两个Python脚本轻松解决ETL工作:统计多个服务器下所有数据表信息
- 表中字段信息如下,代码设置了Excel表格式,网格根据字段数量自动填充
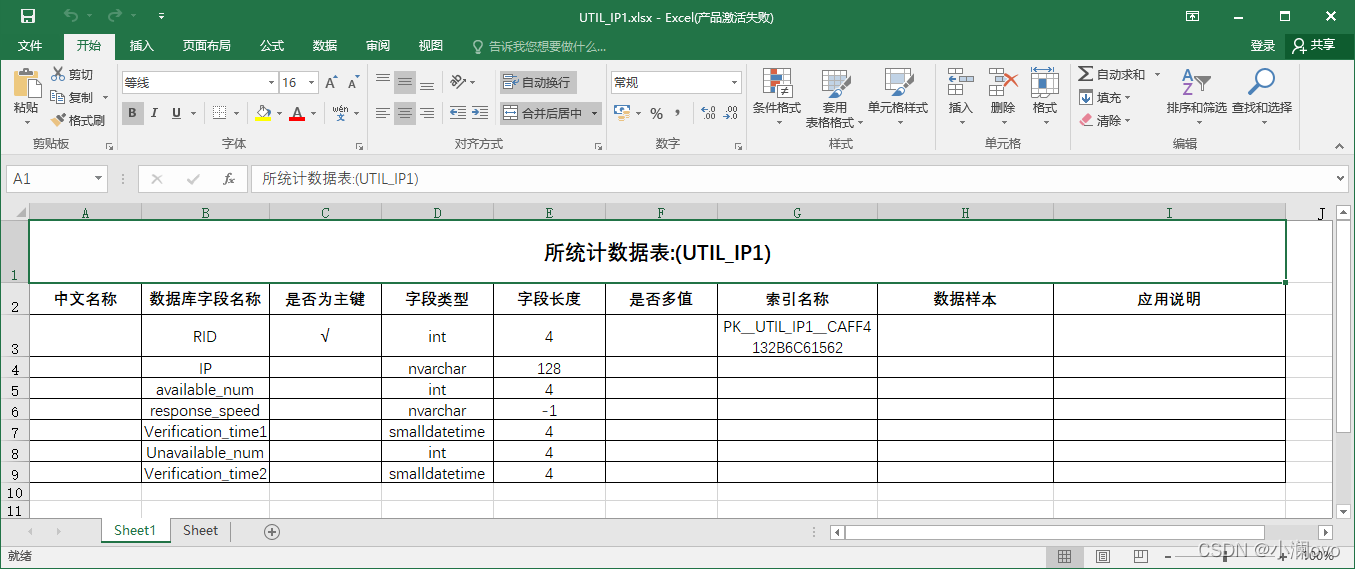
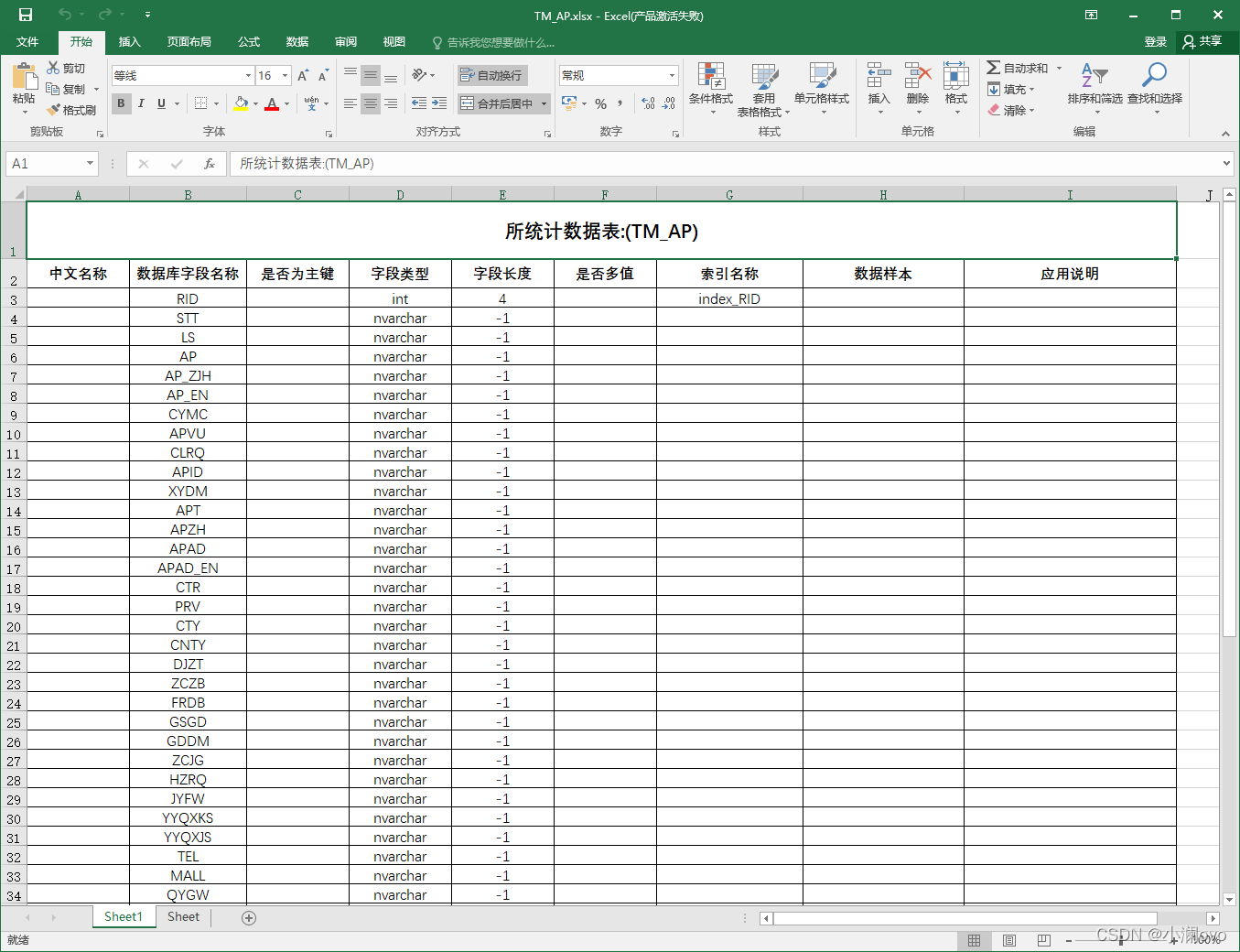
代码解析
由于和第一个脚本相似只讲讲思路:
1.获取所有数据库名
2.获取库中所有表名,把库名和表名存放在元组内放入列表,如:
[('test', 'student', 'UTIL_IP1', 'test4', 'test5', 'test6', 'TM_AP', 'test1', 'test2', 'test3', 'UTIL_IP')],第一个是库名其他都是表名3.拼接获取字段信息的SQL,把库名、表名传进去,SQL能获取到的信息如下图(拼接的地方为上面的库名和红框那的表名):
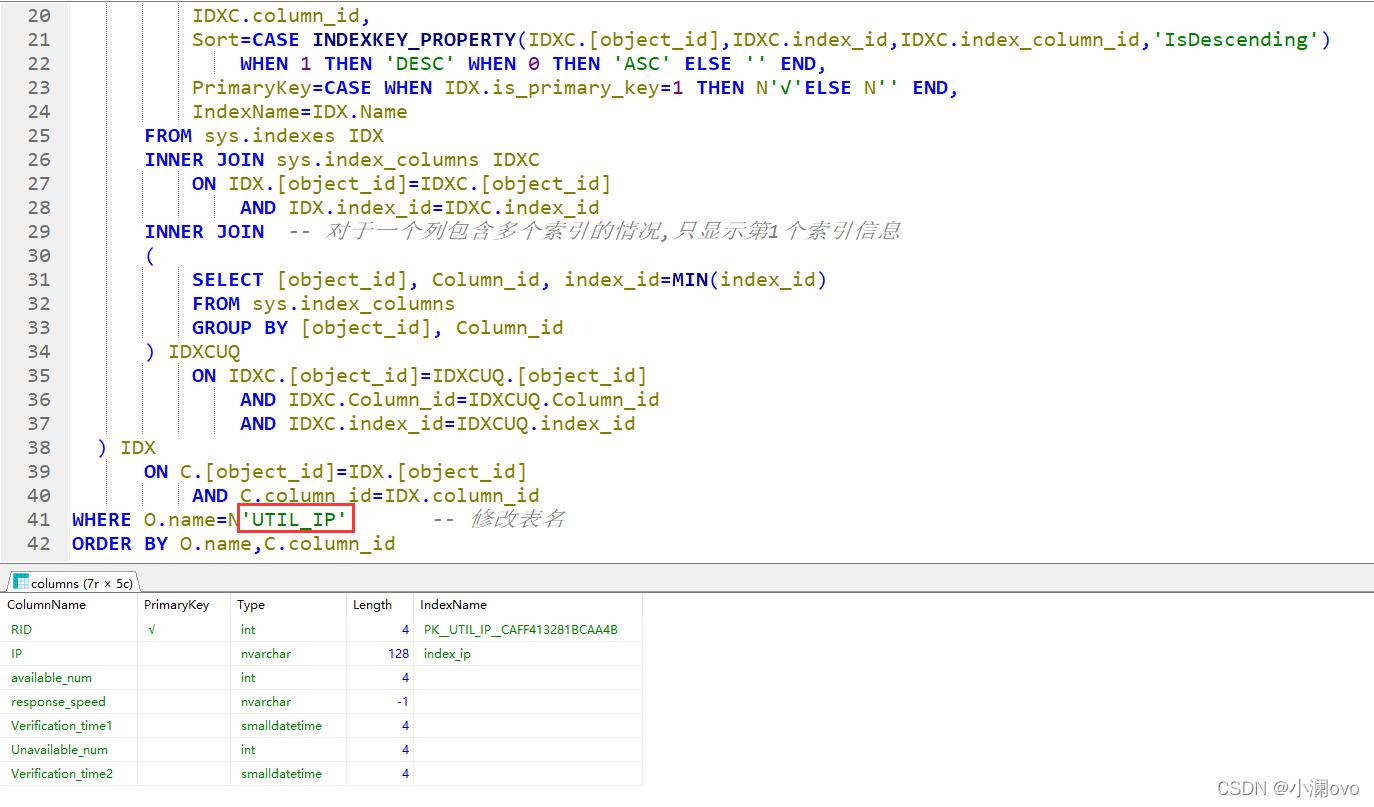
4.设置Excel内格式:字体、加粗、居中、合并、网格线、行高、列宽等
5.一个Excel文件保存完毕,生成另一个表的Excel文件,只到当前服务器下所有表统计完毕,才开始统计另一个服务器
完整代码
需要修改的地方只有服务器地址、账号、密码,每一个服务器信息放一个元组中;如果有多个服务器用逗号隔开
import pymssql
import openpyxl as op
from openpyxl.styles import Font, Alignment, Side, Border
import os
class ErTransUtils():
def get_databases_name(self, cursor):
“”“获取服务器下所有库名”“”
sql = ‘SELECT * FROM sys.sysdatabases’
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
存储
databases_name = []
for list in rows:
databases_name.append(list[0])
移除系统库和无用库
databases_name.remove(“master”)
databases_name.remove(“model”)
databases_name.remove(“msdb”)
databases_name.remove(“tempdb”)
try:
databases_name.remove(“ReportServer”)
databases_name.remove(“ReportServerTempDB”)
except Exception as e:
print(e)
print(databases_name)
return databases_name
def get_tables_name(self, databases_name, cursor):
“”“获取库中所有表名,并把对应的库名和表名存储在一起”“”
item1 = [] # 存储
for i in databases_name:
sql = f’SELECT * FROM [{i}].sys.tables’
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
item = []
for j in rows:
item.append(j[0])
item.insert(0, i)
item1.append(tuple(item))
return item1
def save(self, item1, cursor, server_name):
“”“获取表中字段信息,并写入Excel”“”
根据服务器名称创建目录
os.makedirs(server_name)
databases_name:[‘master’, ‘tempdb’, ‘model’, ‘msdb’, ‘ReportServer’, ‘ReportServerTempDB’, ‘test’]
取出每个库名
for database in item1:
根据库名名称创建目录
database1 = f’./{server_name}/{database[0]}’
os.makedirs(database1)
print(‘正在统计%s库’ % database[0])
for table in range(1, len(database)):
sql = ‘’’
USE [%s]
SELECT
ColumnName=C.name,
PrimaryKey=ISNULL(IDX.PrimaryKey,N’'),
Type=T.name,
Length=C.max_length,
IndexName=ISNULL(IDX.IndexName,N’')
FROM sys.columns C
INNER JOIN sys.objects O
ON C.[object_id]=O.[object_id]
AND O.type=‘U’
AND O.is_ms_shipped=0
INNER JOIN sys.types T
ON C.user_type_id=T.user_type_id
LEFT JOIN – 索引及主键信息
(
SELECT
IDXC.[object_id],
IDXC.column_id,
Sort=CASE INDEXKEY_PROPERTY(IDXC.[object_id],IDXC.index_id,IDXC.index_column_id,‘IsDescending’)
WHEN 1 THEN ‘DESC’ WHEN 0 THEN ‘ASC’ ELSE ‘’ END,
PrimaryKey=CASE WHEN IDX.is_primary_key=1 THEN N’√’ELSE N’’ END,
IndexName=IDX.Name
FROM sys.indexes IDX
INNER JOIN sys.index_columns IDXC
ON IDX.[object_id]=IDXC.[object_id]
AND IDX.index_id=IDXC.index_id
INNER JOIN – 对于一个列包含多个索引的情况,只显示第1个索引信息
(
SELECT [object_id], Column_id, index_id=MIN(index_id)
FROM sys.index_columns
GROUP BY [object_id], Column_id
) IDXCUQ
ON IDXC.[object_id]=IDXCUQ.[object_id]
AND IDXC.Column_id=IDXCUQ.Column_id
AND IDXC.index_id=IDXCUQ.index_id
) IDX
ON C.[object_id]=IDX.[object_id]
AND C.column_id=IDX.column_id
WHERE O.name=N’%s’ – 修改表名
ORDER BY O.name,C.column_id
‘’’ % (database[0], database[table])
执行sql语句
try:
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
except Exception as e:
print(e)
存储
lists = []
for list in rows:
lists.append(list)
获取字段的行数,+2表示Excel的行数
excel_line = len(lists) + 2
加入count是为了换行写入数据
count = 3
wb = op.Workbook()
ws = wb.create_sheet(index=0)
table_name = f’所统计数据表:({database[table]})’
ws.cell(row=1, column=1, value=table_name)
ws.cell(row=2, column=1, value=‘中文名称’)
ws.cell(row=2, column=2, value=‘数据库字段名称’)
ws.cell(row=2, column=3, value=‘是否为主键’)
ws.cell(row=2, column=4, value=‘字段类型’)
ws.cell(row=2, column=5, value=‘字段长度’)
ws.cell(row=2, column=6, value=‘是否多值’)
ws.cell(row=2, column=7, value=‘索引名称’)
ws.cell(row=2, column=8, value=‘数据样本’)
ws.cell(row=2, column=9, value=‘应用说明’)
整体格式
row_range = ws[1:excel_line]
for row in row_range:
for cell in row:
cell.font = Font(name=“等线”, size=12, bold=False, italic=False,
color=“00000000”) # name=字体名称,size=字体大小,bold=是否加粗,color=字体颜色
cell.alignment = Alignment(horizontal=“center”, vertical=“center”, wrap_text=True) # 字体上下左右居中
side1 = Side(style=“thin”, color=“00000000”)
side2 = Side(style=“thin”, color=“00000000”)
cell.border = Border(left=side1, right=side1, top=side2, bottom=side2) # 边框
设置列宽
ws.column_dimensions[‘A’].width = 14
ws.column_dimensions[‘B’].width = 16
ws.column_dimensions[‘C’].width = 14
ws.column_dimensions[‘D’].width = 14
ws.column_dimensions[‘E’].width = 14
ws.column_dimensions[‘F’].width = 14
ws.column_dimensions[‘G’].width = 20
ws.column_dimensions[‘H’].width = 22
ws.column_dimensions[‘I’].width = 29
单独设置应用说明列
column = f’I3:I{excel_line}’
font1 = ws[column]
for a in font1:
for a1 in a:
a1.alignment = Alignment(horizontal=“left”, vertical=“justify”, wrap_text=True)
设置第一行格式
ws.row_dimensions[1].height = 46.5 # 行高
ws.merge_cells(‘A1:I1’) # 合并单元格
cell = ws[“A1”]
cell.font = Font(name=“等线”, size=16, bold=True, italic=False,
color=“00000000”) # name=字体名称,size=字体大小,bold=是否加粗,color=字体颜色
设置第二行格式
ws.row_dimensions[2].height = 24 # 行高
font2 = ws[‘A2:I2’]
for b in font2:
for b1 in b:
b1.font = Font(name=“等线”, size=12, bold=True, italic=False,
color=“00000000”) # name=字体名称,size=字体大小,bold=是否加粗,color=字体颜色
for i in lists:
要写入excel的数据
field_name = i[0]
key_name = i[1]
field_type = i[2]
field_length = i[3]
index_name = i[4]
将数据写入到下一行
ws.cell(row=count, column=2, value=field_name)
ws.cell(row=count, column=3, value=key_name)
ws.cell(row=count, column=4, value=field_type)
ws.cell(row=count, column=5, value=field_length)
ws.cell(row=count, column=7, value=index_name)
count加1,进入到下一行写入数据
count += 1
excel_name = f’./{server_name}/{database[0]}/{database[table]}.xlsx’
wb.save(excel_name)
print(‘%s库统计完成’ % database[0])
def main(self):
服务器列表
list = [(‘.’, ‘sa’, ‘yuan427’)]
for server in list:
server_name = server[0]
user_name = server[1]
password = server[2]
conn = pymssql.connect(server_name, user_name, password)
if conn:
print(“连接成功!”)
cursor = conn.cursor()
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。
(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。
(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。
(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。
这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-SU0Pcv0j-1712468516484)]
上一篇:服务器项目部署,有备无患
下一篇:服务器硬件,raid配置