利用R语言进行聚类分析实战(数据+代码+可视化+详细分析)
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
- 1 研究目的
- 2 数据背景
- 3 案例演示
- 3.1 读取数据
- 3.2 按样本聚类
- 3.2.1 最短距离法
- 3.2.2 最长距离法
- 3.2.3 中间距离法
- 3.2.4 类平均法
- 3.2.5 重心法
- 3.2.6 离差平方和法
- 3.2.7 K-means快速聚类法
- 3.2.8 样本聚类总结
- 3.3 按变量聚类
- 3.3.1 最短距离法
- 3.3.2 最长距离法绘制树状聚类图
- 3.3.3 中间距离法
- 3.3.4 类平均法
- 3.3.5 重心法
- 3.3.6 离差平方和法
- 3.3.7 K-means快速聚类法
- 3.3.8 变量聚类总结
1 研究目的
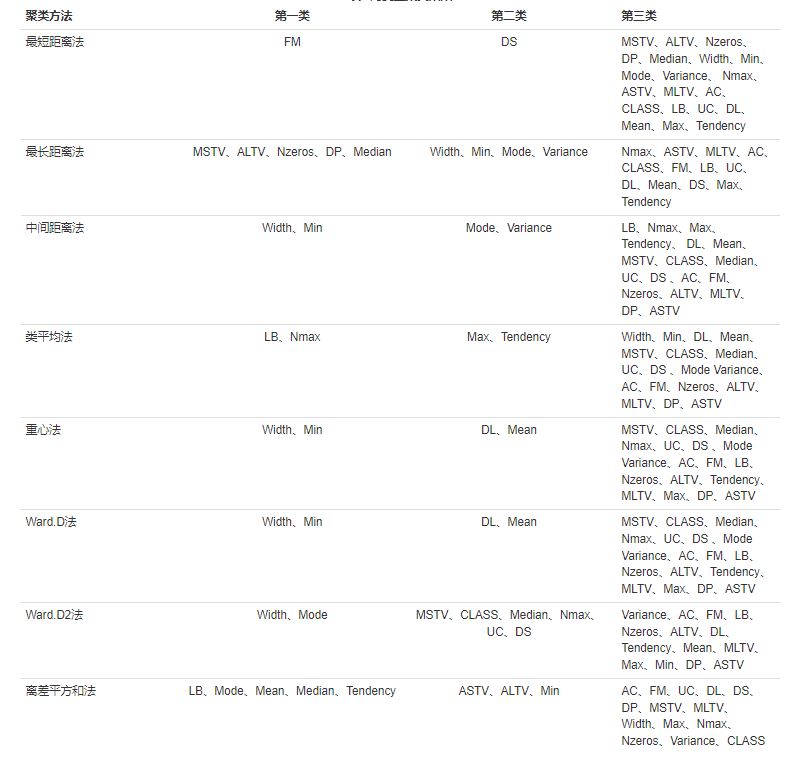
对来源于Frank and Asuncion (2010)胎心宫缩监护(cardiotocography, CTG) 数据(CTG.xls)分别使用最短距离法、最长距离法、类平均法、重心法、离差平方和法(Ward.D、Ward.D2)、K-means法进行按样本聚类和按变量聚类。
2 数据背景
胎心宫缩监护(cardiotocography, CTG) 数据(CTG.xls)。这组数据来源于Frank and Asuncion (2010)。该数据有2129 个观测值及23个变量,包含了致命心律(fetal heart rate, FHR)的各种度量以及基于监护记录的由专家分类的宫缩(uterine contraction, UC) 特征.这些变量的情况列示于下表. 表中最后三个分类变量的水平为:Tendency(FHR 直方图的趋势)有三个水平 (-1 = 左不对称, 0=对称, 1= 右不对称);CLASS(FHR 分类代码) 用1~10 表示从平静睡眠到可疑10种活动状况;NSP(胎儿状态分类代码) 有三个水平(1= 正常, 2= 疑似, 3= 病态)。删去3 个有不少缺失值的观测值, 形成新的数据文件ctg.naomit.csv。舍弃第23 个变量NSP, 用前面22个变量进行聚类分析。
根据数据文件显示:NSP共有三个水平(1= 正常, 2= 疑似, 3= 病态),故本文聚类过程中共分为三类。
3 案例演示
3.1 读取数据
运行程序:
data<-read.csv("G:\\ctg.naomit.csv") #数据读取 data1<-data[c(1:2126),c(1:22)] #选取数据 3.2 按样本聚类
3.2.1 最短距离法
运行程序:
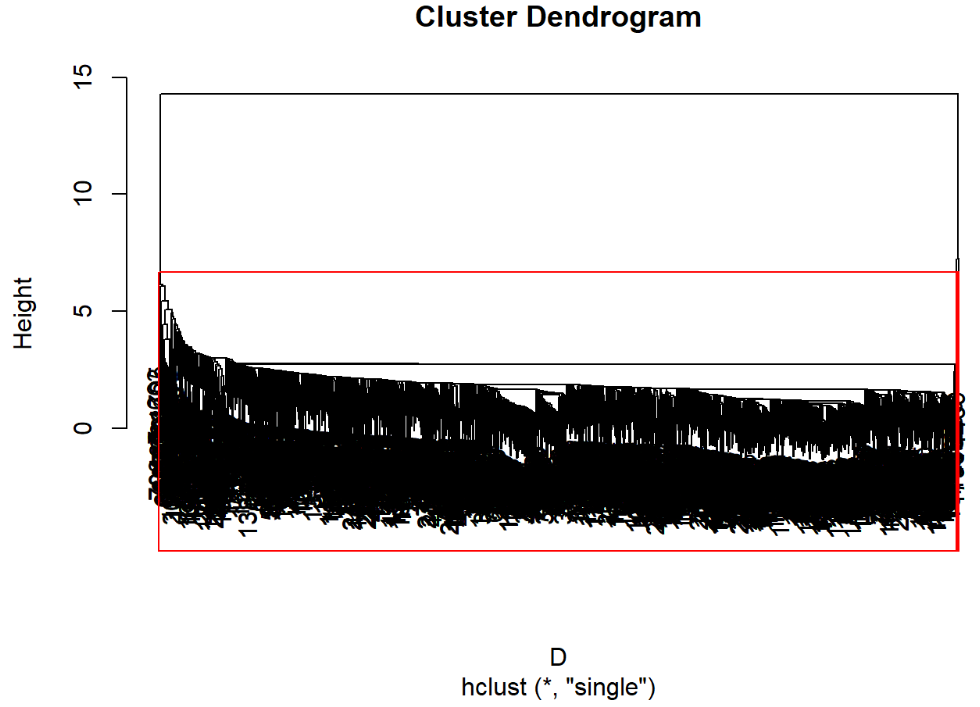
library(MASS) #加载包 data2=scale(data1) #标准化 D=dist(data2) #计算距离 plot(hclust(D,"single")) #最短距离法绘制树状聚类图 hc=hclust(D,"single") #计算新类与当前各类距离 head(data.frame(hc$merge,hc$height)) #显示前六行数据 运行结果:
## X1 X2 hc.height ## 1 -68 -69 0 ## 2 -230 -788 0 ## 3 -234 -235 0 ## 4 -305 -307 0 ## 5 -324 -325 0 ## 6 -327 -334 0 运行程序:
rect.hclust(hclust(D,"single"),3) #加三分类框 运行结果:
3.2.2 最长距离法
运行程序:
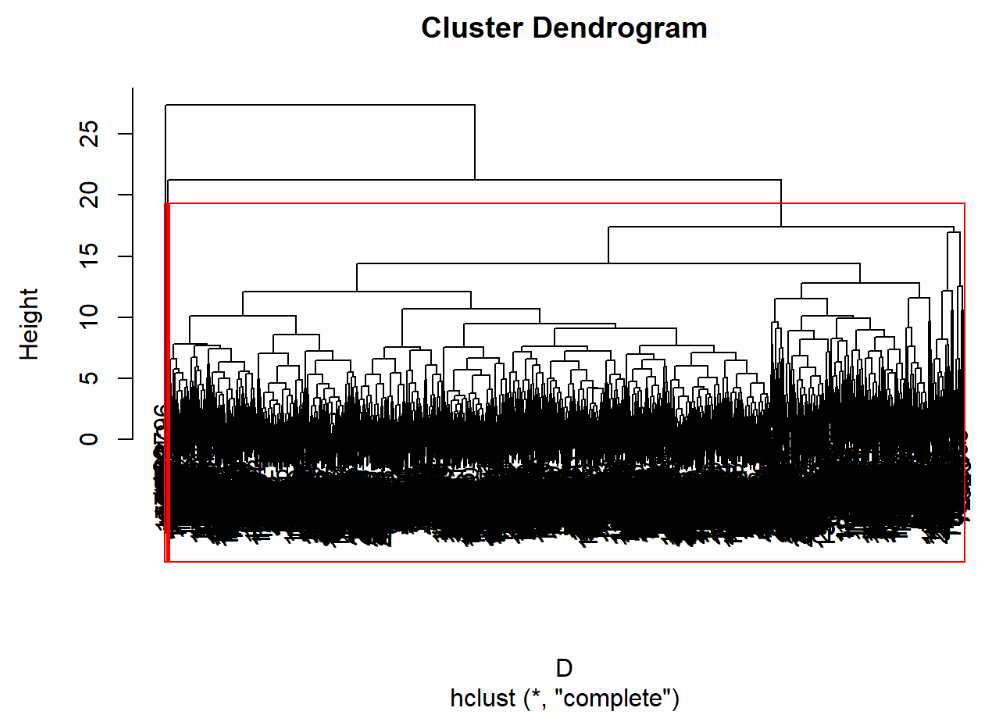
hc=hclust(D,"complete") #计算新类与当前各类距离 head(data.frame(hc$merge,hc$height)) #显示前六行数据 运行结果:
## X1 X2 hc.height ## 1 -68 -69 0 ## 2 -230 -788 0 ## 3 -234 -235 0 ## 4 -305 -307 0 ## 5 -324 -325 0 ## 6 -327 -334 0 运行程序:
plot(hc) #绘制树状聚类图 rect.hclust(hc,3) #加三分类框 运行结果:
3.2.3 中间距离法
运行程序:
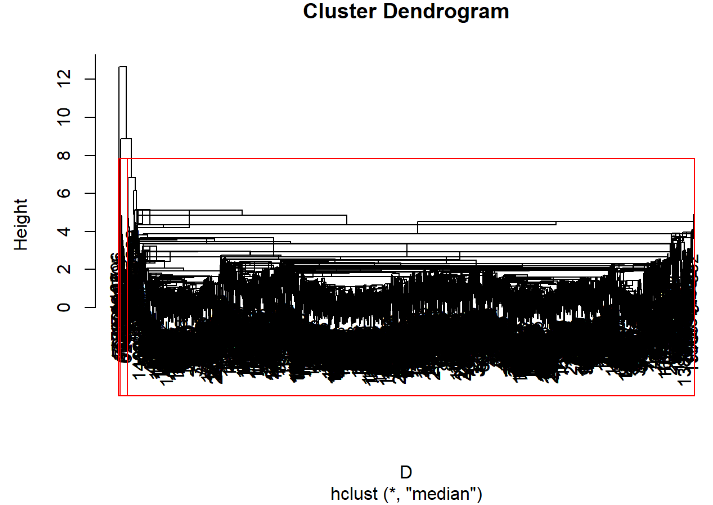
hc=hclust(D,"median") #计算新类与当前各类距离 head(data.frame(hc$merge,hc$height)) #显示前六行数据 运行结果:
## X1 X2 hc.height ## 1 -68 -69 0 ## 2 -230 -788 0 ## 3 -234 -235 0 ## 4 -305 -307 0 ## 5 -324 -325 0 ## 6 -327 -334 0 运行程序:
plot(hc) #绘制树状聚类图 rect.hclust(hc,3) #加三分类框 运行结果:
3.2.4 类平均法
运行程序:
hc=hclust(D,"average") #计算新类与当前各类距离 head(data.frame(hc$merge,hc$height)) #显示前六行数据 运行结果:
## X1 X2 hc.height ## 1 -68 -69 0 ## 2 -230 -788 0 ## 3 -234 -235 0 ## 4 -305 -307 0 ## 5 -324 -325 0 ## 6 -327 -334 0 运行程序:
plot(hc) #绘制树状聚类图 rect.hclust(hc,3) #加三分类框 运行结果:
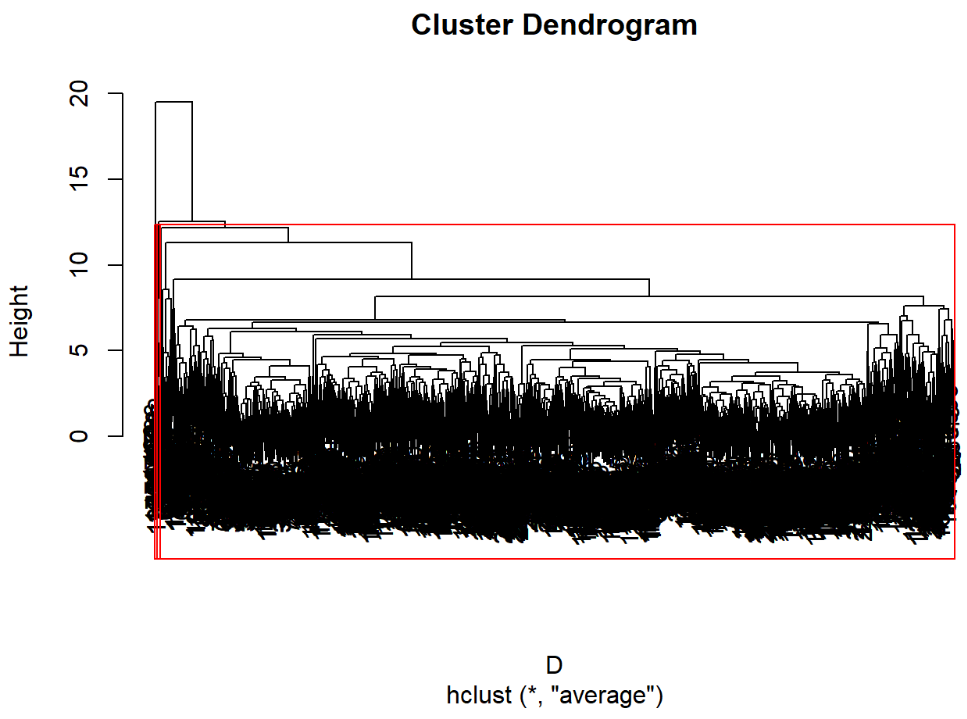
3.2.5 重心法
运行程序:
hc=hclust(D,"centroid") #计算新类与当前各类距离 head(data.frame(hc$merge,hc$height)) #显示前六行数据 运行结果:
## X1 X2 hc.height ## 1 -68 -69 0 ## 2 -230 -788 0 ## 3 -234 -235 0 ## 4 -305 -307 0 ## 5 -324 -325 0 ## 6 -327 -334 0 运行程序:
plot(hc) #绘制树状聚类图 rect.hclust(hc,3) #加三分类框 运行结果:
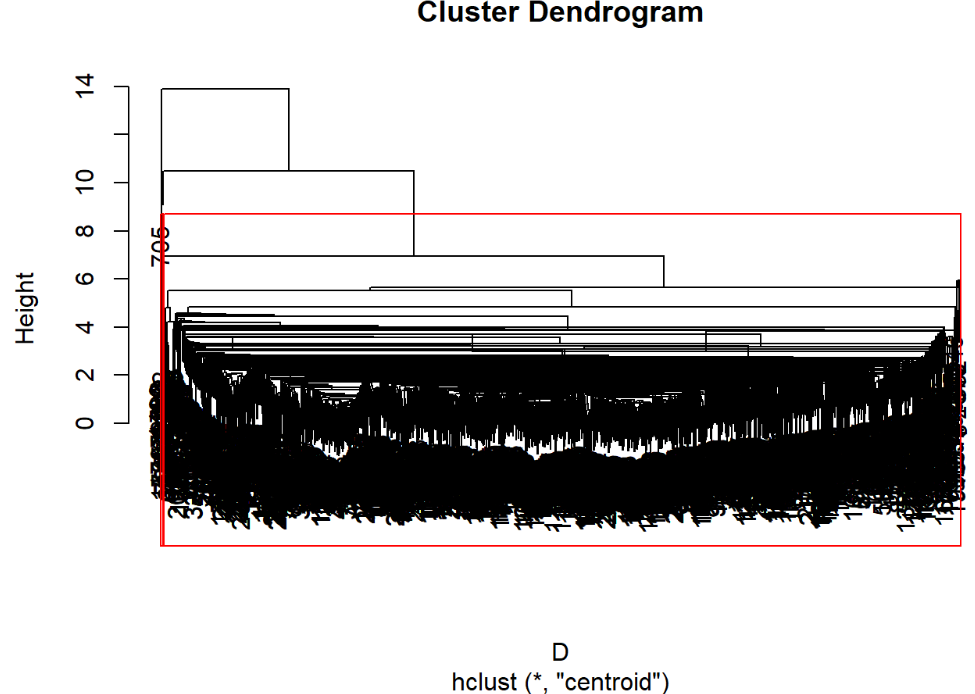
3.2.6 离差平方和法
1.ward.D法
运行程序:
plot(hclust(D,"ward.D")) #绘制树状聚类图 rect.hclust(hclust(D,"ward.D"),3) #加三分类框 运行结果:
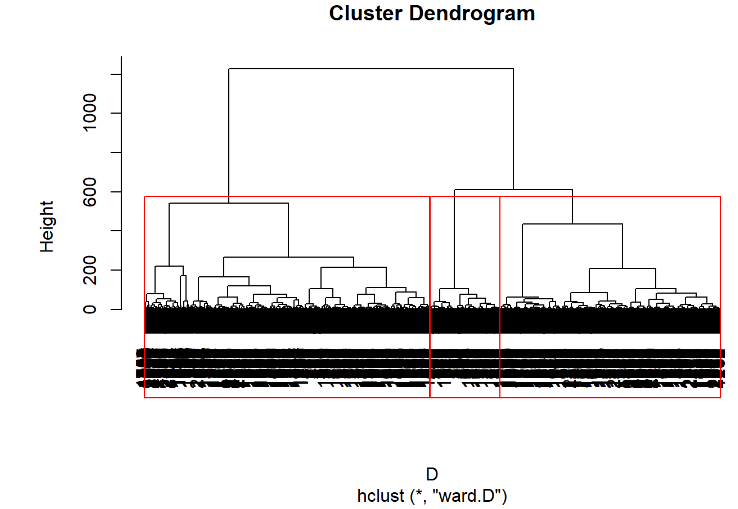
2.ward.D2法
运行程序:
plot(hclust(D,"ward.D2")) #离差平方和 rect.hclust(hclust(D,"ward.D2"),3) #加三分类框 运行结果:
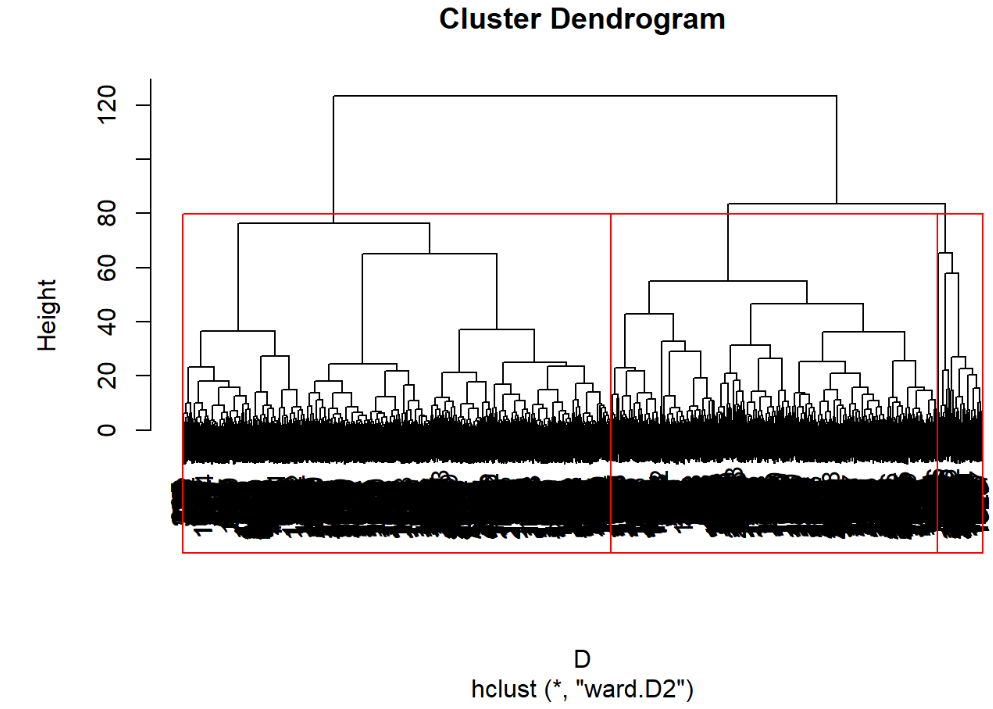
3.2.7 K-means快速聚类法
由于K-means聚类法不适用于分类属性变量的聚类,故选取前20个变量进行K-means聚类。
运行程序:
km=kmeans(data2[,1:20],3) plot(data2,pch=km$cluster,col=km$cluster) 运行结果:
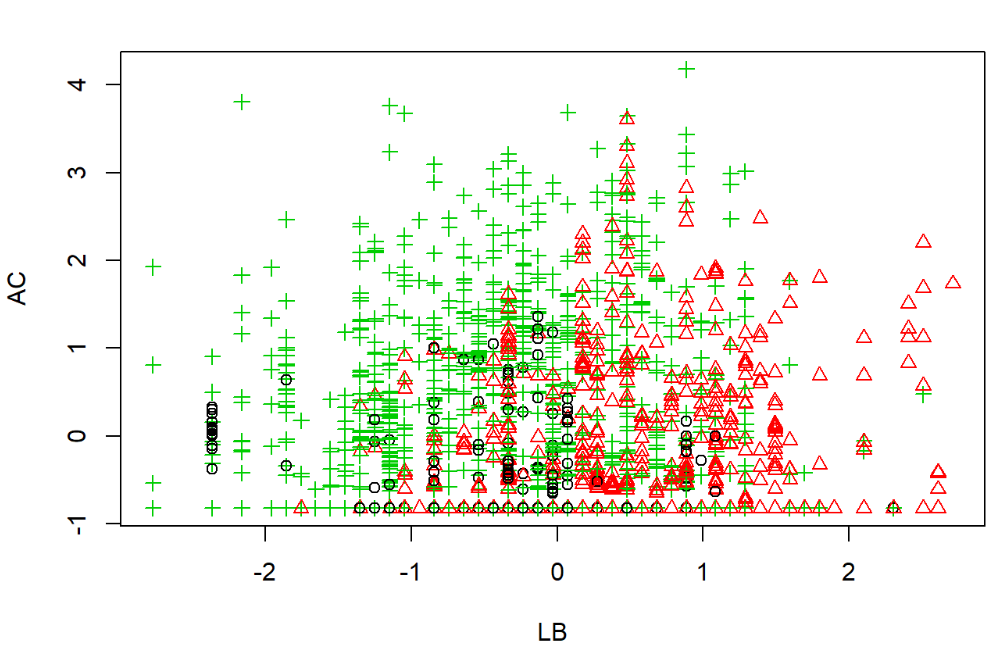
3.2.8 样本聚类总结
首先选取数据前22个变量的样本数据,为消除量纲的影响对数据进行标准化;再对样本分别进行最短距离、最长距离、中间距离、类平均、重心、离差平方和、Kmean法进行样本聚类,但由于样本量较大,导致数据显示结果较为混乱,从不同的系统聚类法中可以看出离差平方和法相较于其他系统聚类方法进行聚类结果分类更为明显。在K-mean快速聚类法中,由于K-mean聚类对分类属性的数据不适用,所以考虑去除变量Tendency、CLASS,然后进行K-mean快速聚类,将3类结果以不同颜色和形状呈现,具有较强观赏性。
3.3 按变量聚类
3.3.1 最短距离法
运行程序:
d=data.frame(cor(data2)) #计算各变量相似系数 D1=as.dist(d) #计算各变量距离 hc1=hclust(D1,method = "single") #最短距离法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
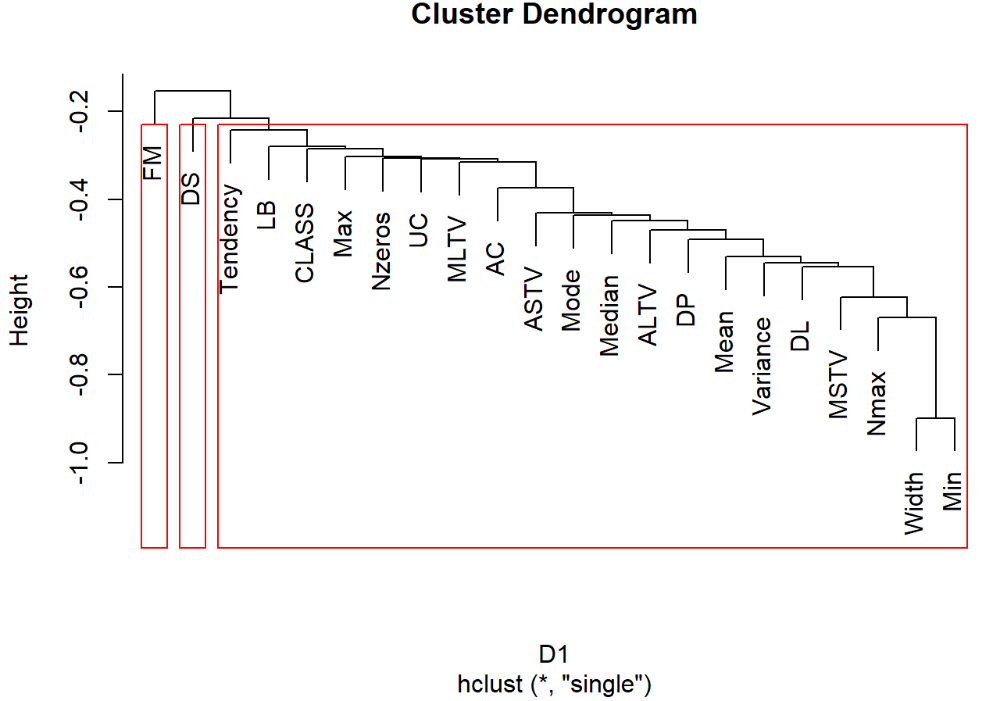
3.3.2 最长距离法绘制树状聚类图
运行程序:
hc1=hclust(D1,method = "complete") #最长距离法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
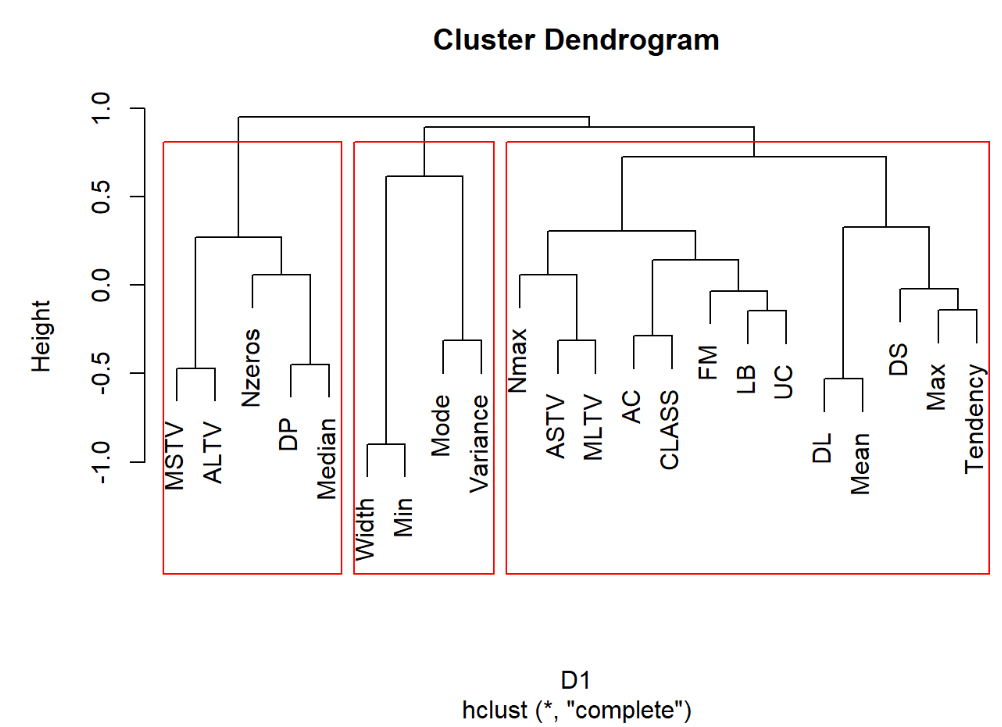
3.3.3 中间距离法
运行程序:
hc1=hclust(D1,method = "median") #中间距离法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
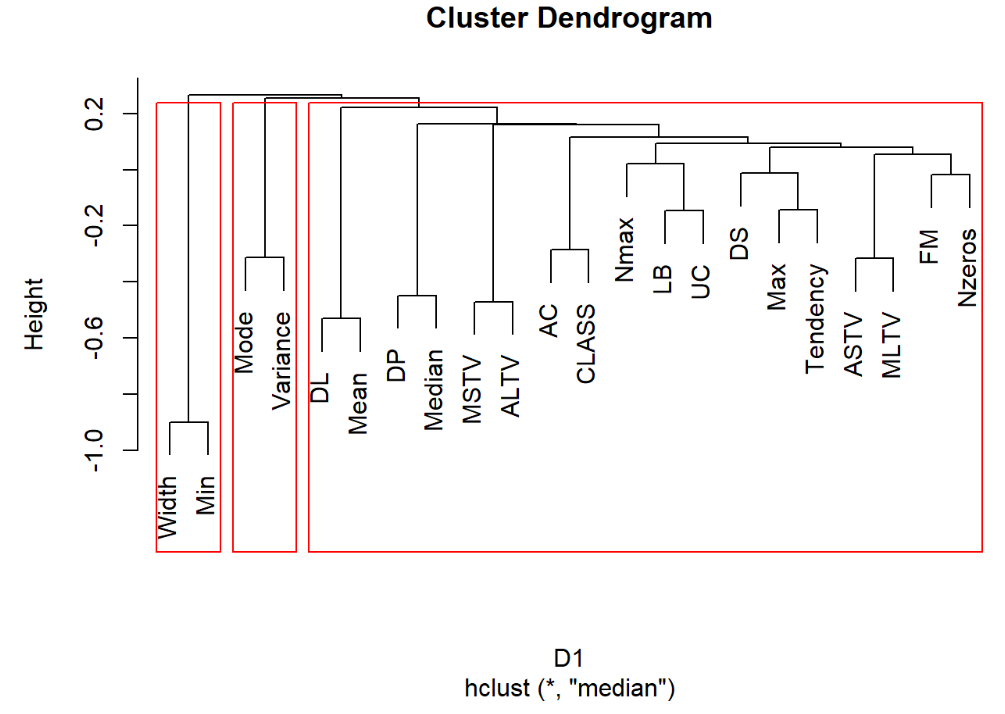
3.3.4 类平均法
运行程序:
hc1=hclust(D1,method = "average") #类平均法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
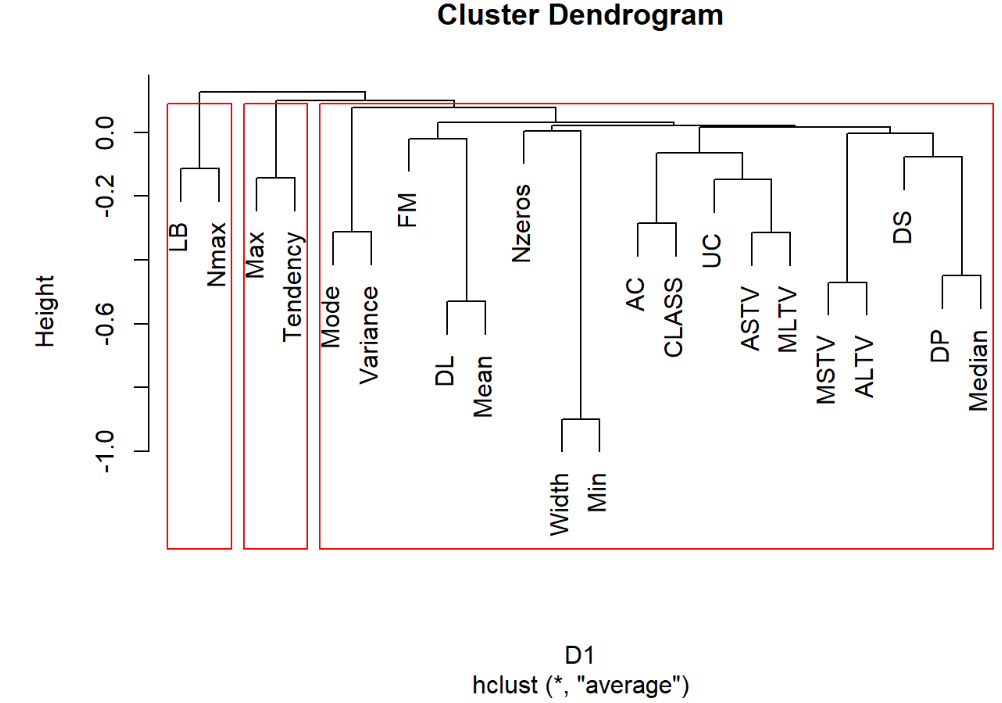
3.3.5 重心法
运行程序:
hc1=hclust(D1,method = "centroid") #重心法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
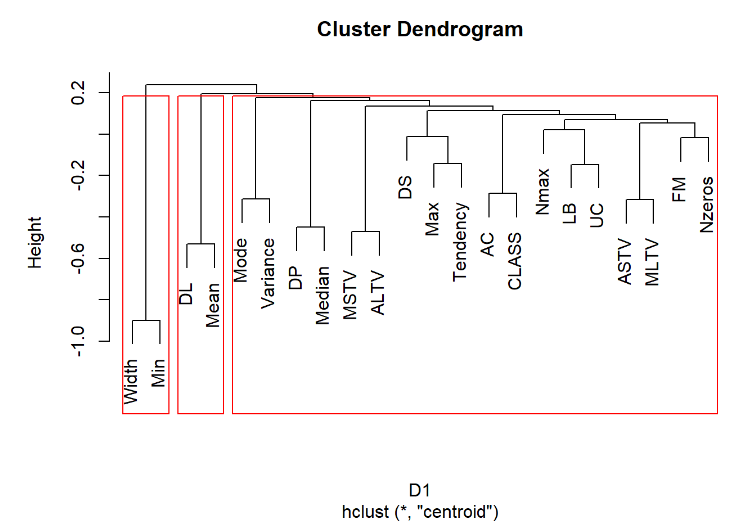
3.3.6 离差平方和法
1.ward.D法
运行程序:
hc1=hclust(D1,method = "centroid") #重心法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
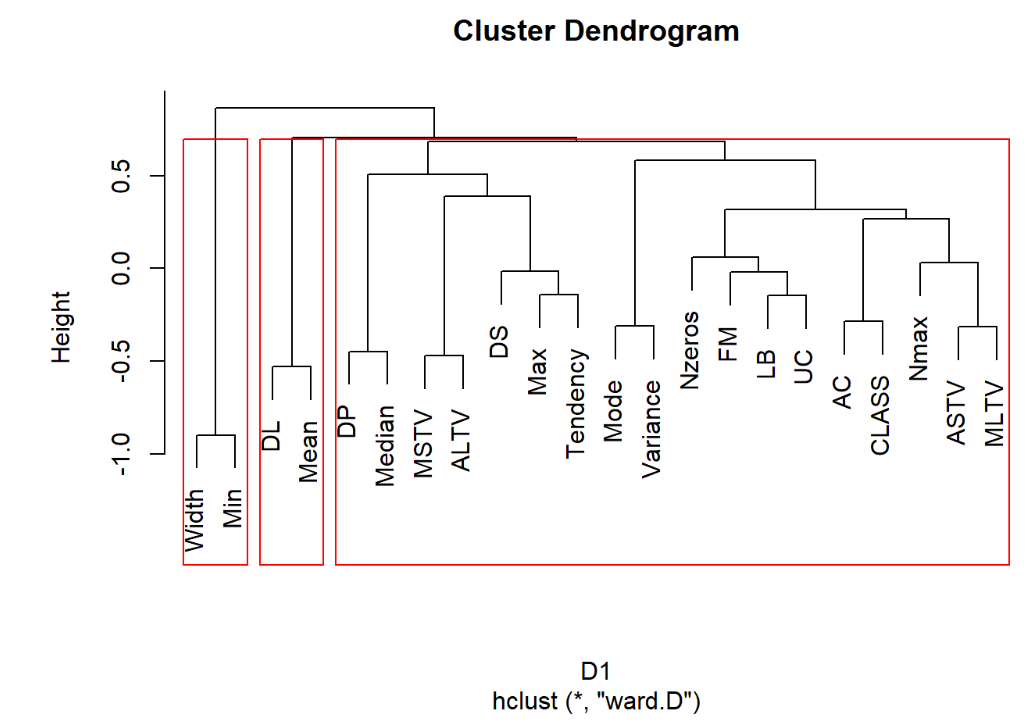
2.ward.D2法
运行程序:
hc1=hclust(D1,method = "ward.D2") #Ward.D2法 plot(hc1) rect.hclust(hc1,3) #加三分类框 运行结果:
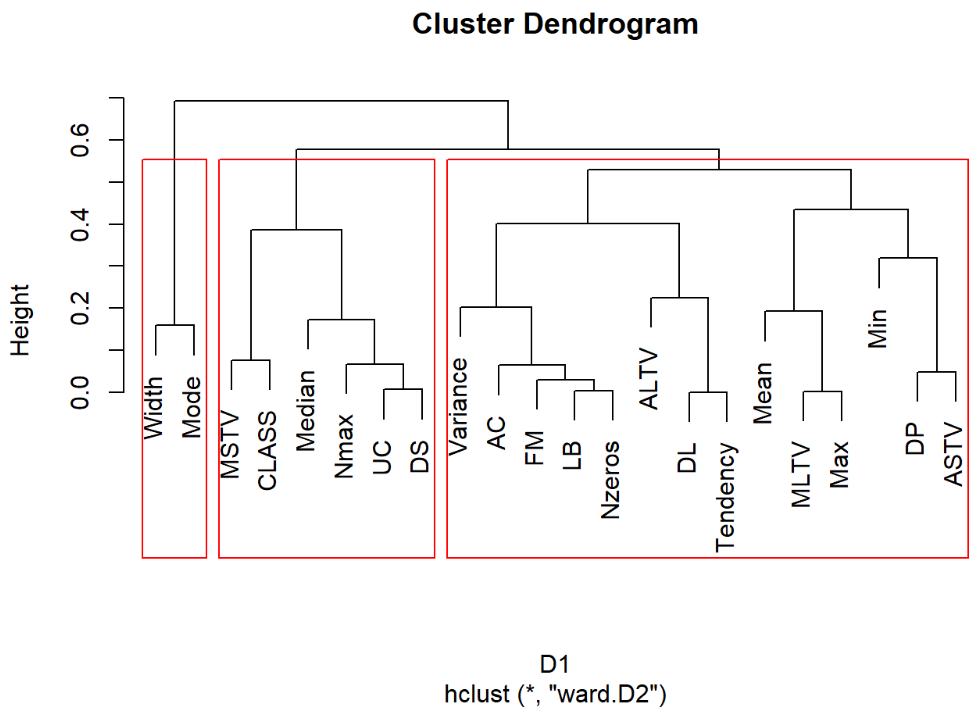
3.3.7 K-means快速聚类法
运行程序:
pm<-kmeans(d,3) #分三类 pm$clusterkm=kmeans(data2[,1:20],3) plot(data2,pch=km$cluster,col=km$cluster) 运行结果:
## LB AC FM UC DL DS DP ASTV ## 3 2 1 2 2 1 2 1 ## MSTV ALTV MLTV Width Min Max Nmax Nzeros ## 2 1 1 2 3 2 2 2 ## Mode Mean Median Variance Tendency CLASS ## 3 3 3 2 1 1 3.3.8 变量聚类总结
首先计算22个变量的相似系数并求出其相似聚类,分别利用最短距离、最长距离、中间距离、类平均、重心、离差平方和、Kmean法进行变量聚类,不同方法聚类结果如表1所示,结合图9—图15能较为直观地看出变量聚类情况。