AI算法13-岭回归算法Ridge Regression | RR
岭回归算法概述
多重共线性
多重共线性(Multicollinearity)是指多变量线性回归中,变量之间由于存在精确相关关系或高度相关关系而使回归估计不准确。
那么什么是精确相关关系与高度相关关系呢?假如有下面的(1)式,其中 w1 = 2、w2 = 3,同时如果又存在(2)式的关系,这时就说明 x1 与 x2 存在精确相关关系。当 x1 与 x2 之间存在近似精确相关关系,例如 x1 约等于 2 倍的 x2,则说明存在高度相关关系。
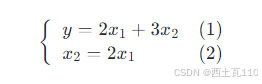
因为由(2)式可以将(1)式改写成不同的形式,这样就会导致 w 存在无数种解,会使得最后的回归估计不准确。
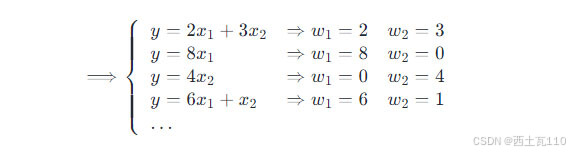
根据 w 的解析解,可以通过下面的公式来求解其中的逆矩阵运算,被除数为矩阵的伴随矩阵,除数为矩阵的行列式。可以看到矩阵可逆的条件是其行列式不能为零。
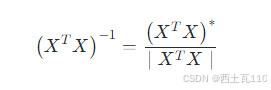
如果自变量之间存在多重共线性,会使得矩阵的行列式为零,导致矩阵不可逆。如下图中的示例 X,可以看到 x1 与 x2 存在精确相关关系,相乘后的矩阵经过初等变换后其行列式为零,说明相乘后的矩阵的行列式也必然为零(初等变换不改变行列式为零的判断),这时的矩阵不可逆。如果自变量之间是高度相关关系,会使得矩阵的行列式近似等于零,这时所得的 w 的偏差会很大,也会造成回归估计不准确。

多重共线性的问题既然是自变量之间存在相关关系,其中一个解决方法就是剔除掉共线的自变量,可以通过计算方差扩大因子(Variance inflation factor,VIF)来量化自变量之间的相关关系,方差扩大因子越大说明自变量的共线性越严重。
另一种方式是通过对代价函数正则化加入惩罚项来解决,其中一种正则化方式被称为吉洪诺夫正则化(Tikhonov regularization),这种代价函数正则化后的线性回归被称为岭回归(Ridge Regression)。
岭回归简介
岭回归(英文名:(ridge regression, Tikhonov regularization)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
通常岭回归方程的R平方值会稍低于普通回归分析,但回归系数的显著性往往明显高于普通回归,在存在共线性问题和病态数据偏多的研究中有较大的实用价值。
适用情况:
- 可以用来处理特征数多于样本数的情况
- 可适用于“病态矩阵”的分析(对于有些矩阵,矩阵中某个元素的一个很小的变动,会引起最后计算结果误差很大,这类矩阵称为“病态矩阵”)
- 可作为一种缩减算法,通过找出预测误差最小化的λ,筛选出不重要的特征或参数,从而帮助我们更好地理解数据,取得更好的预测效果
岭回归算法步骤
岭回归的代价函数第一项与标准线性回归的一致,都是欧几里得距离的平方和,只是在后面加上了一个 w 向量的L2-范数6 的平方作为惩罚项(L2-范数的含义为向量 W 每个元素的平方和然后开平方),其中 λ 表示惩罚项的系数,人为的控制惩罚项的大小。由于正则项是L2-范数,有时这种正则化方式也被称为L2正则化。
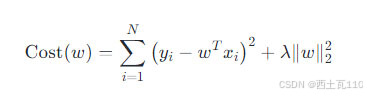
同标准线性回归一样,也是求使得岭回归的代价函数最小时 w 的大小:
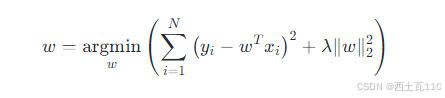
代价函数通过求导直接得到 w 的解析解,其中 X 为 N x M 矩阵,y 为 N 维列向量, λ 属于实数集,I 为 M x M 的单位矩阵。
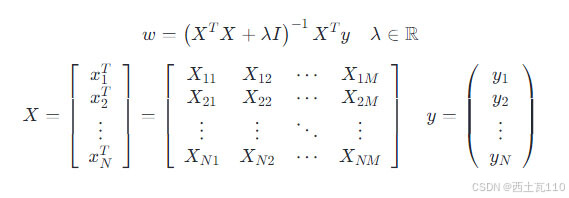
岭回归算法原理证明
岭回归代价函数为凸函数
同样需要证明:
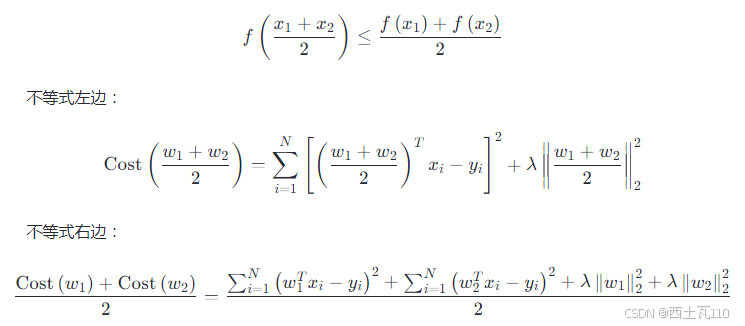
- 不等式两边的前半部分与标准线性回归一致,只需要证明剩下的差值大于等于零即可
- 将其改写成向量点积的形式
- 展开括号
- 合并相同的项,w1的转置乘w2与w2的转置乘w1互为转置,又因为结果为实数,所以这个两项可以合并
- 可以写成向量的平方的形式
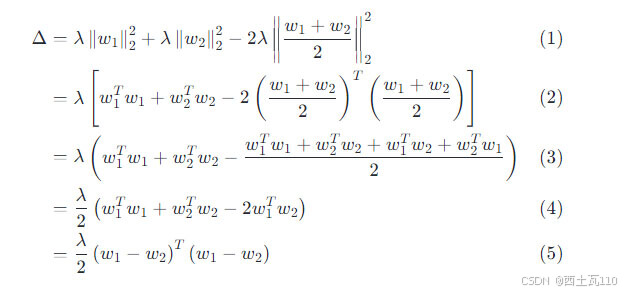
不等式右边减去不等式左边的差值为平方式的连加运算加上两向量差的平方,人为的控制 λ 的大小,最后的结果在实数范围内必然大于等于零,证毕。
岭回归代价函数的解析解
- 岭回归的代价函数
- 前面三项为标准线性回归代价函数展开后的结果,w 的 L2-范数的平方可以写成向量 w 的点积
- 合并第一项与第四项
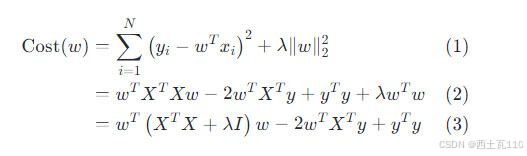
- 代价函数对 w 求偏导数,根据向量求导公式,只有第一项和第二项与 W 有关,最后一项为常数,又因为代价函数是个凸函数,当对 W 的偏导数为 0 向量时,代价函数为最小值。
- 将第二项移项后同时除以2,再两边同时在前面乘以一个逆矩阵,等式左边的矩阵和逆矩阵乘后为单位矩阵,所以只剩下 w 向量。
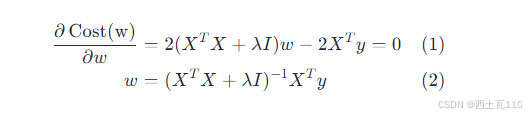
可以看到岭回归代价函数的解析解相较于标准线性回归来说多了一个可以人为控制的对角矩阵,这时可以通过调整不同的 λ 来使得括号内的矩阵可逆。
在上一节的工作年限与平均月工资的例子中,X 为 一个 5 x 2 的矩阵,y 为一个 5 维列向量,当 λ 为 0.1 时,最后可以算得 w 为一个 2 维列向量,则这个例子的线性方程为 y = 2139 * x - 403.9。
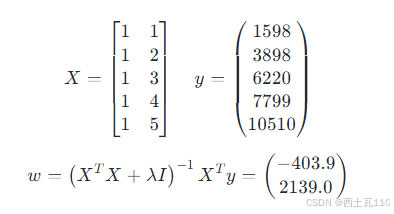
可以看到加了惩罚项后,相较于标准线性回归的结果,拟合变差了,但是通过人为的控制惩罚项的大小,解决了自变量多重共线性的问题。
岭回归算法代码实现
import numpy as np def ridge(X, y, lambdas=0.1): """ 岭回归 args: X - 训练数据集 y - 目标标签值 lambdas - 惩罚项系数 return: w - 权重系数 """ return np.linalg.inv(X.T.dot(X) + lambdas * np.eye(X.shape[1])).dot(X.T).dot(y)岭回归算法动画演示
下图展示了惩罚系数 λ 对各个自变量的权重系数的影响,横轴为惩罚系数 λ ,纵轴为权重系数,每一个颜色表示一个自变量的权重系数:
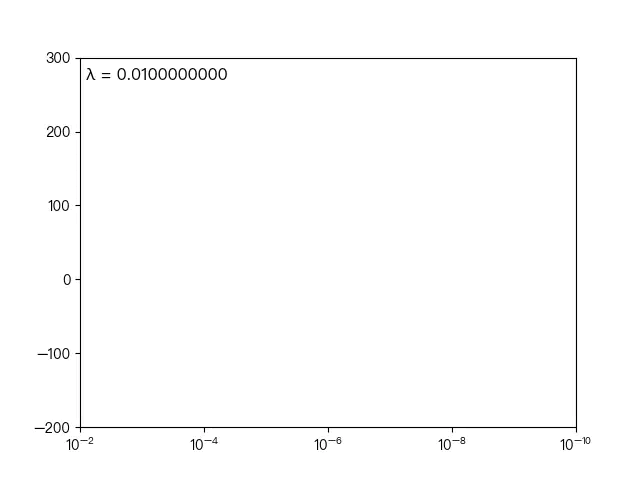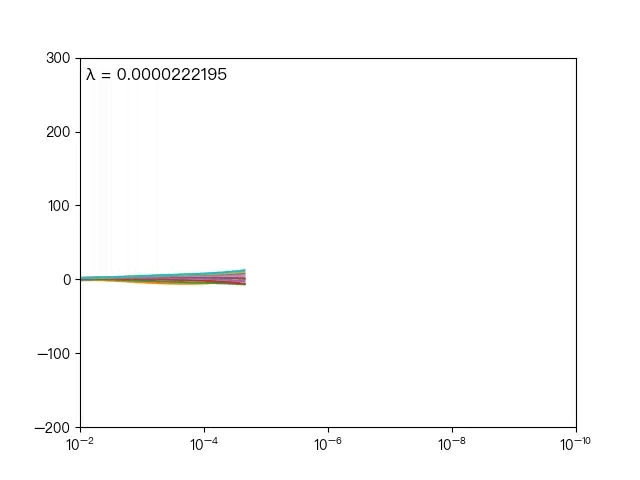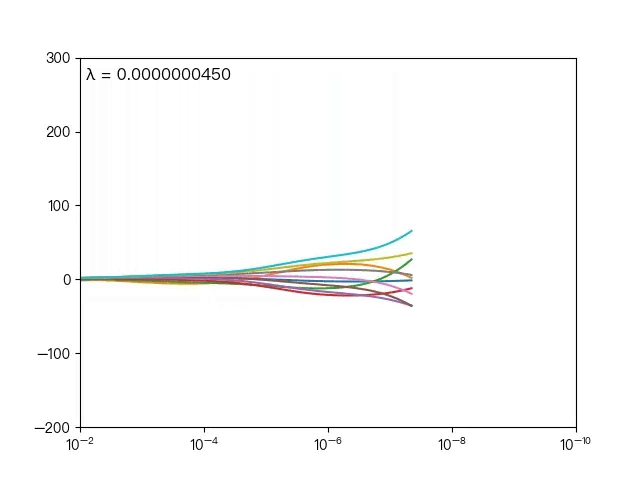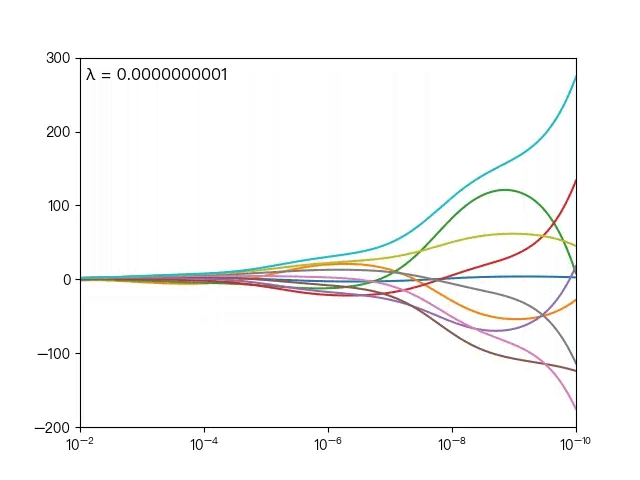
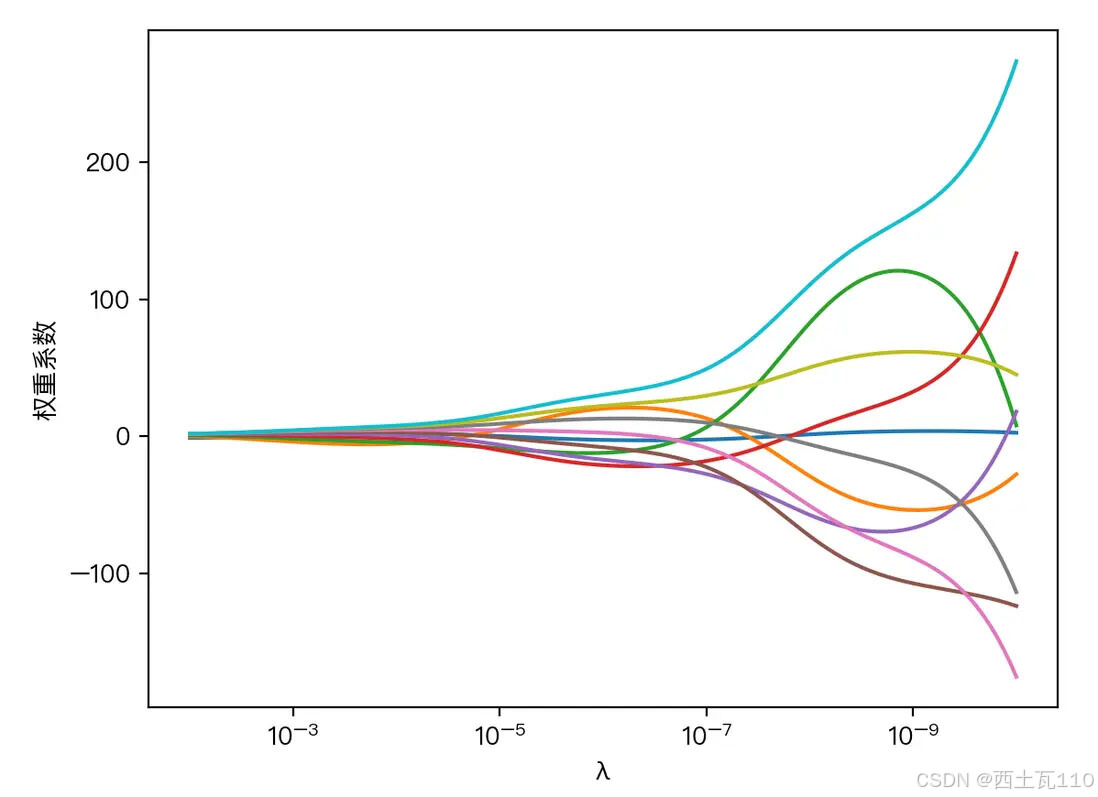
可以看到当 λ 越大时( λ 向左移动),惩罚项占据主导地位,会使得每个自变量的权重系数趋近于零,而当 λ 越小时( λ 向右移动),惩罚项的影响越来越小,会导致每个自变量的权重系数震荡的幅度变大。在实际应用中需要多次调整不同的 λ 值来找到一个合适的模型使得最后的效果最好。
岭回归算法的优缺点
岭回归相比其他算法,有如下的优缺点:
优点
- 岭回归可以用于处理高维数据,并且具有良好的泛化能力,即在训练数据集中表现良好,同时在测试数据集中也能达到很好的效果。
- 它适用于数据集包含多个潜在因素的情况,可以有效处理这些因素之间的共线性问题。
- 无需调整超参数,算法稳定,因此在不确定如何调参的情况下有着广泛的应用。
缺点
- 当我们对数据的解释很重要时,岭回归可能会对变量的解释性造成很大的影响,导致我们难以解释变量如何影响响应变量。
- 不适用于噪声较少的数据集,因为它会将噪声也包括在内,导致模型精度下降。
- 对于大量线性相关的特征,使用岭回归时需要小心,因为它可能会将变量的相关性强制降为零。
岭回归算法的实际应用
岭回归可以在许多不同的应用程序中使用。例如,在数据挖掘中处理分类和回归问题,或者在文本挖掘中将文本数据转换为数值形式。以下是岭回归的几种实际应用:
- 电子商务中的推荐系统
岭回归技术可以用于优化推荐系统,用于对用户对一些产品的反馈建立推荐模型,并预测用户对其他产品的评价。岭回归通过将评级系统建模为包括用户、产品、时间等因素的数据集,从而有效处理数据中存在的共线性问题。因此,推荐系统可以更准确地预测用户对新产品的反馈。
- 医学领域中的有限元素分析
岭回归可用于研究自动定量化(AQ)算法的组分和AIS(异速成分分析)算法的优化。AQ和AIS都是处理医学影像(例如磁共振成像)所需的频域自动标准化和分割工具,而岭回归则可以为这些工具提供必要的正则化和过拟合控制。
- 金融分析
在金融分析中,岭回归可以用于建立模型,预测股票价格,并尝试预测市场部门。金融数据通常是高维度和共线的,常常存在微小的劣化因素,并且易于出现过度拟合的情况。使用岭回归可以控制模型的复杂性,从而获得准确的预测结果。