【MySQL】连接查询(JOIN 关键字)—— 图文详解:内连接(INNER JOIN)、外连接(OUTER JOIN)、左连接(LEFT JOIN)、左外连接、右连接、右外连接、全连接、全外连接
文章目录
- 连接查询
- 驱动表
- 连接查询分类
- 内连接(INNER JOIN)
- 内连接 —— 等值连接
- 内连接 —— 自然连接(NATURAL JOIN)
- 内连接 —— 交叉连接 / 笛卡尔积(CROSS JOIN)
- 外连接(OUTER JOIN)
- 外连接 —— 左连接(LEFT JOIN) / 左外连接(LEFT OUTER JOIN)
- 拓展:左连接不包含内连接
- 外连接 —— 右连接(RIGHT JOIN) / 右外连接(RIGHT OUTER JOIN)
- 拓展:右连接不包含内连接
- 外连接 —— 全连接 / 全外连接
- 【注意】:FULL OUTER JOIN 关键字异常讨论
- 拓展:全连接不包括内连接
我是一名立志把细节都说清楚的博主,欢迎【关注】🎉 ~
原创不易, 如果有帮助 ,记得【点赞】【收藏】 哦~ ❥(^_-)~
如有错误、疑惑,欢迎【评论】指正探讨,我会尽可能第一时间回复的,谢谢支持
连接查询
MySQL使用 JOIN 关键字连接多个表查询数据,主要使用的是嵌套循环连接算法(nested-loop join)。这种算法机制简单的理解可以类比为for循环遍历一样。
从驱动表中选取数据作为循环的基础数据,然后以这些数据作为 查询条件 到下一个表中进行循环遍历查询。循环往复。
这种算法的缺点是: 连接的表越多,循环嵌套的层数就越多,算法复杂度呈指数级增长。
对应的处理方法是: 我们在设计查询时,尽可能减少连接表的个数。
驱动表
驱动表: 在使用多表嵌套连接时,首先,会全表扫描该一个表作为查询条件,这个表叫做驱动表。然后用驱动表返回的结果集逐行去匹配的表,叫做被驱动表。
关于驱动表的详细说明及性能优化,本文不过多提及,感兴趣的可以看这篇文章:
【MySQL】驱动表、被驱动表详解。—— 性能优化。
连接查询分类
- 内连接(INNER JOIN)
- 等值连接(最常用)
- 自然连接
- 交叉连接
- 外连接(INNER JOIN)
- 左连接(LEFT JOIN) / 左外连接(LEFT OUTER JOIN)
- 右连接(RIGHT JOIN) / 有外连接(RIGHT OUTER JOIN)
- 全连接
内连接(INNER JOIN)
内连接查询的是两张表的交集,即两张表都有的数据。
内连接的驱动表:通常是数据量较少的表作为驱动表。
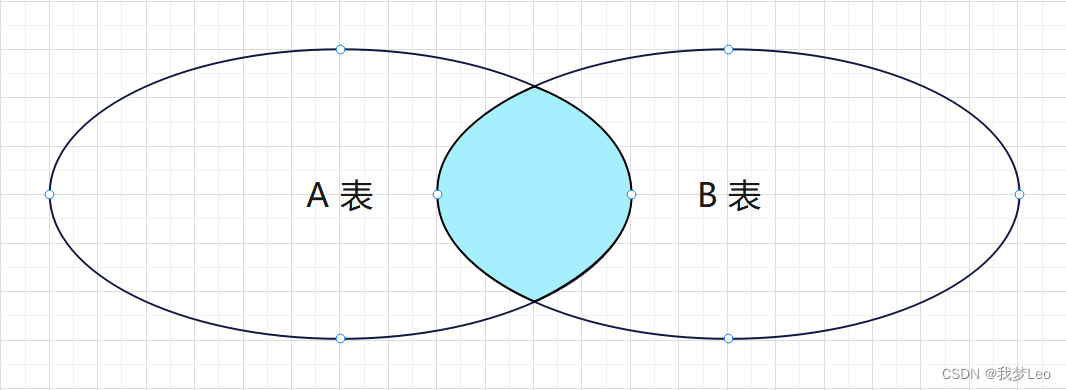
内连接 —— 等值连接
SQL 代码形式如下:
# FROM 两表 WHERE 连接。 SELECT * FROM A表 , B表 WHERE A表.id = B表.id; # JOIN ON 连接。 SELECT * FROM A表 JOIN B表 ON A表.id = B表.id; # INNER JOIN ON 连接。 SELECT * FROM A表 INNER JOIN B表 ON A表.id = B表.id; # 多JOIN ON 连接。 SELECT * FROM A表 INNER JOIN B表 ON A表.id = B表.id INNER JOIN C表 ON B表.id = C表.id; 内连接 —— 自然连接(NATURAL JOIN)
自然连接会在两个表中寻找那些名称相同的列,并且以这些列的值作为联接的条件。不需要我们指定连接条件。
案例说明
假设有两个表,一个是员工表 employees 和一个是部门表 departments。
employees 表:
+--------+------+-------------+--------+ | emp_id | name | department | salary | +--------+------+-------------+--------+ | 1 | John | Sales | 50000 | | 2 | Mary | Engineering | 60000 | | 3 | Bob | Sales | 40000 | +--------+------+-------------+--------+ departments 表:
+---------+-------------+ | dept_id | department | +---------+-------------+ | 1 | Sales | | 2 | Engineering | | 3 | Accounting | +---------+-------------+ 如果我们想要找到所有员工及其部门的信息,我们可以使用自然连接来联接这两个表:
SELECT * FROM employees NATURAL JOIN departments; 这将返回两个表中同名的列 department 的值相等的那些行,因此结果集将是:
+--------+------+-------------+--------+---------+-------------+ | emp_id | name | department | salary | dept_id | department | +--------+------+-------------+--------+---------+-------------+ | 1 | John | Sales | 50000 | 1 | Sales | | 2 | Mary | Engineering | 60000 | 2 | Engineering | +--------+------+-------------+--------+---------+-------------+ 注意,在这个例子中,emp_id 和 dept_id 是自然连接过程中被删除的重复列。
自然连接特点:
- 如果两个表中有同名的非空列,并且列中的值相等,那么这一行会出现在结果集中。
- 如果两个表中有同名的列,但是列中的值不相等,那么这一行不会出现在结果集中。
- 如果两个表中有同名的列,但是至少有一个列是空的,那么这一行也不会出现在结果集中。
- 自然连接会删除重复的列,只保留一个同名的列。
因为自然连接的特点,我们无法指定连接列,这种写法给给我们带来了不确定性。如果以后数据模型变更导致原来可以自然连接的列,不能再自然连接了,导致数据查询异常。所以通常情况下,不推荐使用自然连接。
内连接 —— 交叉连接 / 笛卡尔积(CROSS JOIN)
由没有联结条件的表关系返回的结果叫交叉连接,也叫笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
# 笛卡尔积示例一: SELECT * FROM A表 JOIN B表; # 笛卡尔积示例二: SELECT * FROM A表, B表; 我是一名立志把细节都说清楚的博主,欢迎【关注】🎉 ~
原创不易, 如果有帮助 ,记得【点赞】【收藏】 哦~ ❥(^_-)~
如有错误、疑惑 ,欢迎【评论】指正探讨,我会尽可能第一时间回复的,谢谢支持
外连接(OUTER JOIN)
外连接可以保留连接表所有的记录,包括这条记录没有匹配的记录也可以保留(以NULL形式出现)。
保留表可以根据保留左表、右表、全表从而分为:
- 左连接/左外连接。
- 右连接/右外连接。
- 全连接/全外连接。
左表、右表的判断标准,是以包含 JOIN 的关键字作为基准(如:LEFT JOIN 、 LEFT OUTER JOIN、RIGHT JOIN、RIGHT OUT JOIN):
- 关键字的左边称为左表。
- 关键字的右边称为右表。
外连接 —— 左连接(LEFT JOIN) / 左外连接(LEFT OUTER JOIN)
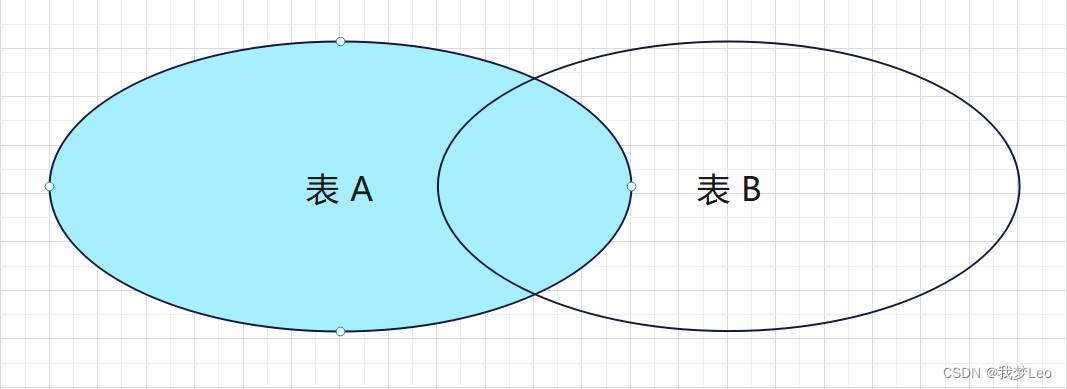
左连接会返回左表中的所有记录。如果右表中没有匹配的记录,则右表字段使用 NULL 填充。
# LEFT JOIN ON 连接。 SELECT * FROM A表 LEFT JOIN B表 ON A表.id = B表.id; # RIGHT JOIN ON 连接。 SELECT * FROM A表 RIGHT JOIN B表 ON A表.id = B表.id; Employees 表:
+----+----------+ | id | name | +----+----------+ | 1 | Alice | | 7 | Bob | | 11 | Meir | | 90 | Winston | | 3 | Jonathan | +----+----------+ EmployeeUNI 表:
+----+-----------+ | id | unique_id | +----+-----------+ | 3 | 1 | | 11 | 2 | | 90 | 3 | +----+-----------+ 左连接SQL样例:
SELECT unique_id, name FROM Employees LEFT JOIN EmployeeUNI ON Employees.id = EmployeeUNI.id; 结果:
+-----------+----------+ | unique_id | name | +-----------+----------+ | null | Alice | | null | Bob | | 2 | Meir | | 3 | Winston | | 1 | Jonathan | +-----------+----------+ 拓展:左连接不包含内连接
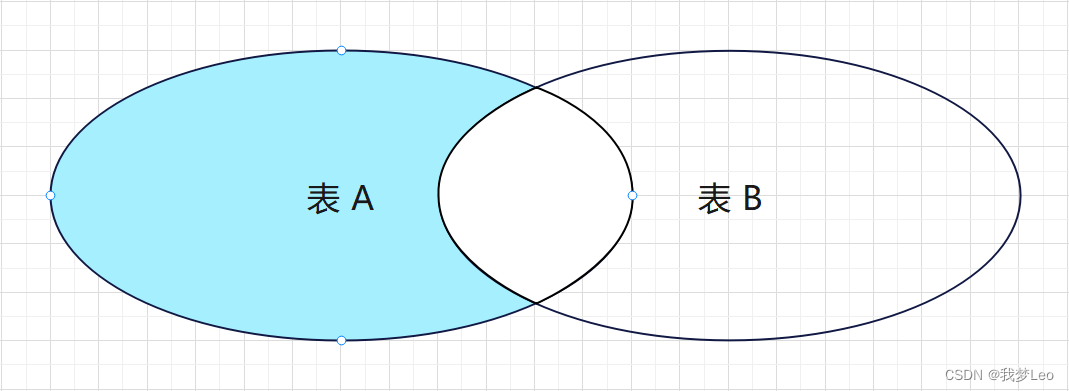
模版样式:
SELECT * FROM A表 LEFT JOIN B表 ON A表.id = B表.id WHERE B表.id IS NULL; 外连接 —— 右连接(RIGHT JOIN) / 右外连接(RIGHT OUTER JOIN)
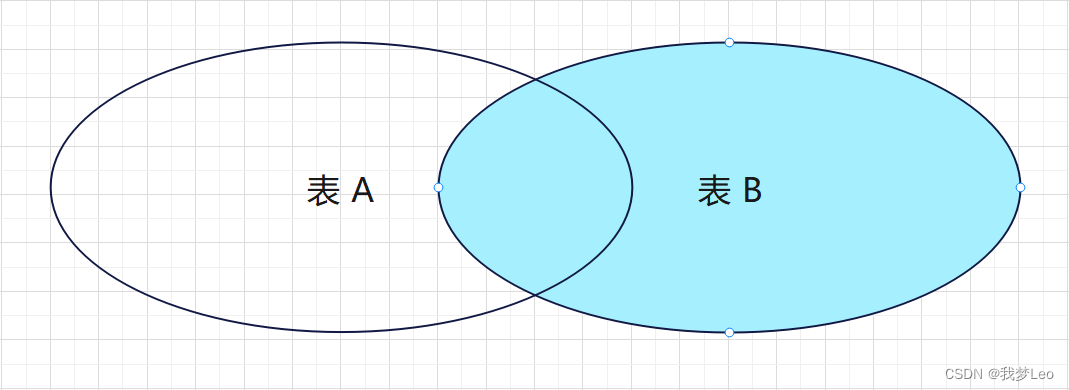
与左连接同理。
右连接会返回右表中的所有记录。如果左表中没有匹配的记录,则左表字段使用 NULL 填充
通常情况下,右连接会被习惯性的改写成左连接。效果是一样的,左连接的可读性更好点。
模版样式:
SELECT * FROM A表 RIGHT JOIN B表 ON A表.id = B表.id; 拓展:右连接不包含内连接
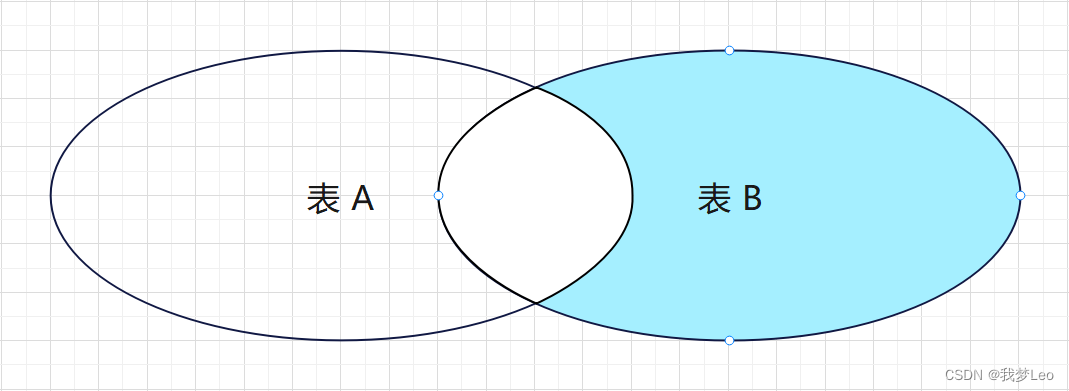
模版样式:
SELECT * FROM A表 RIGHT JOIN B表 ON A表.id = B表.id WHERE A表.id IS NULL; 外连接 —— 全连接 / 全外连接
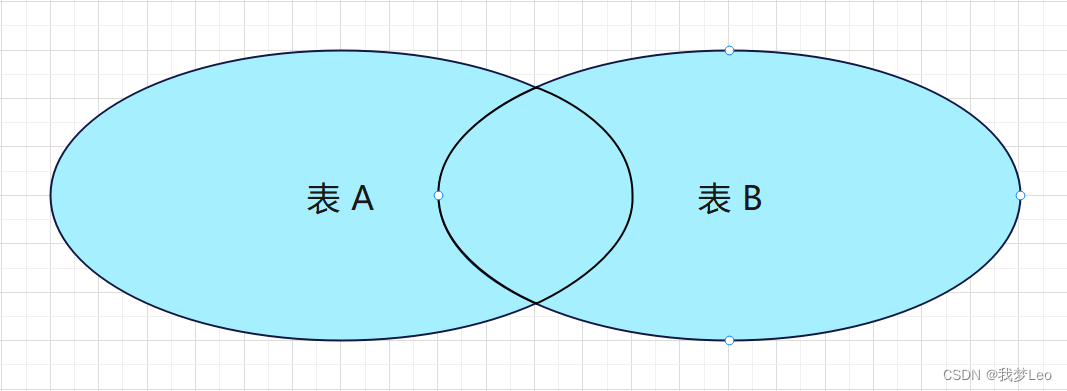
全连接(也称全外连接)一般没有什么意义,MySQL并不直接支持全外连接,但可以通过左右外连接的并集(UNION 关键字)来模拟实现。
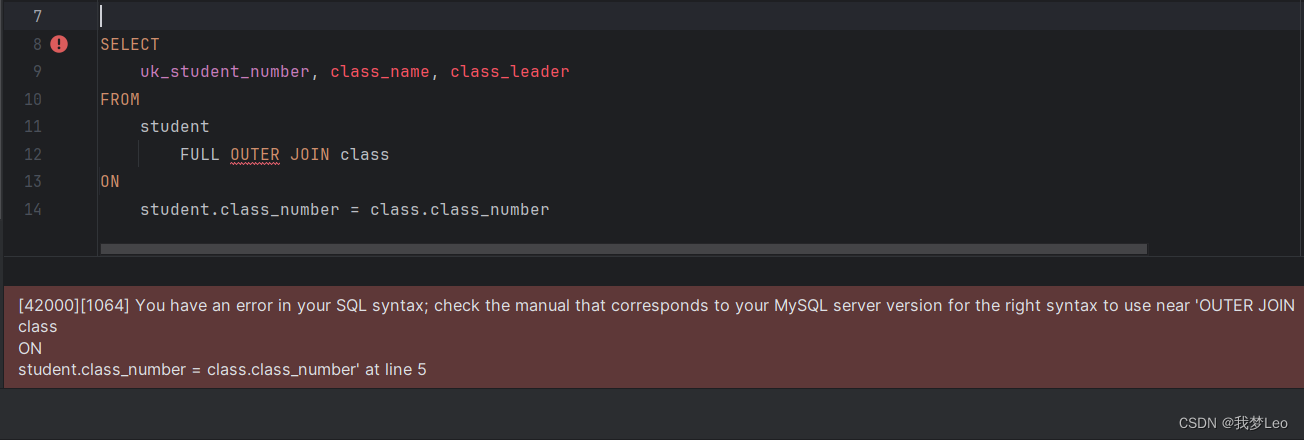
SELECT * FROM A表 LEFT JOIN B表 ON A表.id = B表.id UNION SELECT * FROM A表 RIGHT JOIN B表 ON A表.id = B表.id 【注意】:FULL OUTER JOIN 关键字异常讨论
网上部分教程出现的 FULL OUTER JOIN 关键词,但是MySQL并不直接支持全外连接,所以可能很多版本 无法直接使用FULL OUTER JOIN 关键词,至少我测试的版本是这样。所以在使用前建议测试一下。
# 错误SQL演示 SELECT * FROM A表 FULL OUTER JOIN B表 ON A表.id = B表.id 为此我做了测试,我这里使用的 MySQL 8.0.32 版本,并不识别 FULL OUTER JOIN 关键词。并且执行搜索提示错误。
拓展:全连接不包括内连接
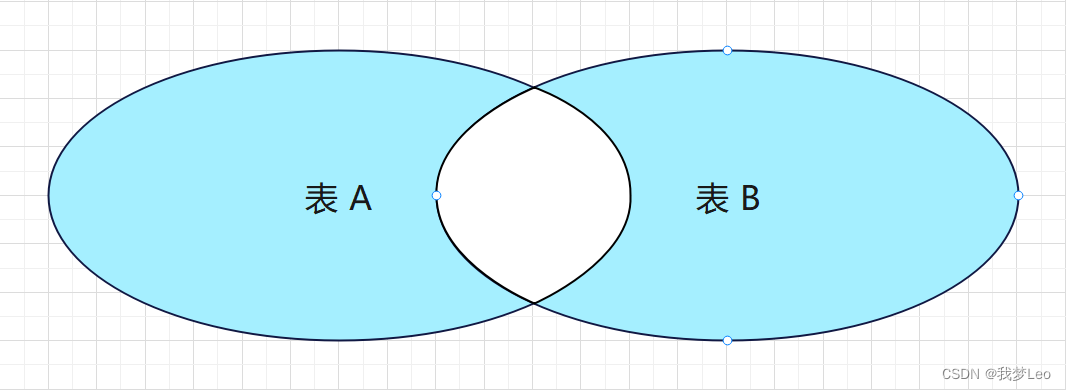
SELECT * FROM A表 LEFT JOIN B表 ON A表.id = B表.id UNION SELECT * FROM A表 RIGHT JOIN B表 ON A表.id = B表.id WHERE A表.id IS NULLOR B表.id IS NULL 我是一名立志把细节都说清楚的博主,欢迎【关注】🎉 ~
原创不易, 如果有帮助 ,记得【点赞】【收藏】 哦~ ❥(^_-)~
如有错误、疑惑 ,欢迎【评论】指正探讨,我会尽可能第一时间回复的,谢谢支持