C++奇迹之旅:初始化列表与explicit

文章目录
- 📝再谈构造函数
- 🌠 构造函数体赋值
- 🌉初始化列表
- 🌉初始化列表效率
- 🌠隐式类型转换
- 🌉复制初始化
- 🌠单多参数构造函数
- 🌉explicit关键字
- 🚩总结
📝再谈构造函数
🌠 构造函数体赋值
在创建对象时,编译器通过调用构造函数,给对象中各个变量一个合适的初始值
class Date { public: Date(int year, int month, int day) { _year = year; _month = month; _day = day; } private: int _year; int _month; int _day; }; 虽然上面构造函数调用之后,对象中已经有了一个初始值,但是不能将其称为对对象中成员变量的初始化,构造函数体中的语句只能将其称为赋初值,这和我们之间常常说的给缺省值其实就是赋初值,而不能称作初始化。因为初始化只能初始化一次,而构造函数体内可以多次赋值。
🌉初始化列表
初始化列表:以一个冒号开始,接着是一个逗号分隔的数据成员列表,每个“成员变量”后面跟一个放在括号的初始化或表达式
class Date { public: Date(int year,int month,int day) :_year(year) ,_month(month) ,_day(day) { // } private: int _year; int _month; int _day; }; 为什么要有初始化列表来赋初值,不能直接给缺省值,或者传参吗?
class Date { public: Date(int year, int month, int day) { _year = year; _month = month; _day = day; _x = 1; } private: int _year; int _month; int _day; //必须在定义初始化 const int _x; }; 由于const必须在定义时就要进行初始化,而这个在构造函数中_x=1的行为是赋值行为,不是初始化,因此const 修饰_x无法再赋值。引用&也是如此,需要在定义的时候并且进行初始化,不能分开。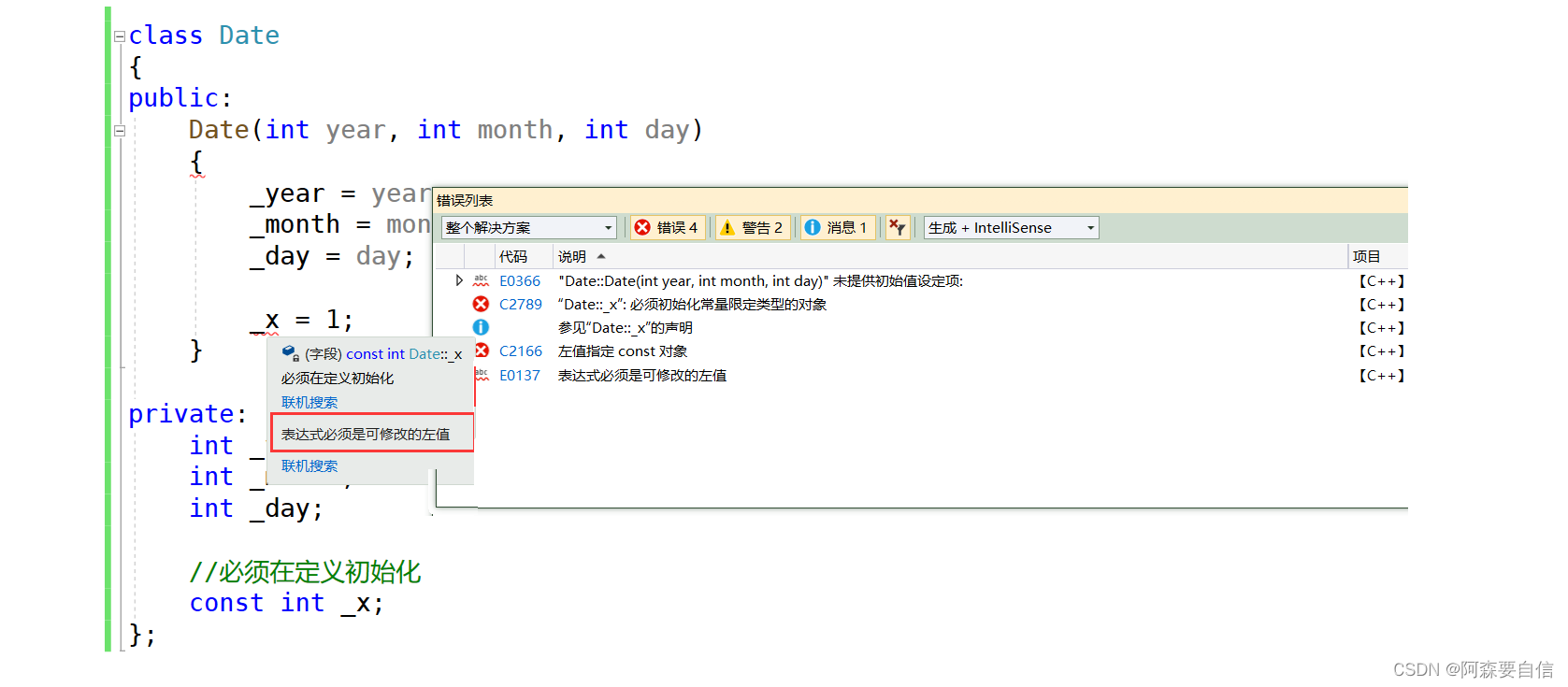
因此对于普通的内置类型,普通成员变量都可以在函数体或者在初始化列表进行初始化,
int _year; int _month; int _day; 因为在这里只是声明,没有定义,定义时实例化的时候完成的,而有些特殊的成员变量需要再定义的时候就初始化,而不是再通过赋值。
class Date { public: Date(int year, int month, int day, int& refDay) : ref(refDay) , _x(1) { _year = year; _month = month; _day = day; } void printDate() { std::cout << "Date: " << _year << "-" << _month << "-" << _day << std::endl; std::cout << "Reference day: " << ref << std::endl; std::cout << "Constant value: " << _x << std::endl; } private: int _year; int _month; int _day; int& ref; const int _x; }; int main() { int someDay = 22; Date date1(2024, 4, 22, someDay); date1.printDate(); return 0; } 
小知识:初始化和赋值之间的本质区别
初始化对象就是在对象创建的同时使用初值直接填充对象的内存单元,因此不会有数据类型转换等中间过程,也就不会产生临时对象;而赋值则是在对象创建好后任何时候都可以调用的而且可以多次调用的函数,由于它调用的是“=”运算符,因此可能需要进行类型转换,即会产生临时对象
但是类中包含以下成员,必须放在初始化列表位置进行初始化:
- 引用&成员变量
const成员变量- 自定义类型成员(且该类没有默认构造函数时)
class A { public: A(int a) :_a(a) {} private: int _a; }; class B { public: B(int a, int ref) :_aobj(a) , _ref(ref) , _n(10) {}; private: A _aobj; // 没有默认构造函数 int& _ref; //引用 const int _n;//const }; int main() { int x = 10; B bb(20, x); return 0; } 自定义类型成员(且该类没有默认构造函数时)会发生错误
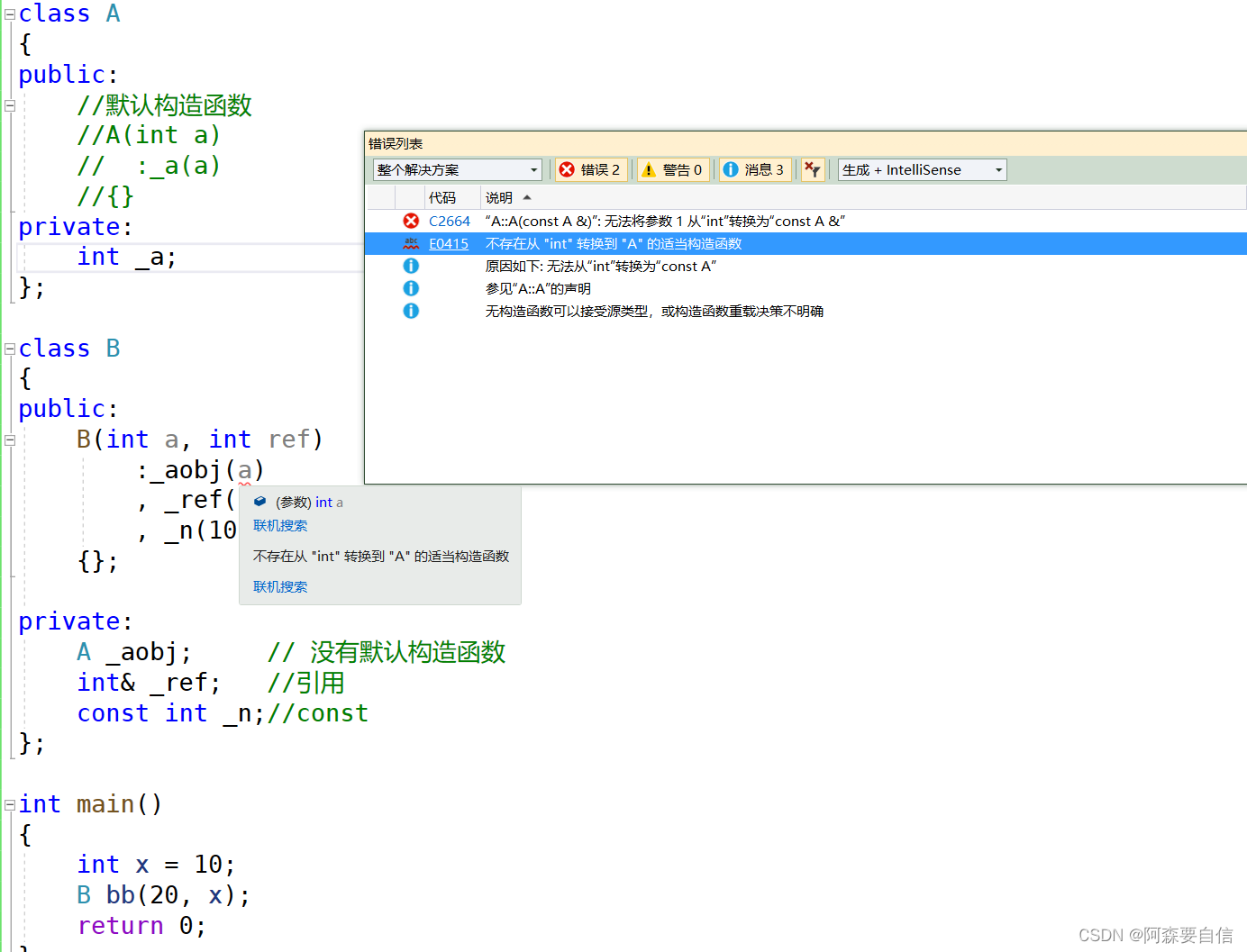
这是按F11一步一步运行的顺序: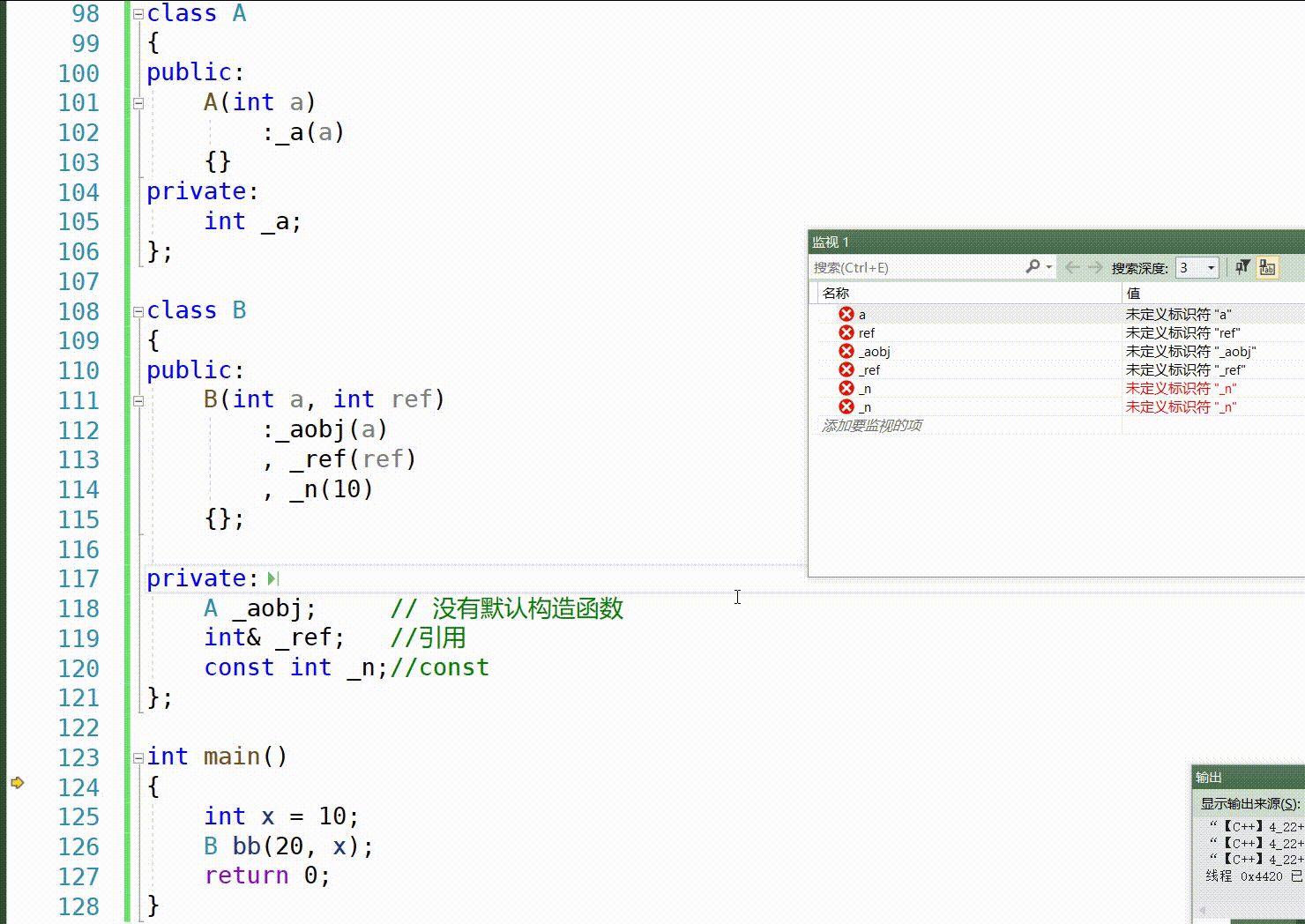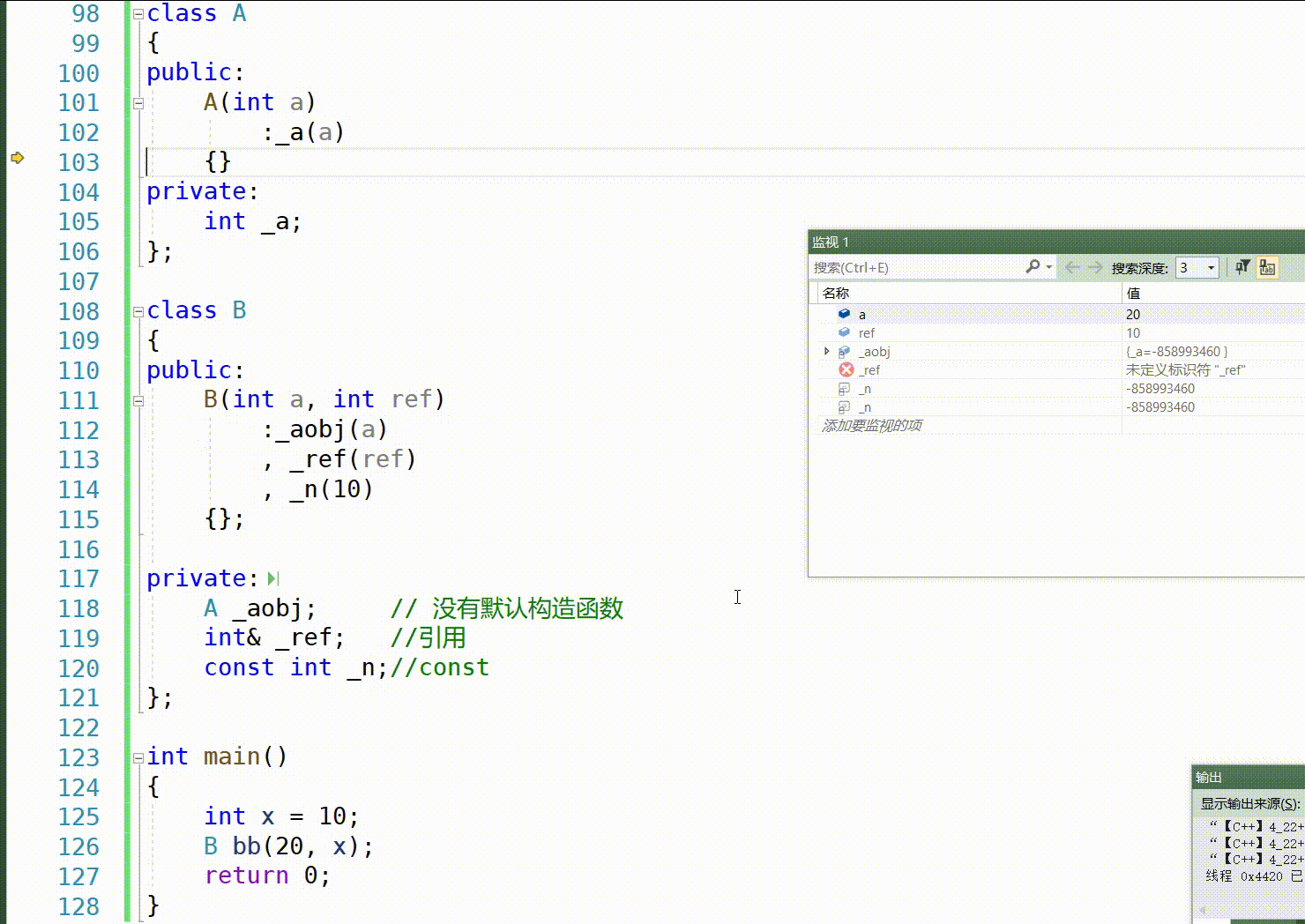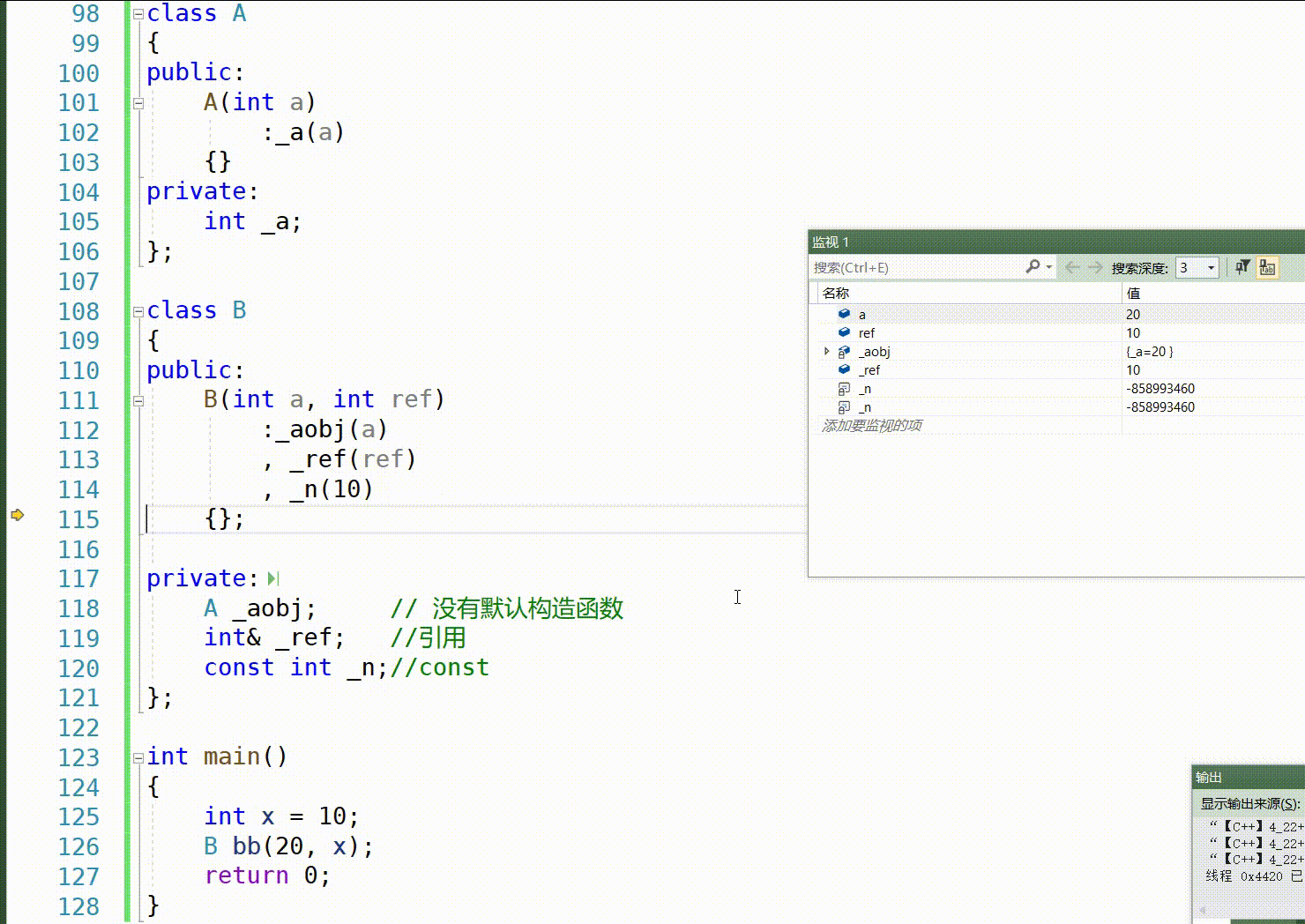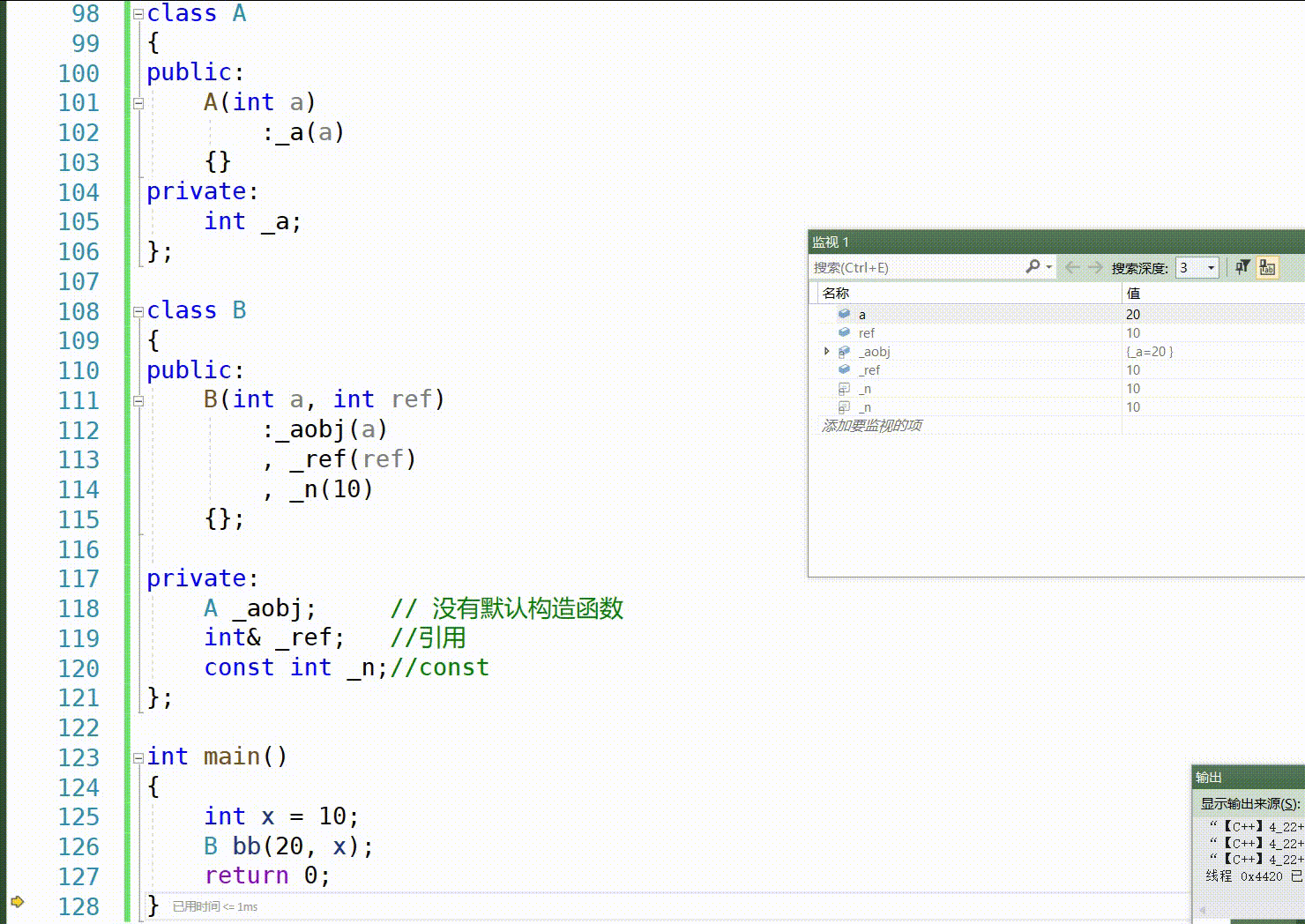
这里我们知道,对于 int、double、float 等内置类型的成员变量,如果没有在初始化列表中显式初始化,它们将被默认初始化,这个初始化编译器可能会初始化为0,但是默认初始化他其实是未定义的,有可能为0,也有可能为随机值。
对于自定义类类型的成员变量,如果没有在初始化列表中显式初始化,它们将使用该类的默认构造函数进行初始化。如果该类没有提供默认构造函数,则会出现编译错误。
我们知道_n和引用ref是通过初始化列表进行赋值的,因为是const和引用,只能在初始化列表初始化,但是而这些内置类型_year可以不使用初始化列表显示赋值,他们先进行默认初始化,然后再在构造函数体内进行_year = year; _month = month; _day = day;等赋值操作,那在赋值之前,他们的值是未定义的–》
class Date { public: Date(int year, int month, int day, int& refDay) : ref(refDay) , _x(1) { _year = year; _month = month; _day = day; } private: int _year; int _month; int _day; int& ref; const int _x; }; 而我们之前也学过一个在声明时使用的一个操作:给缺省值:
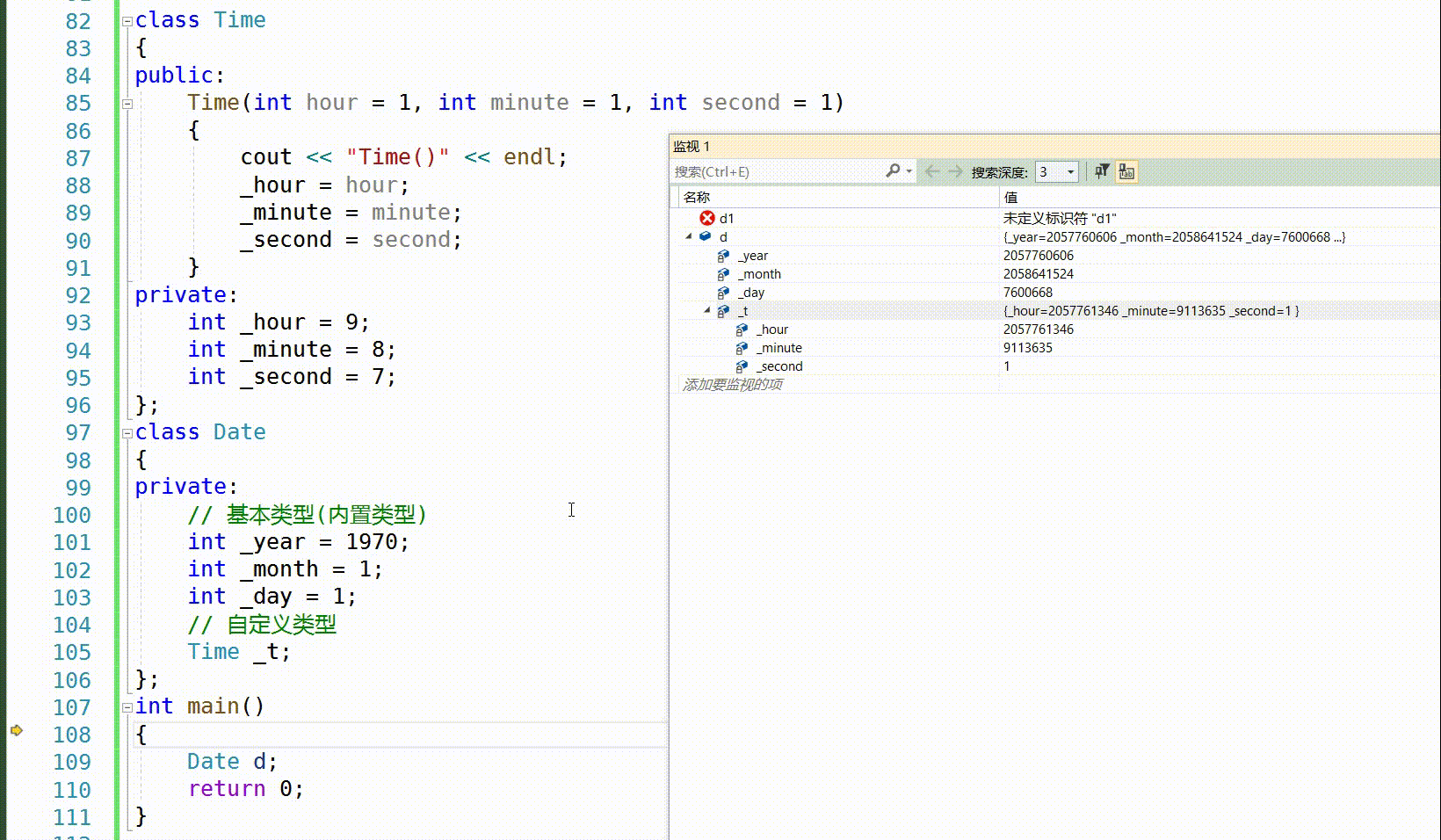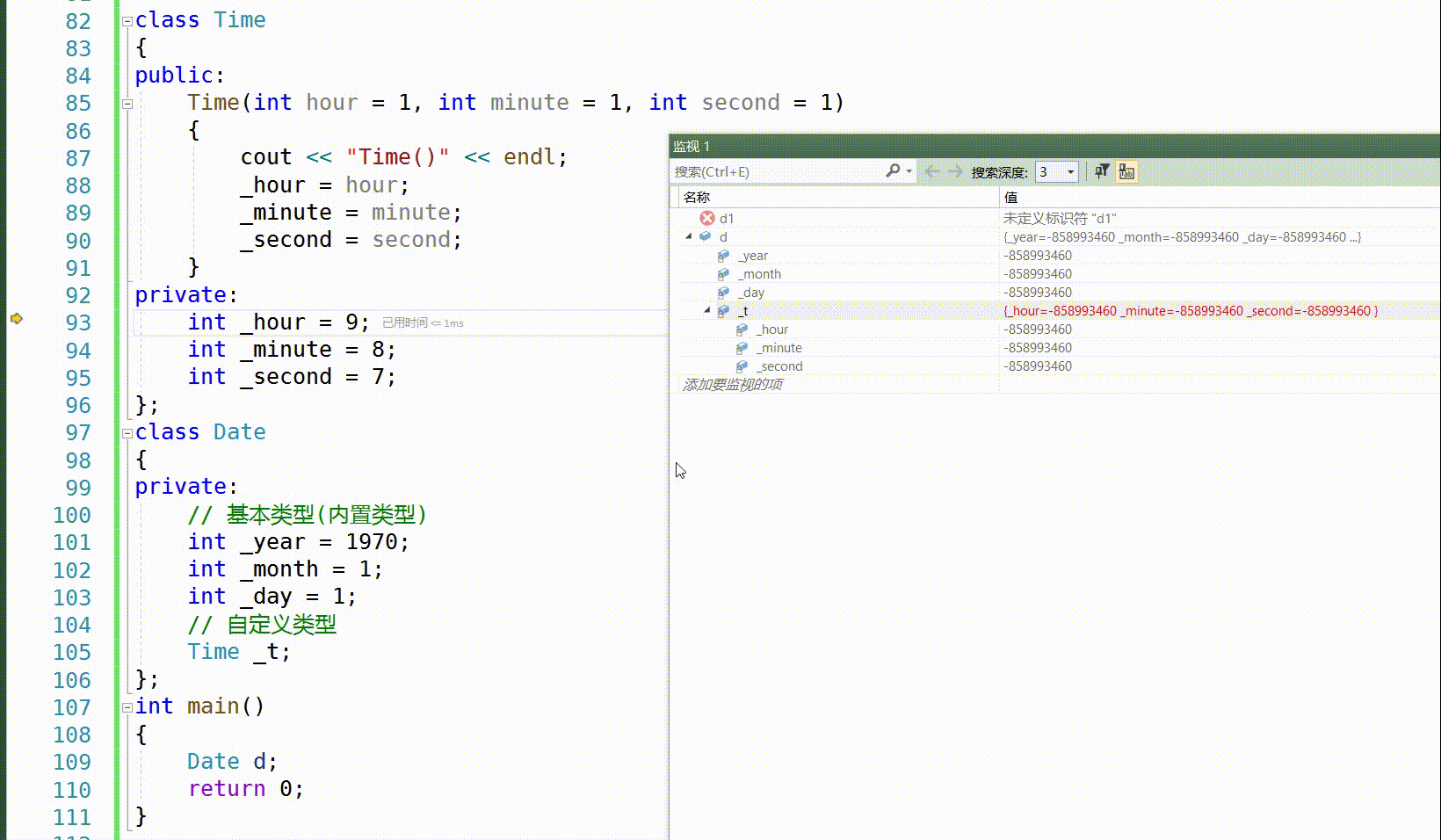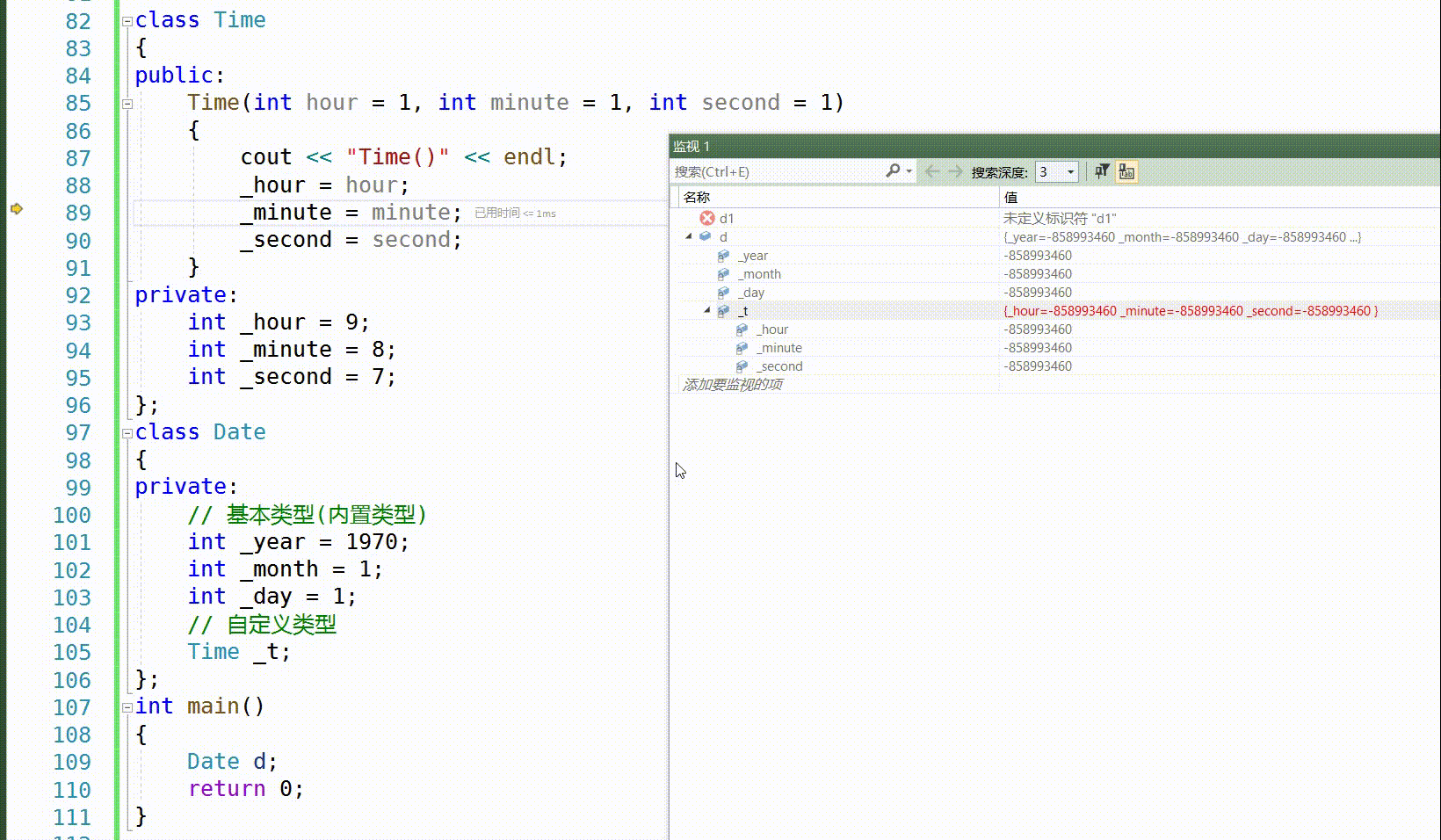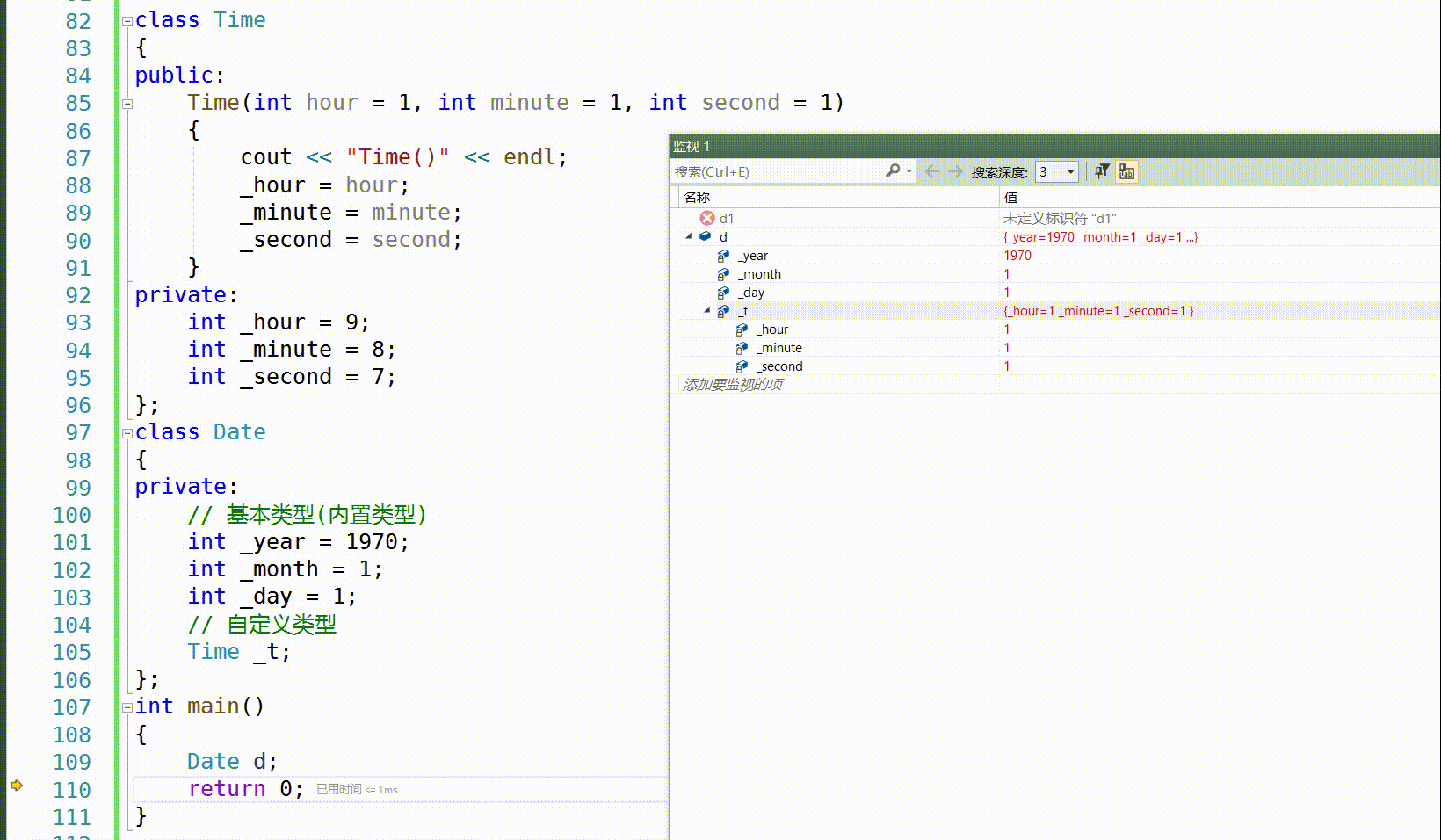
这里是我们熟悉的给缺省值,我们可以看到当进入对象里面时,我们先去找内置类型,然后给缺省值,当走完缺省值,他还会走一遍初始化列表,因为这上面没有写出初始化列表,那么我们调试看不出来,自定义先去找他的构造函数,如果没有就会报错,因此自定义类型的尽头还是内置类型,所以,这个缺省值是给初始化列表准备的,有缺省值,没有初始化化列表,就用缺省值来初始化列表,那两者都有呢,先走缺省值,然后再去按初始化列表,最终还是按照初始化列表来初始化。
总结一下就是:
- 初始化列表,不管你写不写,每个成员变量都会先走一遍
- 自定义类型的成员会调用默认构造(没有默认构造就编译错误)
- 内置类型有缺省值用缺省值,没有的话,不确定,要看编译器,有的编译器会报错
- 先走初始化列表 + 再走函数体
实践中:尽可能使用初始化列表初始化,不方便在使用函数体初始化
以下是调试代码,可以动手试试哦:
typedef int DataType; class Stack { public: Stack(size_t capacity = 4) { _array = (DataType*)malloc(sizeof(DataType) * capacity); if (NULL == _array) { perror("malloc申请空间失败!!!"); return; } _capacity = capacity; _size = 0; } void Push(DataType data) { // CheckCapacity(); _array[_size] = data; _size++; } // 其他方法... ~Stack() { if (_array) { free(_array); _array = NULL; _capacity = 0; _size = 0; } } private: DataType* _array; int _capacity; int _size; }; class MyQueue { public: // 初始化列表,不管你写不写,每个成员变量都会先走一遍 // 自定义类型的成员会调用默认构造(没有默认构造就编译报错) // 内置类型有缺省值用缺省值,没有的话,不确定,要看编译器,有的编译器会处理,有的不会处理 // 先走初始化列表 + 再走函数体 // 实践中:尽可能使用初始化列表初始化,不方便再使用函数体初始化 MyQueue() :_size(1) , _ptr((int*)malloc(40)) { memset(_ptr, 0, 40); } private: // 声明 Stack _pushst; Stack _popst; // 缺省值 给初始化列表用的 int _size = 0; const int _x = 10; int* _ptr; }; int main() { MyQueue q; return 0; } 尽量使用初始化列表初始化,因为不管你是否使用初始化列表,对于自定义类型成员变量,一定会先使用初始化列表初始化。
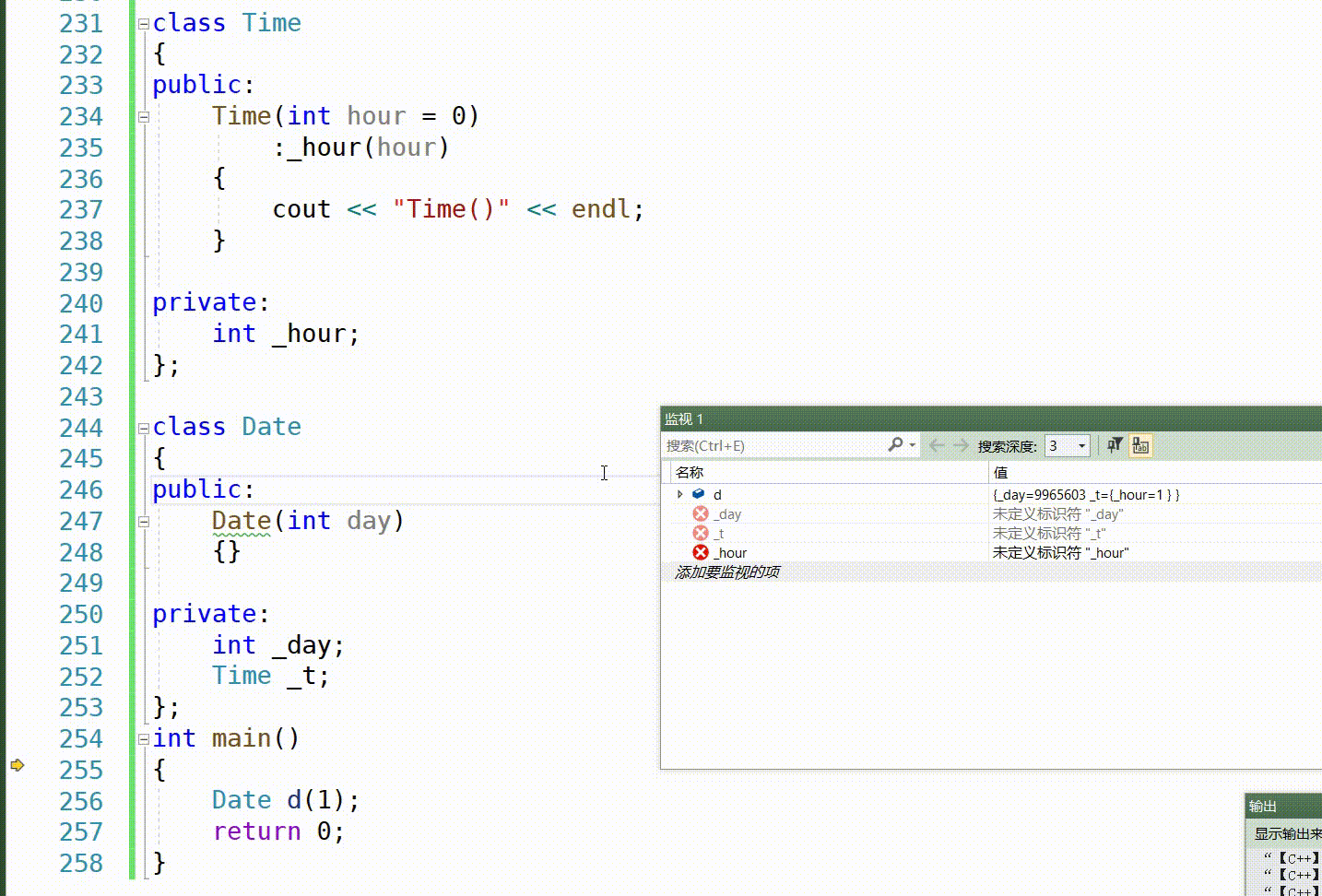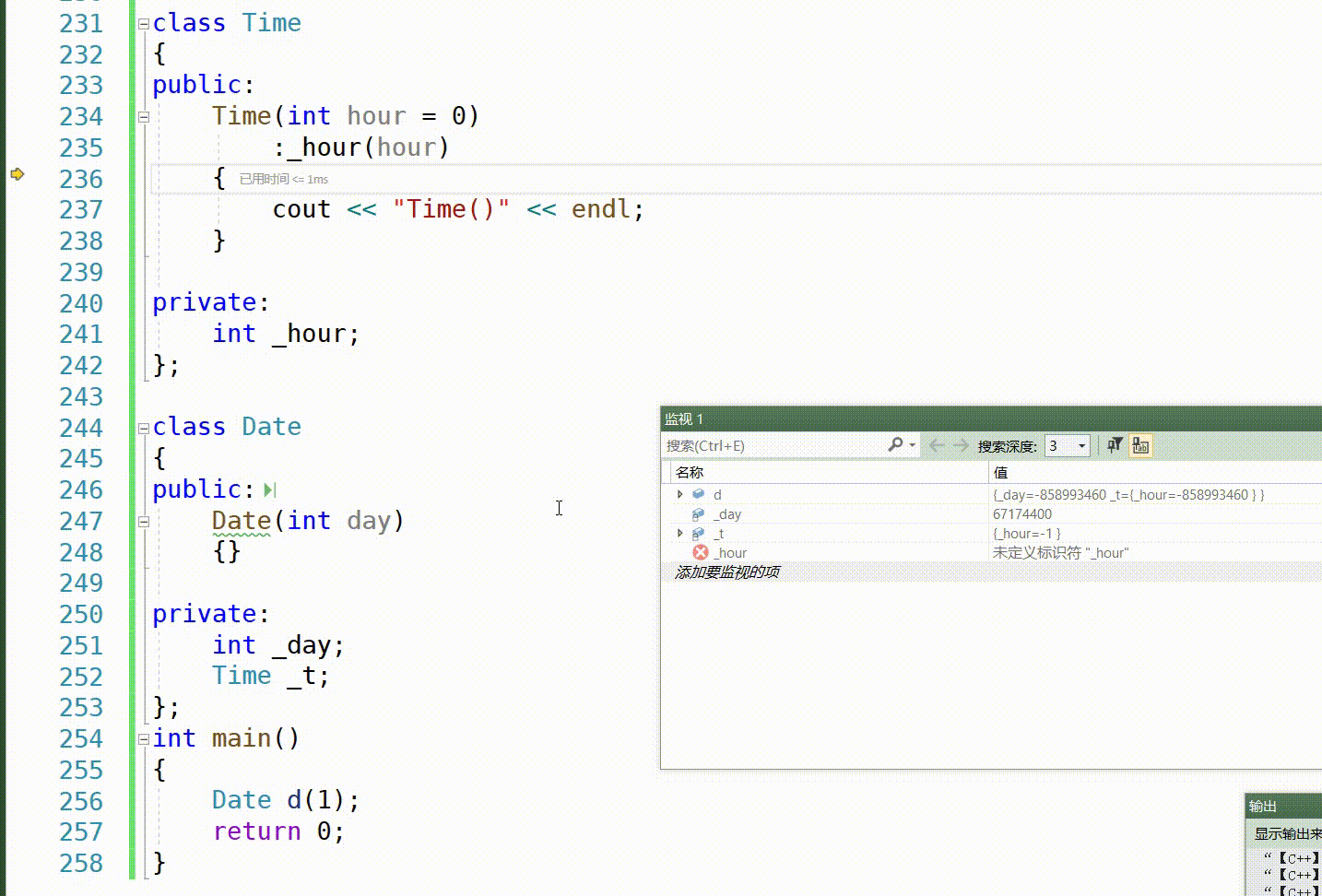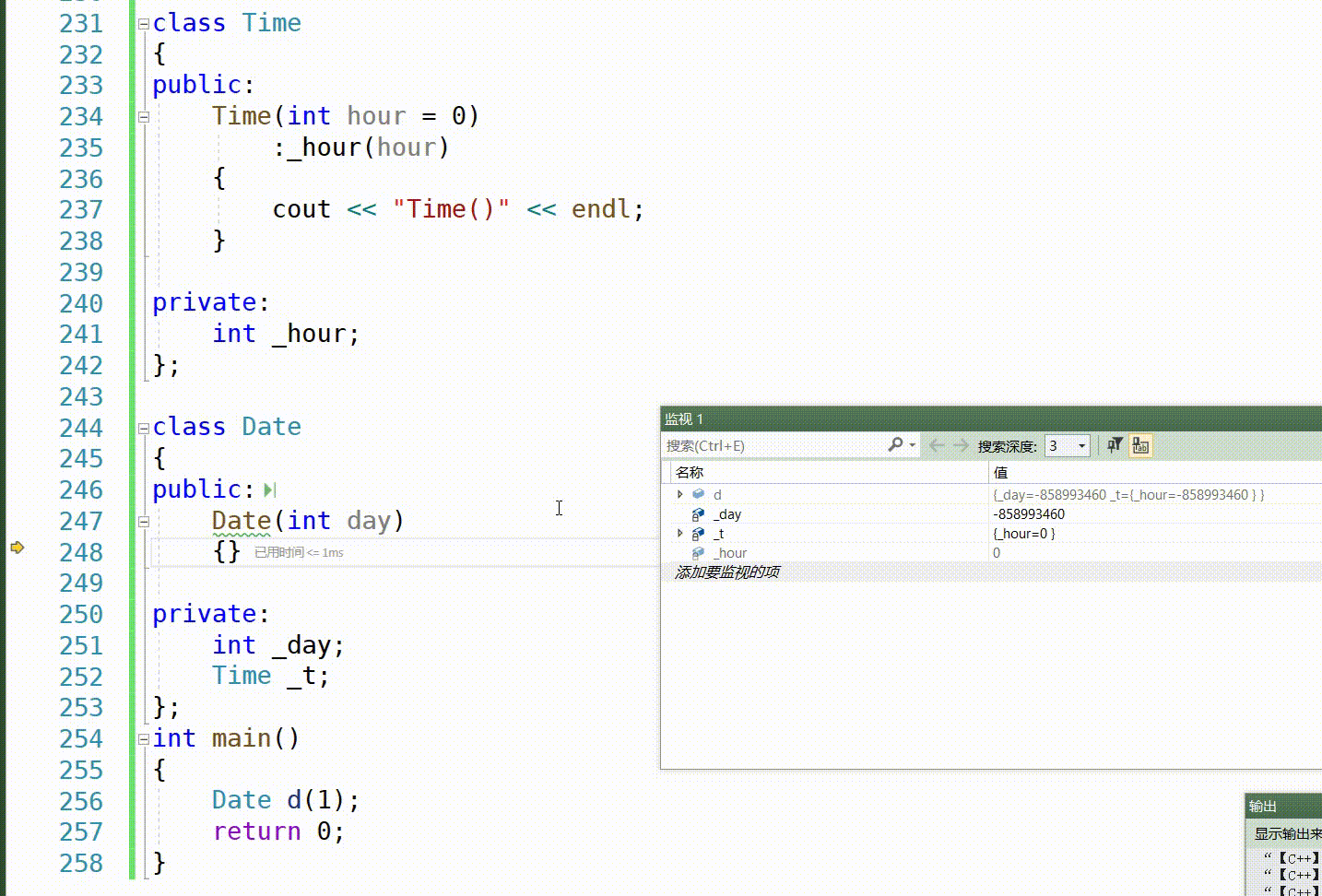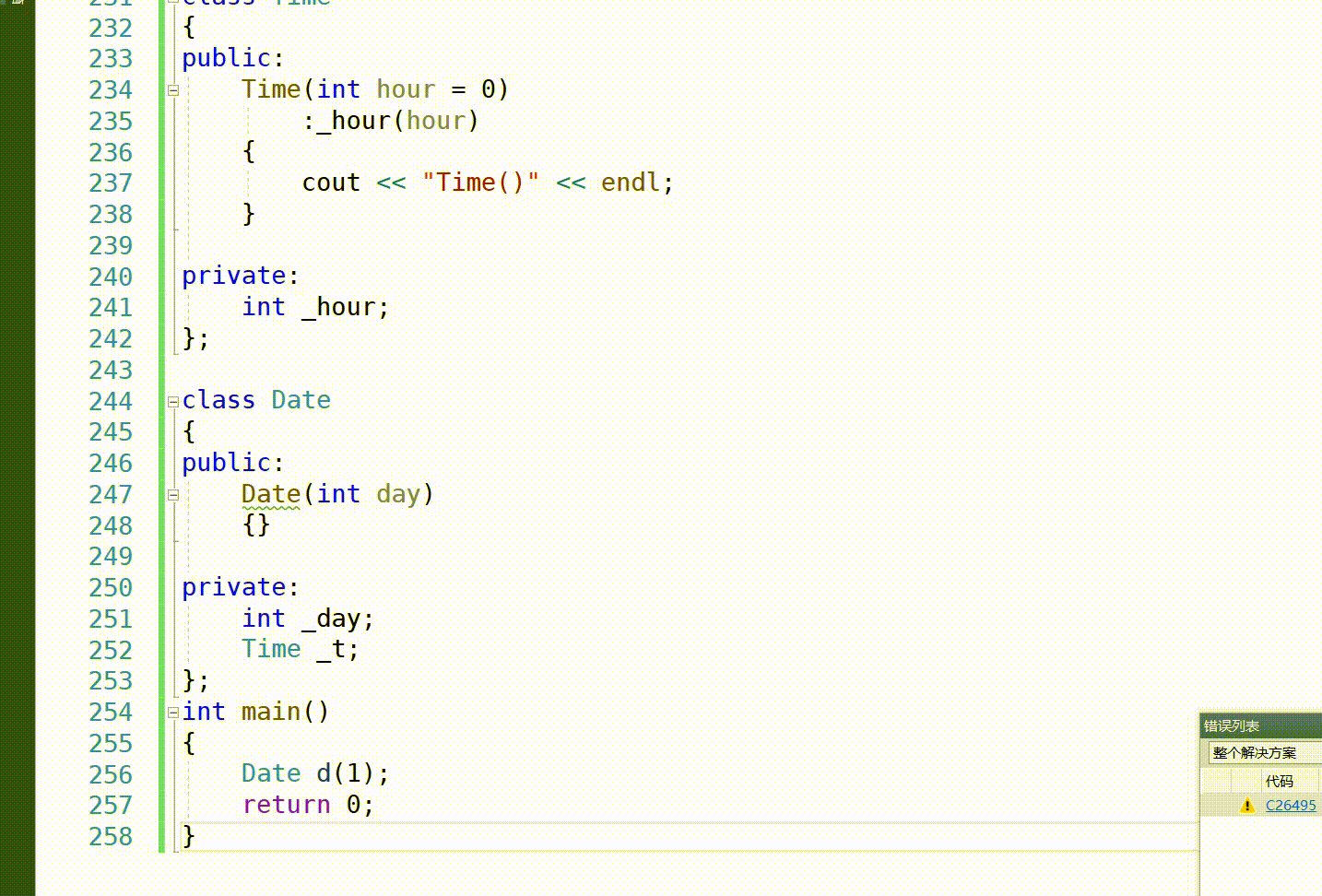
成员变量在类中声明次序就是其在初始化列表中的初始化顺序,与其在初始化列表中的先后次序无关
看看这个代码会出现什么情况:
class A { public: A(int a) :_a1(a) ,_a2(_a1) {} void Print() { cout << _a1 << " " << _a2 << endl; } private: int _a2; int _a1; }; int main() { A aa(1); aa.Print(); } A. 输出1 1 B.程序崩溃 C.编译不通过 D.输出1 随机值 正确答案是 D. 输出1 随机值。
在这个例子中, _a2 在 _a1 之后声明, 所以 _a2 会先被初始化。但在初始化 _a2 时, _a1 还没有被初始化, 所以 _a2 会被初始化为一个随机值。
当 Print() 函数被调用时, _a1 被正确初始化为 1, 但 _a2 被初始化为一个随机值, 因此输出结果会是 “1 随机值”。
所以, 这个程序不会崩溃也不会编译失败, 只是输出结果不是我们期望的。要解决这个问题, 可以调换 _a1 和 _a2 在初始化列表中的顺序, 或者在构造函数中手动初始化 _a2。
修改后的代码:
class A { public: A(int a) :_a1(a) ,_a2(_a1) {} void Print() { cout << _a1 << " " << _a2 << endl; } private: int _a1; int _a2; }; int main() { A aa(1); aa.Print(); } 运行截图: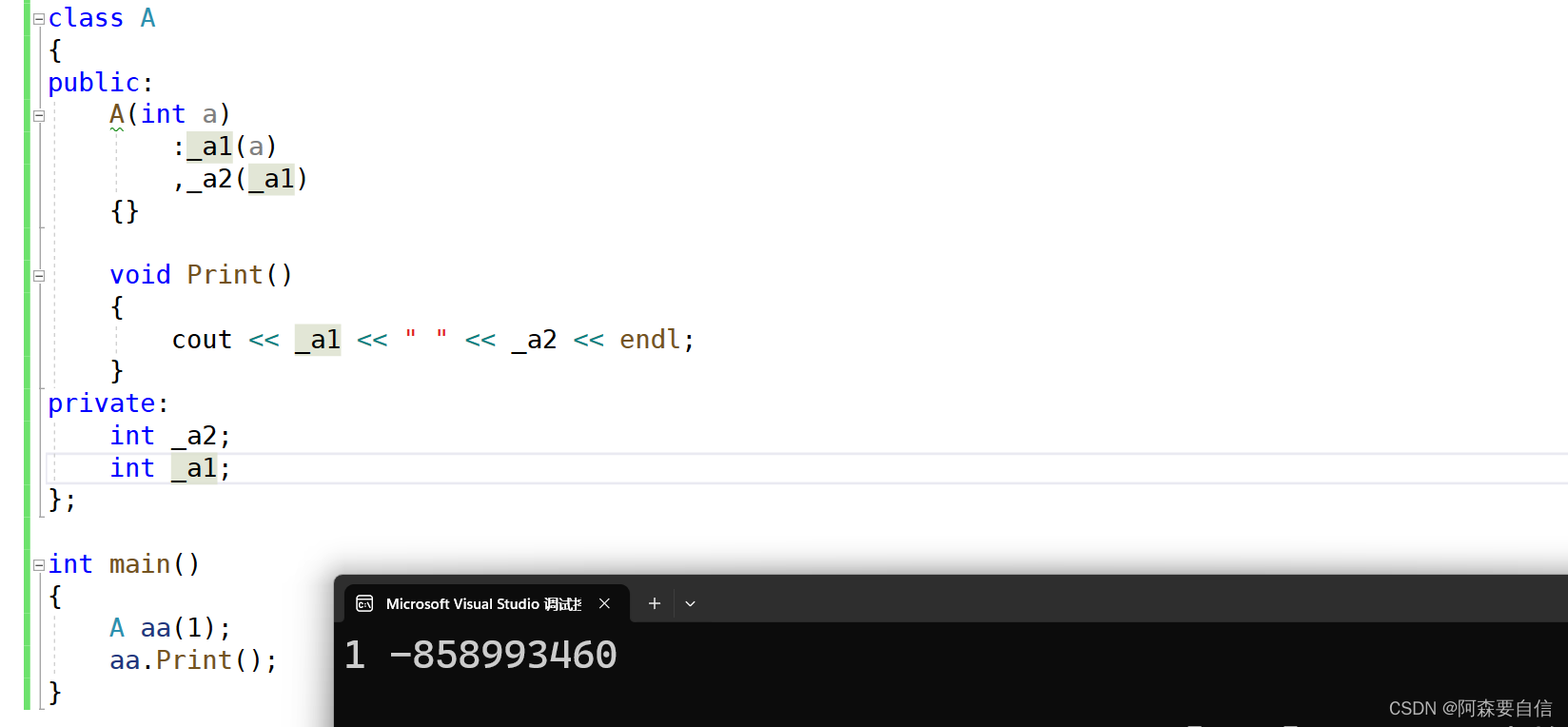
当使用成员初始化列表来初始化数据成员时,这些成员函数真正的初始化顺序并不一定与你在初始化列表中为他们安排的顺序一致,编译器总是按照他们在类中声明的次序来初始化的,因此,最好是按照他们的声明顺序来书写成员初始化列表:
- 调用基类的构造函数,向他们传递参数
- 初始化本类的数据成员(包括成员对象的初始化)
- 在函数体内完成其他的初始化工作
🌉初始化列表效率
class A { //... A(); //默认构造函数 A(const A& d); //拷贝构造函数 A& operator=(const A& d); //赋值函数 }; class B { public: B(const A& a); //B的成员对象 private: A m_a; //成员对象 }; (1)采用初始化列表的方式初始化
B::B(const A& a) :m_a(a) { ... } (2)采用函数体内赋值的方式初始化
B::B(const A& a) { m_a = a; ... } 本例第一种方式,类B的构造函数在其初始化列表里调用了类A的拷贝构造函数,从而将成员对象 m_a初始化。
本例第二种方式,类B的构造函数在函数体内用赋值的方式将成最对象a初始化。我们看到的只是一条赋值语句,但实际上 B 的构造函数干了两件事、先暗地里创建m_a对象(调用了 A 的默认构造函数),再调用类A的赋值函数,才将参囊。赋给 m_a。
显然第一种方式的效率比第二种高。
对于内部数据类型的数据成员而言,两种初始化方式的效率几乎没有区别,
🌠隐式类型转换
看看小类A:
class A { public: A(int a) :_a(a) { cout << "A(int a)" << endl; } private: int _a; }; int main() { A aa1(1); //拷贝构造 A aa2 = aa1; A aa3 = 3; return 0; } 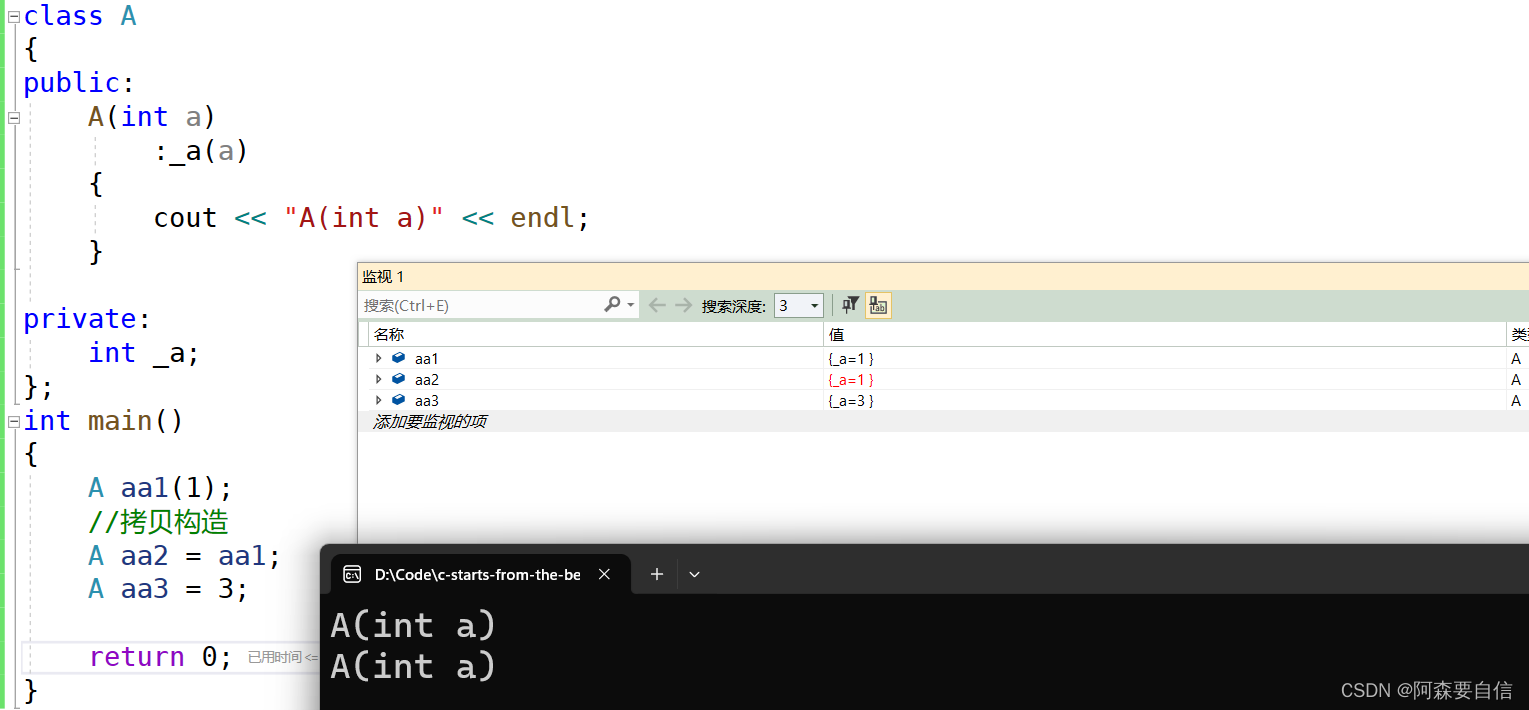
- 这个代码把1作为参数调用构造函数,创建aa1对象。
A aa1(1); - 在代码中,这个代码为啥能直接赋值?
A aa3 = 3; 在这个代码中,A aa3 = 3;能够直接赋值是因为发生了隐式类型转换。
在 A 类中,有一个接受 int 类型参数的构造函数 A(int a), 在 main() 函数中,A aa3 = 3; 是一个复制初始化的过程,编译器在执行复制初始化时,会尝试将右侧的 3 隐式转换为 A 类型,由于 A 类有一个接受 int 类型参数的构造函数,编译器会自动调用这个构造函数,将 3 转换为 A 类型的对象 aa3。
🌉复制初始化
复制初始化(copy initialization)是 C++ 中一种常见的初始化方式,它指的是使用等号(=)来初始化一个变量。
复制初始化的过程如下:
- 首先,编译器会尝试将等号右侧的表达式转换为左侧变量的类型。
- 如果转换成功,则使用转换后的值来初始化左侧变量。
- 如果转换失败,则编译器会尝试调用类的拷贝构造函数来初始化左侧变量。
例如:
A aa1(1); // 直接初始化 A aa2 = aa1; // 复制初始化,调用拷贝构造函数 A aa3 = 3; // 复制初始化,调用 A(int) 构造函数进行隐式转换 A aa1(1)是直接初始化,调用的是A(int)构造函数。A aa2 = aa1是复制初始化,调用的是拷贝构造函数。A aa3 = 3也是复制初始化,但是由于A类有一个接受int类型参数的构造函数,所以编译器会自动将3转换为A类型,然后调用该构造函数来初始化aa3。
编译器遇到连续构造+拷贝构造->优化为直接构造,C++ 编译器的一种常见优化技巧,称为"构造+拷贝构造优化"。
在某些情况下,编译器可以识别出连续的构造和拷贝构造操作,并将其优化为单次直接构造。这种优化可以提高程序的性能,减少不必要的拷贝操作。
class A { public: A(int a) :_a(a) { cout << "A(int a)" << endl; } A(const A& aa) :_a(aa._a) { cout << "A(const A& aa)" << endl; } private: int _a; }; int main() { A aa1(1); A aa3 = 3; return 0; } 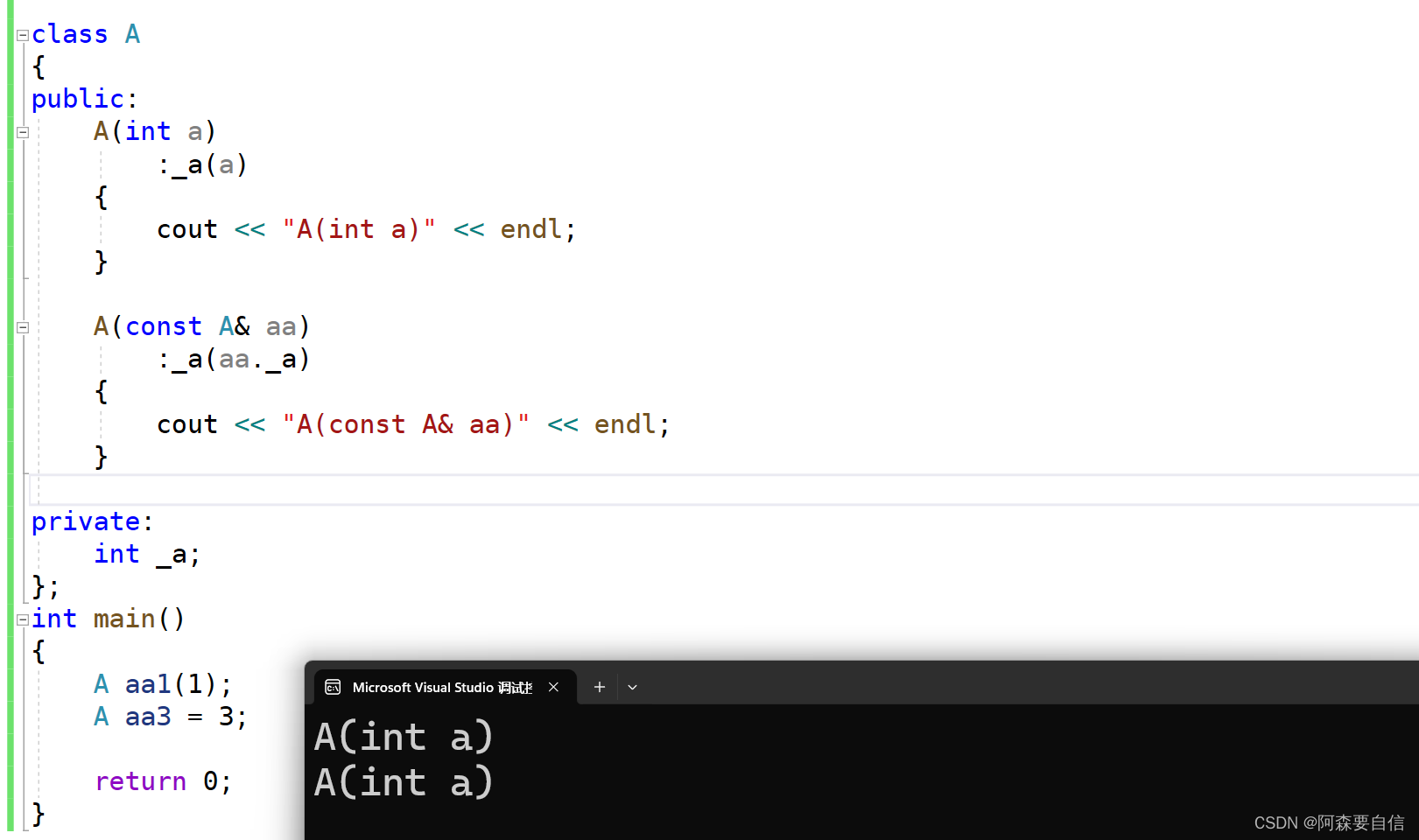
在语句 A aa3 = 3; 中,编译器会进行优化,将连续的构造和拷贝构造操作优化为单次直接构造。
编译器首先会调用 A(int a) 构造函数,使用字面量 3 创建一个临时 A 对象,通常情况下,这个临时对象应该被拷贝到 aa3 变量中。但是,聪明的编译器可以识别出这种模式,并将其优化为直接在 aa3 变量的位置上构造一个 A 对象。因此,编译器会直接调用 A(int a) 构造函数,在 aa3 变量的位置上构造一个 A 对象,省略了中间的拷贝步骤。
所以,在这个例子中,输出结果应该是:
A(int a) 只会输出一次 A(int a),而不会输出 A(const A& aa) 表示拷贝构造函数的调用。
这种优化技巧可以提高程序的性能,因为它减少了不必要的拷贝操作。编译器会自动进行这种优化,开发者无需手动进行。这是 C++ 编译器常见的一种性能优化手段。
因此编译器遇到连续构造+拷贝构造->优化为直接构造
🌠单多参数构造函数
class A { public: A(int a) :_a(a) { cout << "A(int a)" << endl; } private: int _a; }; int main() { A& raa = 3; return 0; } 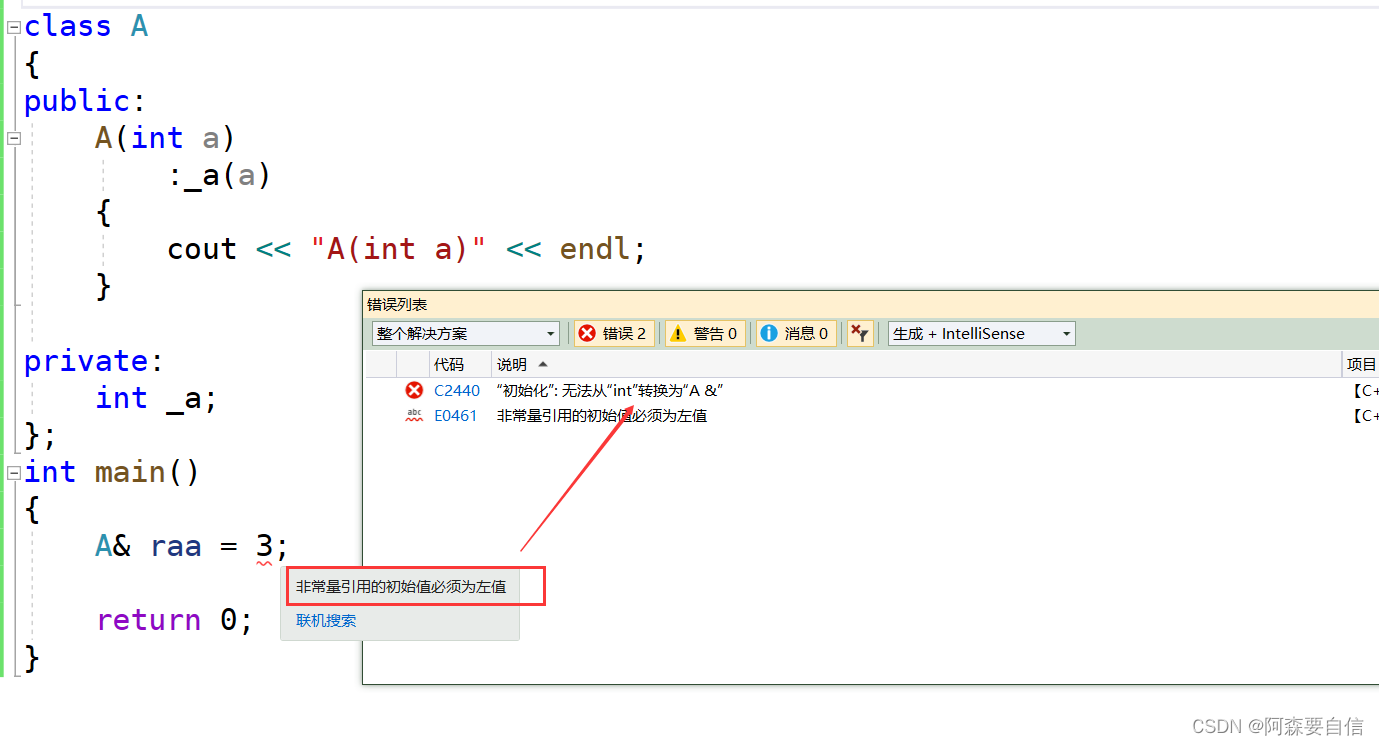
在代码 A& raa = 3; 中,编译器无法进行隐式转换,因为不能从 int 类型直接转换为 A& 类型的引用。
这里发生的问题是:
- 编译器试图将字面量
3绑定到A&类型的引用raa上,因为3是常量,具有常性,相当于有了const,而我们知道从常性到正常无常性的转换,不就等于权限的放大,权限的放大将不会发生转换。
正确的做法应该是:
A aa(3); A& raa = aa; 或者:
A aa = 3; A& raa = aa; 在这两种情况下,编译器都能找到合适的构造函数来创建 A 对象,然后再将引用绑定到该对象上。
这样写的是对的,但是不方便,我们可以直接加const
const A& raa = 3; //或者 const A& raa = aa(3); 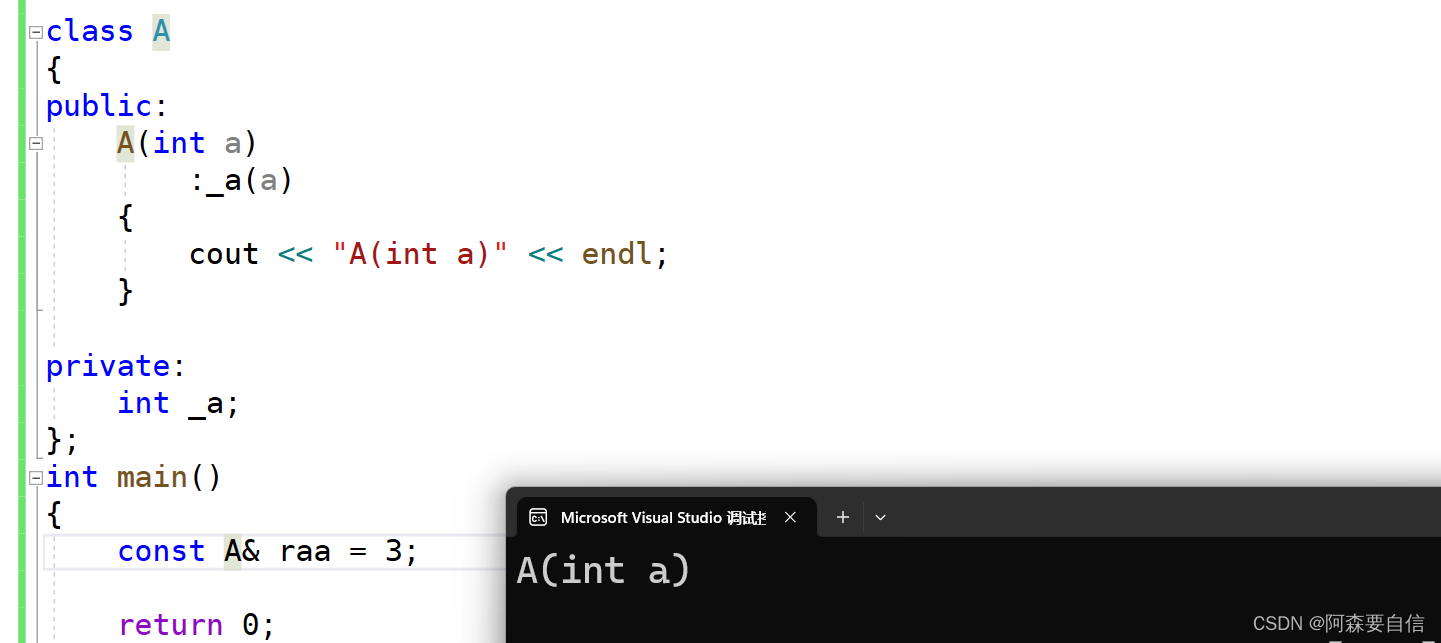
此时此刻,两行可以写成一行,这下就方便了
class Stack { public: void Push(const A& aa) { //... } //... }; int main() { Stack st; A a1(1); st.Push(a1); A a2(2); st.Push(a2); //可以直接写 st.Push(2); st.Push(4); return 0; } 或者声明了一个名为lt的list,向列表中添加元素:
#include #include int main() { list lt; // 第一种写法: string s1("111"); lt.push_back(s1); //第二种写法 lt.push_back("1111"); return 0; }
这是单参数构造函数,以下是多参数构造函数
//多参数构造函数 A(int a1, int a2) :_a(0) ,_a1(a1) ,_a2(a2) {} A aaa1(1, 2); A aaa2 = { 1, 2 }; const A& aaa3 = { 1, 2 }; 🌉explicit关键字
构造函数不仅可以构造与初始化对象,对于接收单个参数的构造函数,还具有类型转换的作用。接收单个参
数的构造函数具体表现:
- 构造函数只有一个参数
- 构造函数有多个参数,除第一个参数没有默认值外,其余参数都有默认值
- 全缺省构造函数
class Date { public: // 1. 单参构造函数,没有使用explicit修饰,具有类型转换作用 // explicit修饰构造函数,禁止类型转换---explicit去掉之后,代码可以通过编译 explicit Date(int year) :_year(year) {} /* // 2. 虽然有多个参数,但是创建对象时后两个参数可以不传递,没有使用explicit修饰,具有类型转 换作用 // explicit修饰构造函数,禁止类型转换 explicit Date(int year, int month = 1, int day = 1) : _year(year) , _month(month) , _day(day) {} */ Date& operator=(const Date& d) { if (this != &d) { _year = d._year; _month = d._month; _day = d._day; } return *this; } private: int _year; int _month; int _day; }; void Test() { Date d1(2022); // 用一个整形变量给日期类型对象赋值 // 实际编译器背后会用2023构造一个无名对象,最后用无名对象给d1对象进行赋值 d1 = 2023; // 将1屏蔽掉,2放开时则编译失败,因为explicit修饰构造函数,禁止了单参构造函数类型转换的作 用 } 上述代码可读性不是很好,用explicit修饰构造函数,将会禁止构造函数的隐式转换。
🚩总结
