉奖励,如年度最适合选手、最佳的方法进步选手等。
3、合作奖励:线上wepoker私人局辅助器与一些知名品牌合作,冠军可完成任务品牌推广机会和奖品找赞助。
四、参与wepoker辅助器安装包特点
1、技术要求:组织线上WePoKer辅助器下载不需要当然的扑克技术和经验,也让了一批技术精湛的玩家。
2、社交互动:线上wepoker辅助脚本为参赛选手提供给了应用范围的社交互动平台,提升了游戏的趣味和互动。
3、全球联合:的原因线上WEPOKER外挂视频的线上特,玩家可以不无论是世界各地,减少了参赛选手的多样和竞争激烈度。
五、学习wepoker透视辅助软件总结
今天凌晨两点,OpenAI开启了12天技术分享直播,发布了最新“强化微调”(Reinforcement Fine-Tuning)计划。
与传统的微调相比,强化微调可以让开发者使用经过微调的更强专家大模型(例如,GPT-4o、o1),来开发适用于金融、法律、医疗、科研等不同领域的AI助手。
简单来说,这是一种深度定制技术,开发者可利用数十到数千个高质量任务,参照提供的参考答案对模型响应评分,让模型学习如何就类似问题推理,提高其在特定领域任务上的准确性和工作效率。

申请API:https://openai.com/form/rft-research-program/
在许多行业,虽然一些专家具有深厚的专业知识和丰富的经验,但在处理大规模数据和复杂任务时,可能会受到时间和精力的限制。
例如,在法律领域,律师需要处理大量的法律条文和案例,虽然他们能够凭借专业知识进行分析,但借助经过强化微调的 AI 模型,可以更快速地检索相关案例、进行初步的法律条文匹配和分析,为律师提供决策参考,提高工作效率。
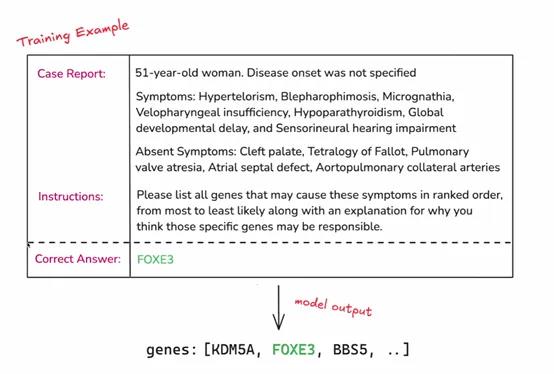
OpenAI表示,作为研究计划的一部分,参与者将能够访问处于alpha 阶段的强化微调 API。开发者可以利用该 API 将自己领域特定的任务数据输入到模型中,进行强化微调的实验和应用。
例如,一家医疗研究机构可以将大量的临床病例数据通过 API 输入到模型中,对模型进行医疗诊断任务的强化微调,使其能够更好地理解和处理各种疾病症状与诊断之间的关系。
目前该 API 仍处于开发阶段,尚未公开发布。所以,参与者在使用 API 过程中遇到的问题、对 API 功能的建议以及在特定任务上的微调效果等反馈,对于 OpenAI 改进 API 具有至关重要的作用。
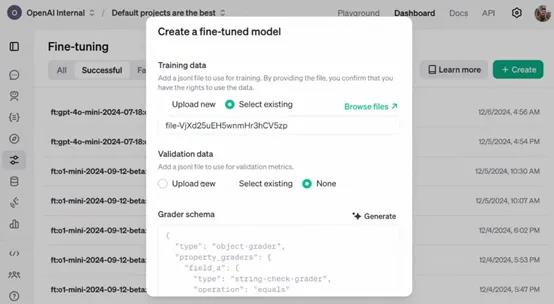
例如,企业在使用 API 对其财务风险评估模型进行微调时,如果发现模型在处理某些特殊财务数据结构时出现错误或不准确的情况,将这些信息反馈给 OpenAI,能够帮助其优化 API 中的数据处理算法和模型参数调整策略,从而使 API 更加完善,为后续的公开发布做好准备。
强化微调简单介绍
强化微调是一种在机器学习和深度学习领域,特别是在大模型微调中使用的技术。这项技术融合了强化学习的原理,以此来优化模型的性能。微调是在预训练模型的基础上进行的,预训练模型已经在大量数据上训练过,学习到了通用的特征。
通过无监督学习掌握了语言的基本规律,然后在特定任务上进行微调,以适应新的要求。强化学习则关注智能体如何在环境中采取行动以最大化累积奖励,这在机器人训练中尤为重要,智能体通过不断尝试和学习来找到最优策略。
强化微调则是将强化学习的机制引入到微调过程中。在传统微调中,模型参数更新主要基于损失函数,而在强化微调中,会定义一个奖励信号来指导这个过程。
这个奖励信号基于模型在特定任务中的表现,比如在对话系统中,模型生成的回答如果能够引导对话顺利进行并获得好评,就会得到正的奖励。策略优化是利用强化学习中的算法,如策略梯度算法,根据奖励信号来更新模型参数。
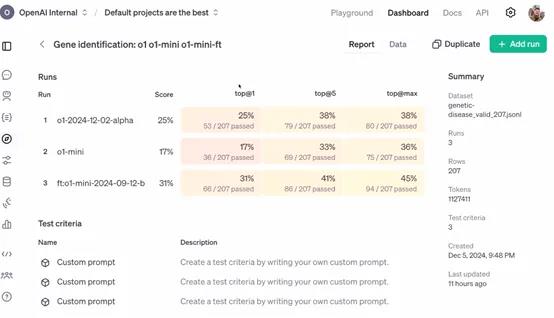
在这个过程中,模型就像智能体一样,它的参数调整策略就是需要优化的策略,而奖励信号就是对这个策略的评价。
此外,强化微调还需要平衡探索和利用,即模型既要利用已经学到的知识来稳定获得奖励,又要探索新的参数空间以找到更优的配置。
收集人类反馈数据,通常是关于模型输出质量的比较数据。通过这些反馈训练一个奖励模型,该模型能够对语言模型的输出进行打分,以反映其质量或符合人类期望。