bigdl-llm开发语音识别服务器
最近发现一个不错的量化库-bigdl-llm,他可以帮助开发者在英特尔的cpu上快速的跑大模型,他还支持langchian
BigDL-LLM是一个专为Intel XPU(包括CPU和GPU)设计的轻量级大语言模型加速库。它在Intel平台上拥有广泛的模型支持,最低的延迟和最小的内存占用。BigDL-LLM是开源项目BigDL的一部分,采用Apache 2.0许可证发布。
你可以用BigDL-LLM做什么 你可以使用BigDL-LLM运行任何PyTorch模型(比如HuggingFace transformers模型)。在运行过程中,BigDL-LLM利用了低比特优化技术、现代硬件加速技术和一系列软件优化技术来自动加速LLM。
使用BigDL-LLM非常简单,只需更改一行代码,你就可以立即看到显著的加速效果。BigDL-LLM提供了多种低比特优化选择(比如INT3/NF3/INT4/NF4/INT5/INT8),并允许你在多种Intel平台上演示LLM,包括入门级笔记本(只使用CPU)、配备Intel Arc独立显卡的高端电脑、至强服务器,或者数据中心GPU(如Flex、Max)。
系统建议 首先,你需要选择一个合适的系统。以下是推荐的硬件与操作系统列表:
硬件: 至少16GB内存的英特尔个人电脑 搭载英特尔至强处理器和至少32GB内存的服务器
操作系统: Ubuntu 20.04或更高版本 CentOS 7或更高版本 Windows 10/11,无论是否有WSL都可以
设置Python环境 接下来,使用Python环境管理工具(推荐使用Conda)创建Python环境并安装必要的库
安装参考:
pip install --pre --upgrade bigdl-llm[all]支持的python环境是Python 3.9、3.10和3.11
参考使用:
#load Hugging Face Transformers model with INT4 optimizations from bigdl.llm.transformers import AutoModelForCausalLM import AutoTokenizer model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True) #run the optimized model on CPU from transformers tokenizer = AutoTokenizer.from_pretrained(model_path) input_ids = tokenizer.encode(input_str, ...) output_ids = model.generate(input_ids, ...) output = tokenizer.batch_decode(output_ids)保存和加载轻量后的模型
model.save_low_bit(model_path) new_model = AutoModelForCausalLM.load_low_bit(model_path)已经验证过支持的大模型列表如下:
Model | CPU Example | GPU Example |
LLaMA (such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.) | link1 , link2 | link |
LLaMA 2 | link1 , link2 | link1 , link2-low GPU memory example |
ChatGLM | link | |
ChatGLM2 | link | link |
ChatGLM3 | link | link |
Mistral | link | link |
Mixtral | link | link |
Falcon | link | link |
MPT | link | link |
Dolly-v1 | link | link |
Dolly-v2 | link | link |
Replit Code | link | link |
RedPajama | link1 , link2 | |
Phoenix | link1 , link2 | |
StarCoder | link1 , link2 | link |
Baichuan | link | link |
Baichuan2 | link | link |
InternLM | link | link |
Qwen | link | link |
Qwen1.5 | link | link |
Qwen-VL | link | link |
Aquila | link | link |
Aquila2 | link | link |
MOSS | link | |
Whisper | link | link |
Phi-1_5 | link | link |
Flan-t5 | link | link |
LLaVA | link | link |
CodeLlama | link | link |
Skywork | link | |
InternLM-XComposer | link | |
WizardCoder-Python | link | |
CodeShell | link | |
Fuyu | link | |
Distil-Whisper | link | link |
Yi | link | link |
BlueLM | link | link |
Mamba | link | link |
SOLAR | link | link |
Phixtral | link | link |
InternLM2 | link | link |
RWKV4 | link | |
RWKV5 | link | |
Bark | link | link |
SpeechT5 | link | |
DeepSeek-MoE | link | |
Ziya-Coding-34B-v1.0 | link | |
Phi-2 | link | link |
Yuan2 | link | link |
Gemma | link | link |
DeciLM-7B | link | link |
Deepseek | link | link |
案例:使用bigdl结合flask部署一个whisper语音接口
pip install --pre --upgrade bigdl-llm[all] pip install flask pip install datasets soundfile librosa # required by audio processing
从Huggingface下载模型
网不好的话就从HF-Mirror
参考如下代码:
app = Flask(__name__) @app.route('/v1/audio/transcriptions', methods=['POST']) def upload_audio(): if request.method == 'POST': # 检查请求方法是否为 POST # 获取上传的录音文件 audio_file = request.files['audio_file'] # 从请求中获取名为 'audio_file' 的文件 if audio_file is None: # 检查是否上传了文件 return jsonify({'error': 'Audio file not provided'}), 400 # 如果没有上传文件,返回错误 JSON 和状态码 400 # 读取录音文件并获取采样率 # 保存音频文件到本地 file_path = os.path.join(audio_file.filename) # 设置音频文件的保存路径 audio_file.save(file_path) # 保存上传的音频文件到本地 data_en, sample_rate_en = librosa.load(file_path, sr=16000) # 使用 librosa 加载音频数据和采样率 # 加载模型 audio_model = AutoModelForSpeechSeq2Seq.load_low_bit(pretrained_model_name_or_path="./whisper-medium") # 加载低位宽的 Whisper 模型 audio_processor = WhisperProcessor.from_pretrained(pretrained_model_name_or_path="./whisper-medium") # 加载 Whisper 预处理器 #tokenizer = AutoTokenizer.from_pretrained(save_directory, trust_remote_code=True) # 如果有需要,加载自定义的 tokenizer # 定义任务类型 forced_decoder_ids = audio_processor.get_decoder_prompt_ids(language="zh", task="transcribe") # 获取解码器提示 ID,设置语言为中文,任务为转录 with torch.inference_mode(): # 将 PyTorch 设置为推理模式,以减少 GPU 占用 # 为 Whisper 模型提取输入特征 input_features = audio_processor(data_en, sampling_rate=sample_rate_en, return_tensors="pt", initial_prompt="以下是普通话的句子。").input_features # 为转录预测 token id st = time.time() # 开始时间戳 predicted_ids = audio_model.generate(input_features, forced_decoder_ids=forced_decoder_ids) # 生成预测的 token ID end = time.time() # 结束时间戳 # 将 token id 解码为文本 transcribe_str = audio_processor.batch_decode(predicted_ids, skip_special_tokens=True) # 将 token ID 批量解码为文本字符串 print(transcribe_str) # 打印解码后的文本 return jsonify({'transcription': transcribe_str}) # 将解码后的文本作为 JSON 响应返回 if __name__ == '__main__': app.run(host="0.0.0.0",port="3070")接下来可以用VSCODE调试
用postman测试你的接口
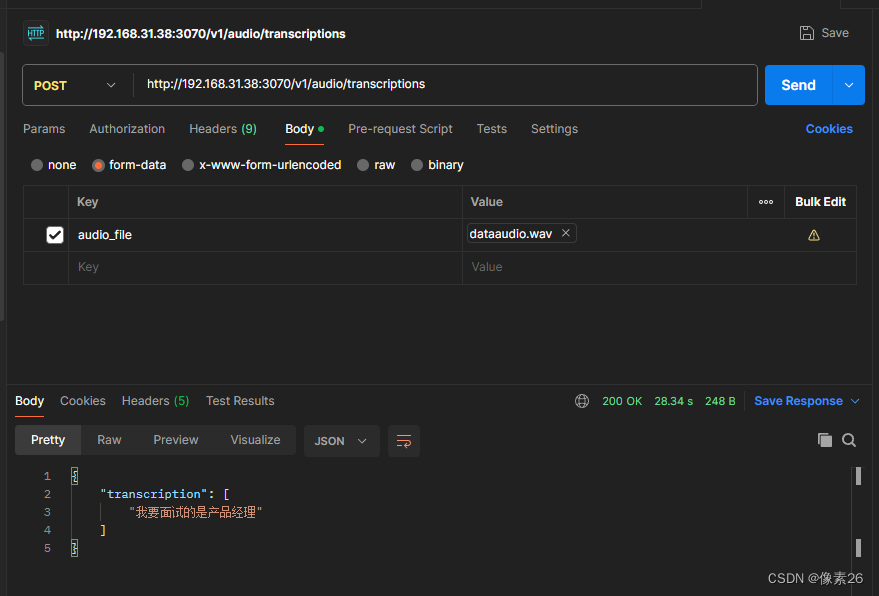
成功返回音频信息。使用bigdl-llm能在普通电脑快速的进行语音转换文字。
上一篇:oppo更新系统怎么恢复出厂设置
下一篇:让安卓系统识别4g卡