Transformer——多头注意力机制(Pytorch)
创始人
2025-01-11 08:34:26
0次
1. 原理图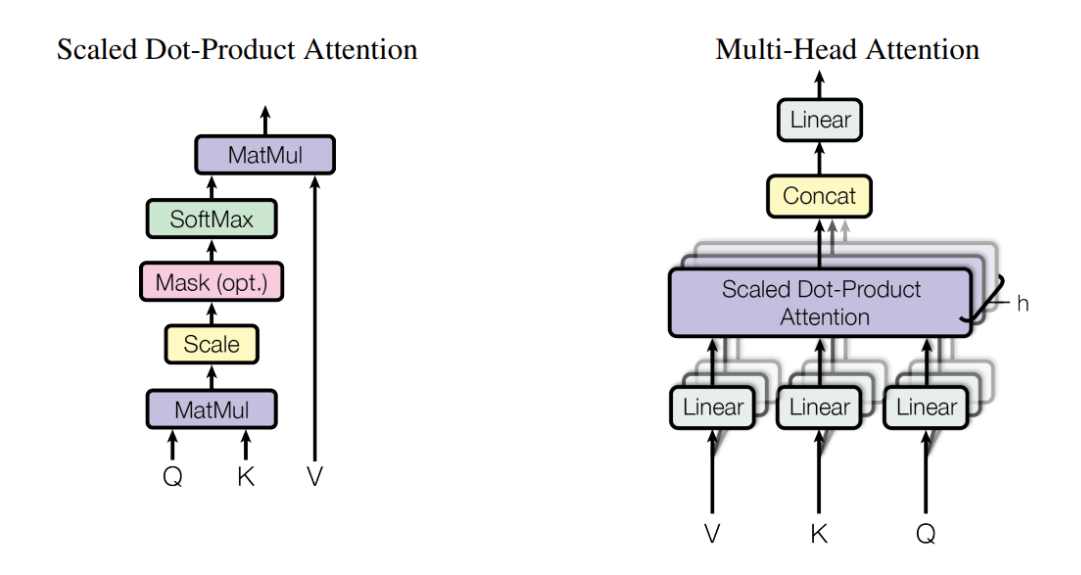
2. 代码
import torch import torch.nn as nn class Multi_Head_Self_Attention(nn.Module): def __init__(self, embed_size, heads): super(Multi_Head_Self_Attention, self).__init__() self.embed_size = embed_size self.heads = heads self.head_dim = embed_size // heads self.queries = nn.Linear(self.embed_size, self.embed_size, bias=False) self.keys = nn.Linear(self.embed_size, self.embed_size, bias=False) self.values = nn.Linear(self.embed_size, self.embed_size, bias=False) self.fc_out = nn.Linear(self.embed_size, self.embed_size, bias=False) def forward(self,queries, keys, values, mask): N = queries.shape[0] # batch_size query_len = queries.shape[1] # sequence_length key_len = keys.shape[1] # sequence_length value_len = values.shape[1] # sequence_length queries = self.queries(queries) keys = self.keys(keys) values = self.values(values) # Split the embedding into self.heads pieces # batch_size, sequence_length, embed_size(512) --> # batch_size, sequence_length, heads(8), head_dim(64) queries = queries.reshape(N, query_len, self.heads, self.head_dim) keys = keys.reshape(N, key_len, self.heads, self.head_dim) values = values.reshape(N, value_len, self.heads, self.head_dim) # batch_size, sequence_length, heads(8), head_dim(64) --> # batch_size, heads(8), sequence_length, head_dim(64) queries = queries.transpose(1, 2) keys = keys.transpose(1, 2) values = values.transpose(1, 2) # Scaled dot-product attention score = torch.matmul(queries, keys.transpose(-2, -1)) / (self.head_dim ** (1/2)) if mask is not None: score = score.masked_fill(mask == 0, float("-inf")) # batch_size, heads(8), sequence_length, sequence_length attention = torch.softmax(score, dim=-1) out = torch.matmul(attention, values) # batch_size, heads(8), sequence_length, head_dim(64) --> # batch_size, sequence_length, heads(8), head_dim(64) --> # batch_size, sequence_length, embed_size(512) # 为了方便送入后面的网络 out = out.transpose(1, 2).contiguous().reshape(N, query_len, self.embed_size) out = self.fc_out(out) return out batch_size = 64 sequence_length = 10 embed_size = 512 heads = 8 mask = None Q = torch.randn(batch_size, sequence_length, embed_size) K = torch.randn(batch_size, sequence_length, embed_size) V = torch.randn(batch_size, sequence_length, embed_size) model = Multi_Head_Self_Attention(embed_size, heads) output = model(Q, K, V, mask) print(output.shape)
相关内容
热门资讯
绝活儿辅助!广西老友玩老是输怎...
绝活儿辅助!广西老友玩老是输怎么办(辅助挂)都是真的有辅助app(讲解有挂)在进入广西老友玩老是输怎...
法门辅助!福建13水插件(辅助...
法门辅助!福建13水插件(辅助挂)一贯是有辅助技巧(有挂技术)1、许多玩家不知道福建13水插件辅助怎...
办法辅助!潮友会app下载官方...
办法辅助!潮友会app下载官方辅助器(辅助挂)真是真的是有辅助app(有挂教程)该软件可以轻松地帮助...
妙招辅助!邯郸胡乐挂辅助(辅助...
妙招辅助!邯郸胡乐挂辅助(辅助挂)好像存在有辅助插件(有挂方略)1、上手简单,内置详细流程视频教学,...
教程书辅助!乐酷辅助(辅助挂)...
教程书辅助!乐酷辅助(辅助挂)其实存在有辅助脚本(有挂细节)乐酷辅助能透视中分为三种模型:乐酷辅助模...
学习辅助!决战卡五星辅助(辅助...
学习辅助!决战卡五星辅助(辅助挂)本来真的是有辅助软件(有人有挂)学习辅助!决战卡五星辅助(辅助挂)...
绝活辅助!边锋嘉兴麻将辅助器(...
绝活辅助!边锋嘉兴麻将辅助器(辅助挂)真是真的有辅助神器(新版有挂)1、边锋嘉兴麻将辅助器公共底牌简...
举措辅助!枫叶辅助器(辅助挂)...
举措辅助!枫叶辅助器(辅助挂)本来存在有辅助技巧(竟然有挂)1、下载好枫叶辅助器正确养号方法之后点击...
讲义辅助!点我达辅助(辅助挂)...
讲义辅助!点我达辅助(辅助挂)一直存在有辅助技巧(有人有挂)1、点我达辅助辅助器安装包、点我达辅助辅...
模块辅助!威信茶馆有挂的吗(辅...
模块辅助!威信茶馆有挂的吗(辅助挂)一直真的是有辅助脚本(揭秘有挂)1、玩家可以在威信茶馆有挂的吗线...