0基础学会在亚马逊云科技AWS上搭建生成式AI云原生Serverless问答Q&A机器人(含代码和步骤)
小李哥今天带大家继续学习在国际主流云计算平台亚马逊云科技AWS上开发生成式AI软件应用方案。上一篇文章我们为大家介绍了,如何在亚马逊云科技上利用Amazon SageMaker搭建、部署和测试开源模型Llama 7B。下面我将会带大家探索如何搭建高扩展性、高可用的完全托管云原生基础设施,让终端用户通过云平台访问到部署的开源AI大语言模型。下面就是小李哥做的一个简单Meta Llama 7B问答聊天机器人界面。
这是小李哥的AWS生成式AI云计算架构介绍第二篇文章,在这个系列里我会带大家介绍所有的方案技术讲解、具体的操作细节和分享项目的代码,目的就是为了帮助大家0基础即可上手国际最热门的云计算平台亚马逊云科技AWS。也欢迎大家关注小李哥,以免错过本系列中其他的优质GenAI解决方案。
首先我们看架构图:
方案架构图:
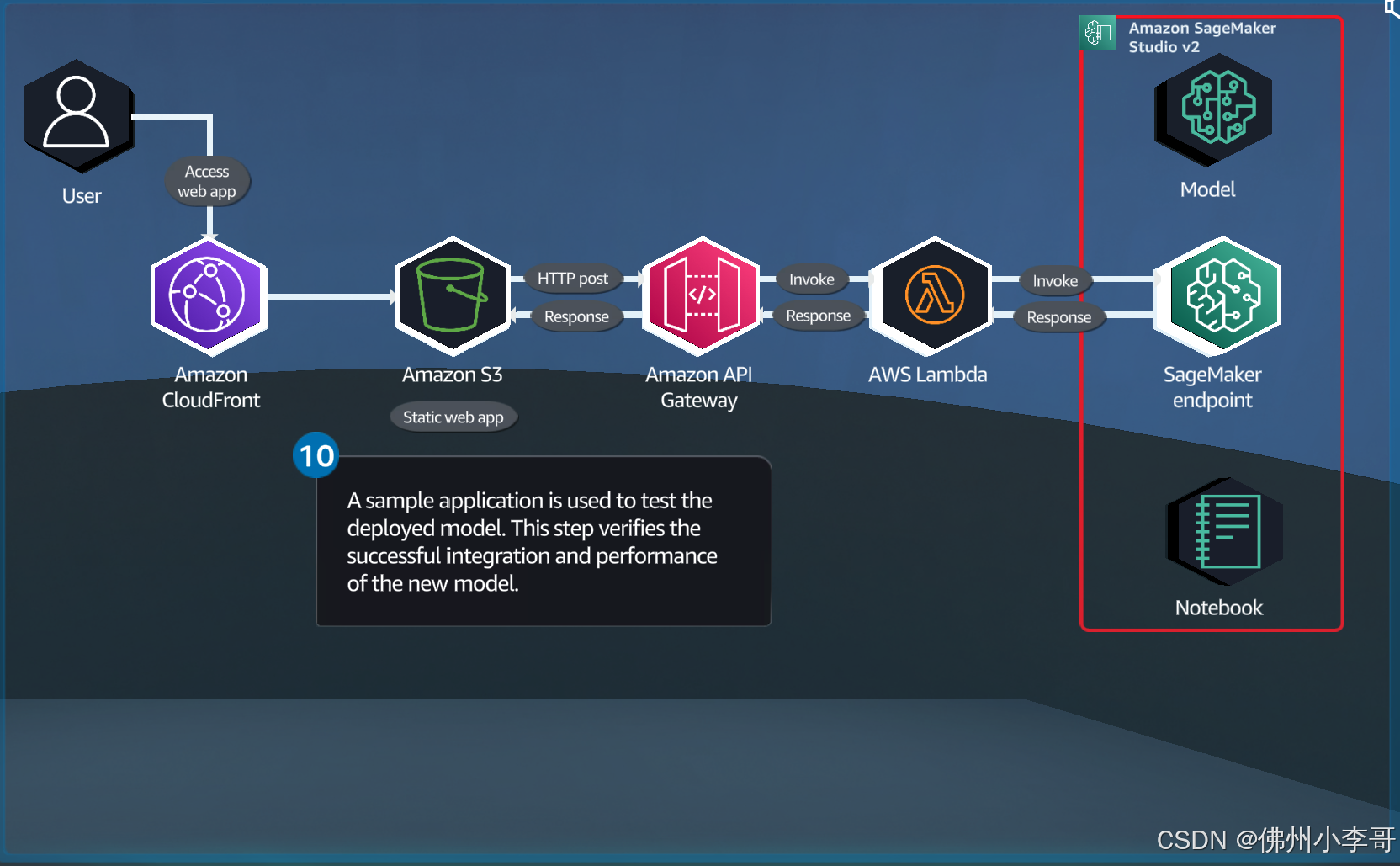
涉及到的亚马逊云科技云计算服务:
本云原生方案包含了多个热门的云原生、全托管的亚马逊云科技服务,涉及网络、开发、计算和存储。全部的服务列表如下:
1. 网络CDN加速:Amazon CloudFront
Amazon CloudFront 是一种内容分发网络 (CDN) 服务,能够快速将数据、视频、应用程序和API安全地传递给全球客户。其优势在于通过分布在全球的边缘位置提供低延迟和高传输速度,同时具备与AWS服务的无缝集成,确保安全和高性能的内容交付。
2. 前端页面托管服务器: Amazon S3
Amazon S3(Simple Storage Service)是一个高度可扩展的对象存储服务,适用于存储和检索任何数量的数据。其优势在于提供11个9的数据持久性和冗余存储,确保前端页面的高可用性和快速访问,并且支持静态网站托管,简化了网站的部署和管理。
3. API对外网关节点:Amazon API Gateway
Amazon API Gateway 是一种完全托管的服务,使开发者能够轻松创建、发布、维护、监控和保护API。其优势在于可以处理成千上万的并发API调用,确保API的高可用性和低延迟,并且与AWS Lambda无缝集成,实现真正的无服务器架构。
4. 云原生Serverless代码托管服务: AWS Lambda
AWS Lambda 是一种无服务器计算服务,允许用户运行代码而无需预置或管理服务器。其优势在于自动扩展并仅在代码运行时计费,降低了运营成本。Lambda与其他AWS服务深度集成,简化了事件驱动架构的实现,提升了应用程序的灵活性和响应能力。
搭建云原生Serverless应用的具体步骤:
1. 首先我们打开AWS控制台,进入Lambda,点击我们的Lambda函数“endpoint_test_function”
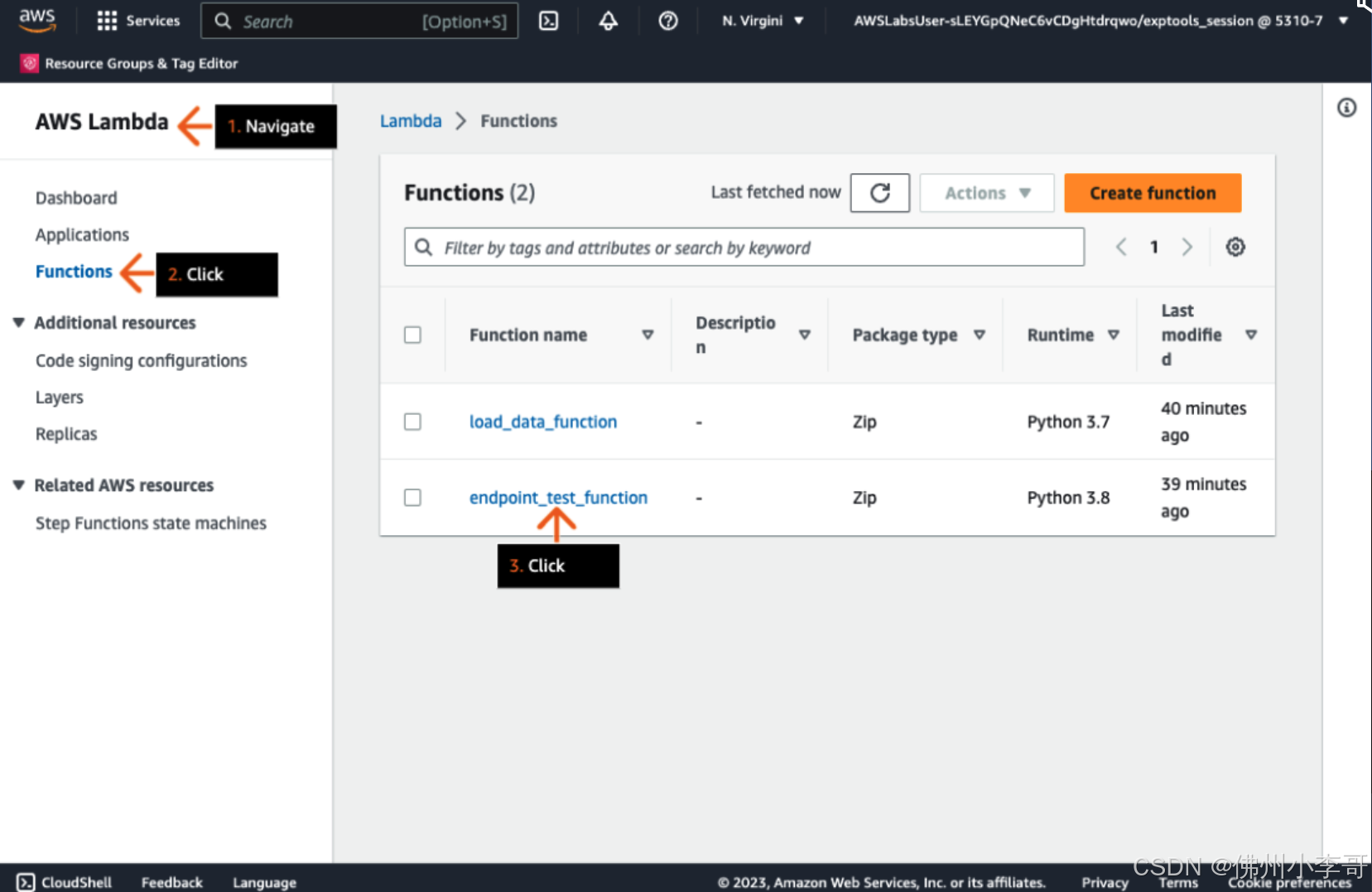
2. 接着我们进入Lambda配置页面,配置Lambda函数
3. 点击“Edit”修改Lambda函数的基础配置
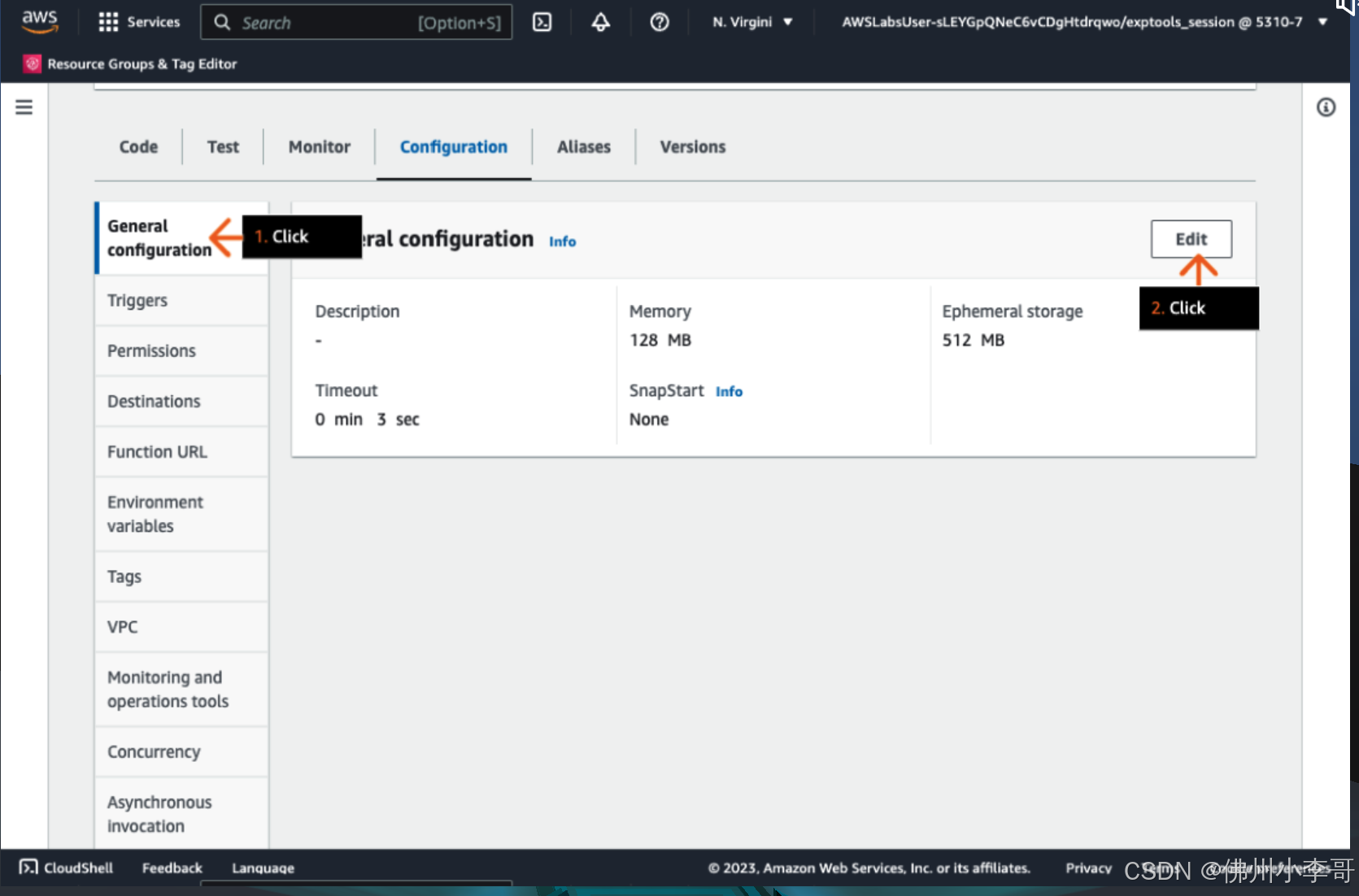
4.修改Timeout时间到1分钟。Lambda的timeout配置是函数处理请求的超时时间限额,Lamda可配置的最长超时时间为15分钟,默认时间是3秒,我们需要根据我们的代码运行时间进行对应修改。
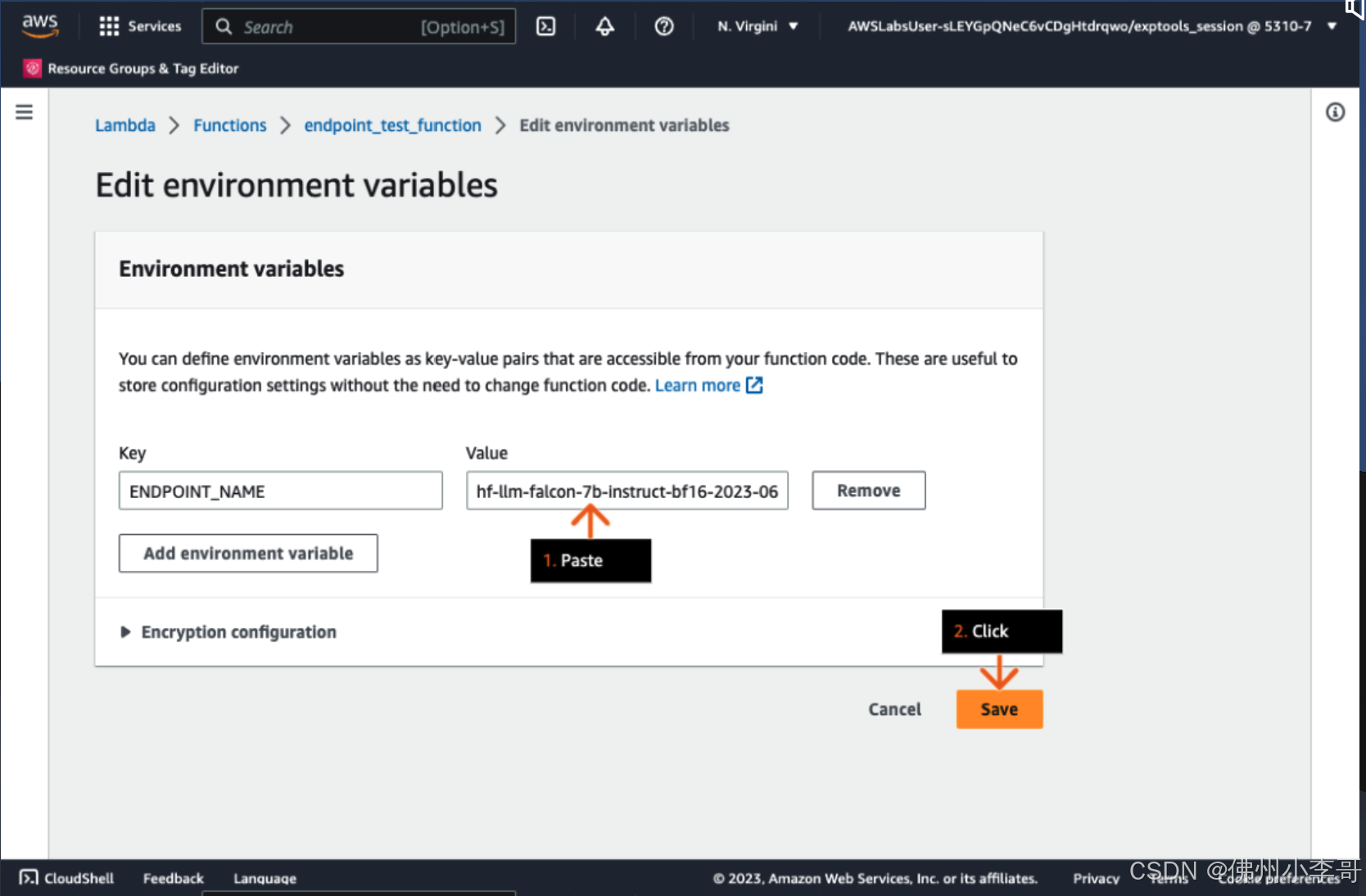
5. 接下来,我们为lamda函数中的代码配置环境变量,点击“Edit”
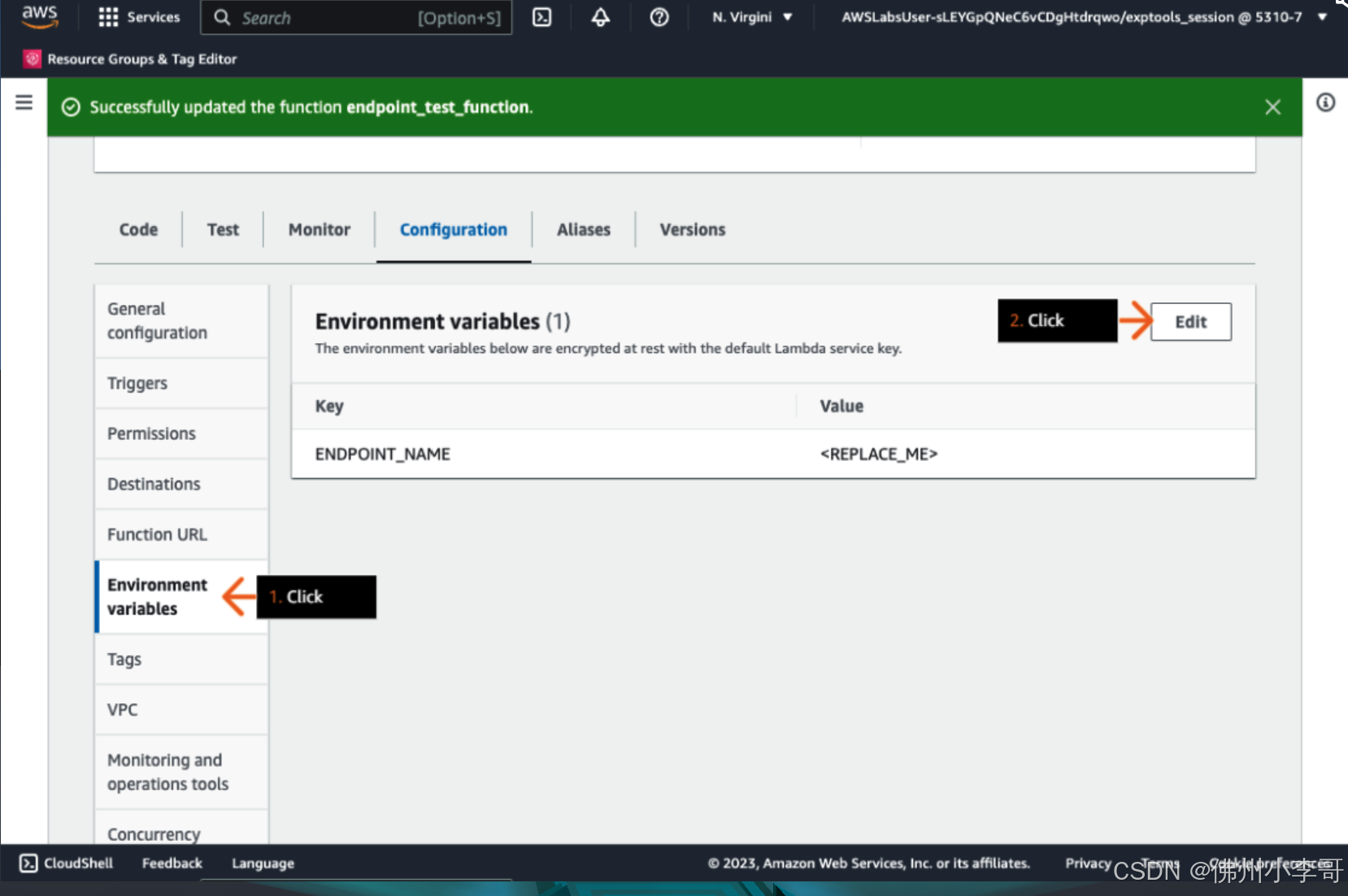
6. 我们将前一篇文章中,最后一步获取的AI大语言模型API节点URL复制到Value部分。
7.接下来我们进入Lambda中查看调用AI大语言模型的Python代码。小李哥将代码分享给大家,方便大家动手实践。
# Import necessary libraries import json import boto3 import os import re import logging # Set up logging logger = logging.getLogger() logger.setLevel(logging.INFO) # Create a SageMaker client sagemaker_client = boto3.client("sagemaker-runtime") # Define Lambda function def lambda_handler(event, context): # Log the incoming event in JSON format logger.info('Event: %s', json.dumps(event)) # Clean the body of the event: remove excess spaces and newline characters cleaned_body = re.sub(r'\s+', ' ', event['body']).replace('\n', '') # Log the cleaned body logger.info('Cleaned body: %s', cleaned_body) # Invoke the SageMaker endpoint with the cleaned body as payload and content type as JSON response = sagemaker_client.invoke_endpoint( EndpointName=os.environ["ENDPOINT_NAME"], ContentType="application/json", Body=cleaned_body ) # Load the response body and decode it result = json.loads(response["Body"].read().decode()) # Return the result with status code 200 and the necessary headers return { 'statusCode': 200, 'headers': { 'Access-Control-Allow-Headers': 'Content-Type', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': 'OPTIONS,POST' }, 'body': json.dumps(result) } 代码解释:
第26行到第34行之间的代码
这段代码使用请求体调用SageMaker端点,然后保存响应。
第33行到第45行之间的代码
这段代码解码接收到的响应,并以结构化的JSON格式返回。
提供了状态码200以及必要的头信息(主要用于CORS)。
8. 接下来我们进入S3存储桶查看前端代码。
前端代码如下:
Introduction to Generative AI Introduction to Generative AI
Please note: As with all AI-powered applications, outputs should be reviewed for accuracy and appropriateness.
9. 下面我们在AWS CDN Cloudfront中获取问答机器人UI的URL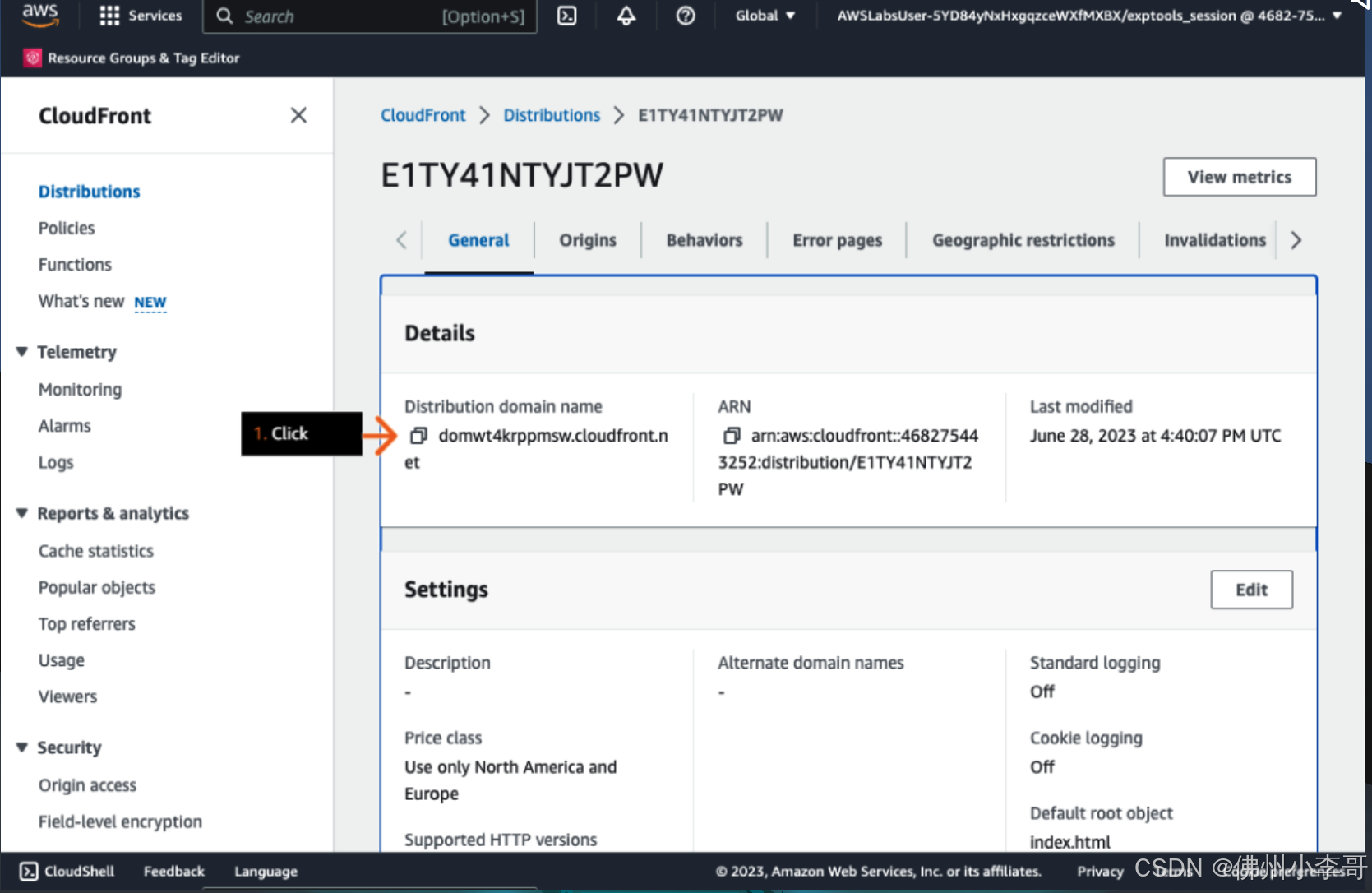
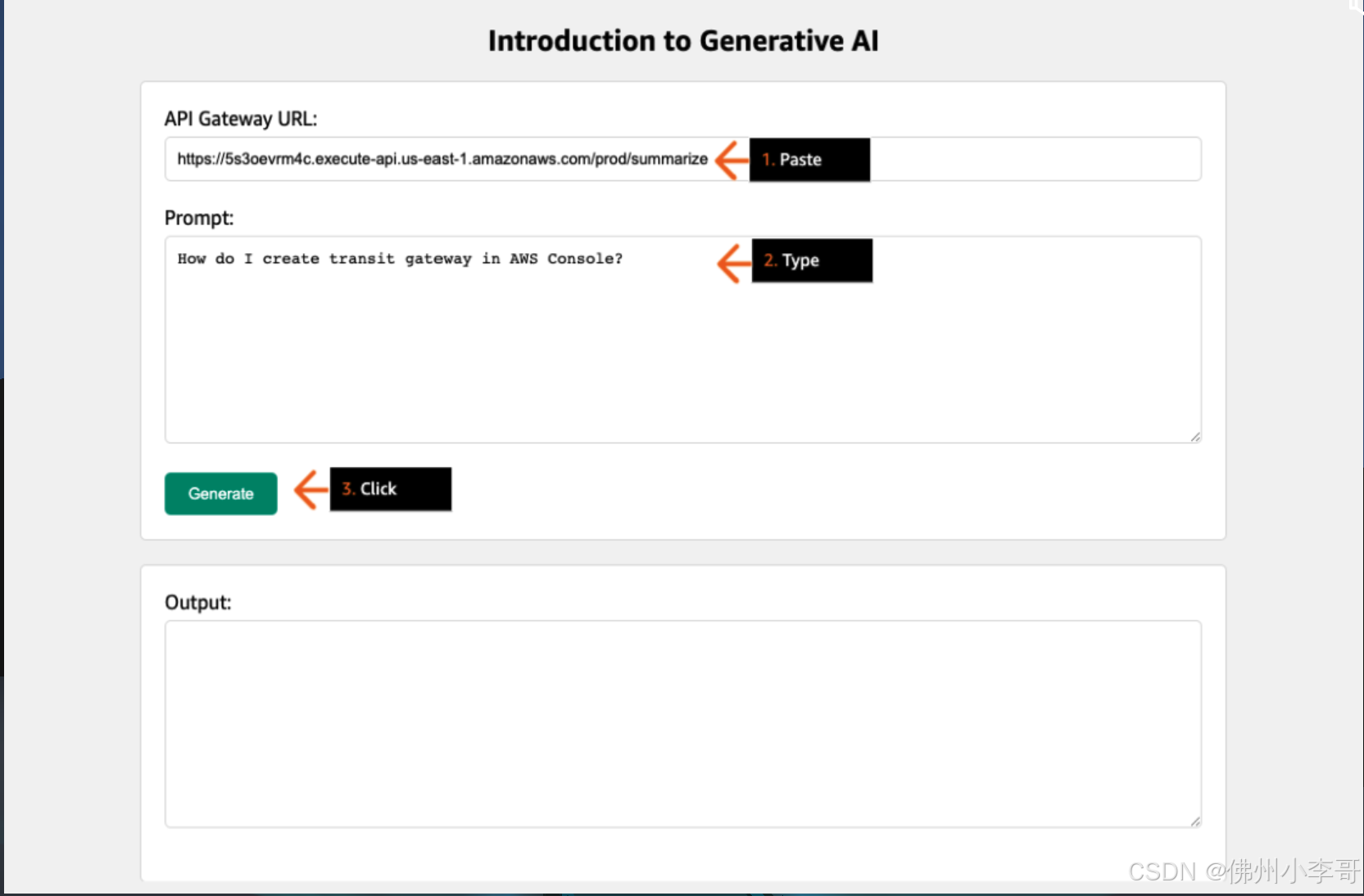
10. 将URL复制到浏览器中,打开后出现问答机器人的UI。这里需要我们获取一个API Gateway的URL。

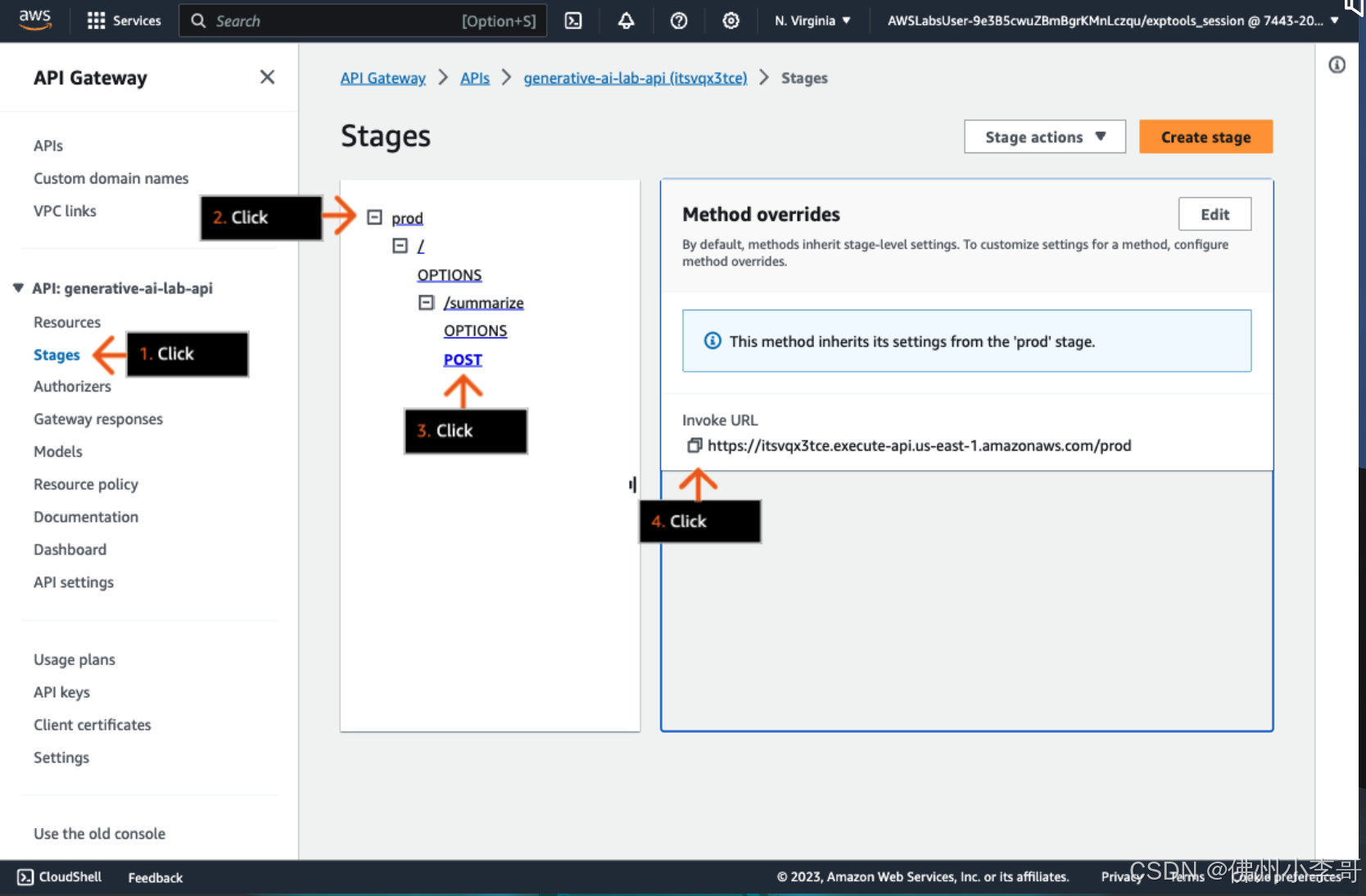
11. 我们进入到API Gateway中,获取Invoke URL
12. 最后如下图所示,填入Invoke URL和大家想问的问题,就可以得到Llama 7B的模型回复了。