python库(10):SpaCy库实现NLP处理
1 SpaCy简介
自然语言处理(NLP)是人工智能领域中一个重要的分支。它旨在使计算机能够理解、解释和生成人类语言。Python中的SpaCy库提供了丰富的功能和工具,SpaCy是一个开源的软件库,用于处理和操作自然语言文本,可以帮助我们轻松进行各种NLP任务。相比于其他NLP库,SpaCy的特点在于其高效性和易用性。它专为处理大规模文本数据而设计,拥有快速的管道处理能力,使得它在实际项目中非常实用。
2 SpaCy安装
首先通过pip来安装SpaCy。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple spacy结果如下:

安装完成后,还需要下载SpaCy模型。模型包含了词汇表、语料库以及各种必需的数据资源。在这里,我们下载一个最常用的英语模型en_core_web_sm:
python -m spacy download en_core_web_sm但是国内下载会失败,建议手动安装,下载地址如下:
Releases · explosion/spacy-models · GitHub
我这边下载的是en_core_web_lg-3.7.1
下载后到使用命令进行安装:
pip install F:/en_core_web_lg-3.7.1-py3-none-any.whl
注意:
模型后缀有sm/md/lg,sm/md/lg为描述大小的缩写:small(小)、medium(中)、large(大)。
也就是说en_core_web_sm、en_core_web_md、en_core_web_lg分别对应三种不同大小的nlp模型。主要差别在于准确率和加载时间
3 导入并加载模型
import spacy # 记在英文模型 nlp = spacy.load('en_core_web_lg')4 基本功能
接下来,我们来看一些SpaCy的基本功能。
4.1 文本处理和标记化
SpaCy可以将一个文本分割成独立的标记(tokens),包括单词、标点符号等。
import spacy # 记在英文模型 nlp = spacy.load('en_core_web_lg') # 处理文本 text = "Hello, welcome to the world of natural language processing." doc = nlp(text) # 打印标记化结果 for token in doc: print(token.text)结果如下:

4.2 词性标注
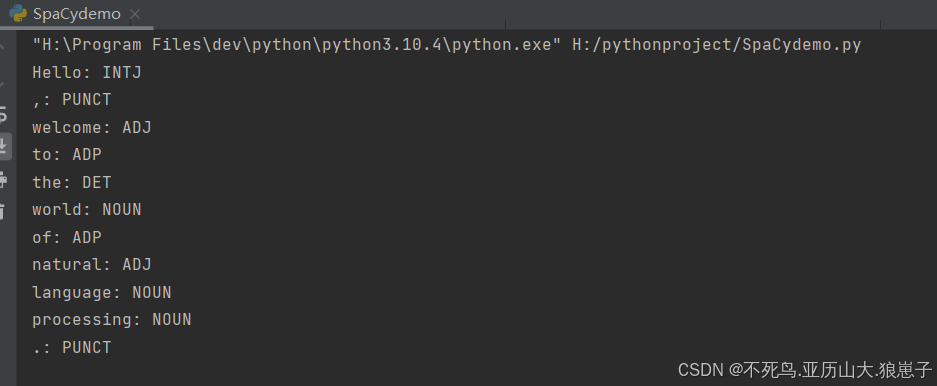
SpaCy能够识别每个词的词性(如名词、动词、形容词等)。
import spacy # 记在英文模型 nlp = spacy.load('en_core_web_lg') # 处理文本 text = "Hello, welcome to the world of natural language processing." doc = nlp(text) # 打印标记化结果 # for token in doc: # print(token.text) for token in doc: print(f'{token.text}: {token.pos_}')结果如下:
4.3 命名实体识别
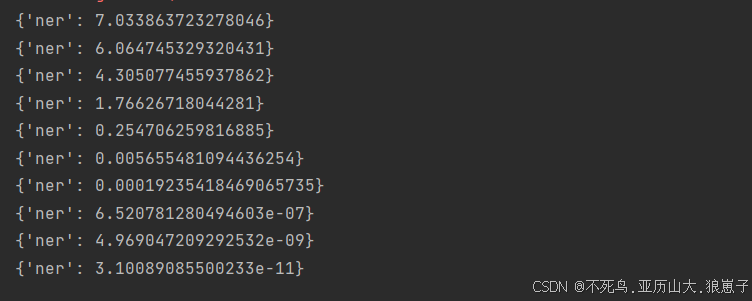
命名实体识别(NER)是指识别文本中具有特定意义的实体,如人名、地名、组织机构等。
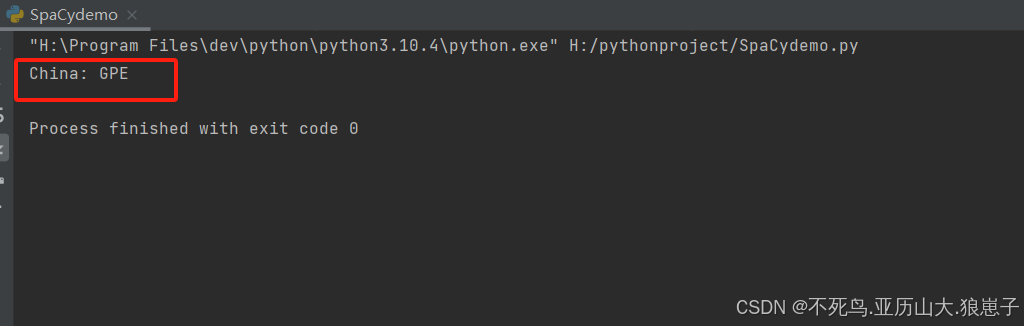
import spacy # 记在英文模型 nlp = spacy.load('en_core_web_lg') # 处理文本 text = "Long live China" doc = nlp(text) for ent in doc.ents: print(f'{ent.text}: {ent.label_}')结果如下:
4.4 依存解析
SpaCy能够进行句法依存解析,以理解每个词在句子中的语法关系。
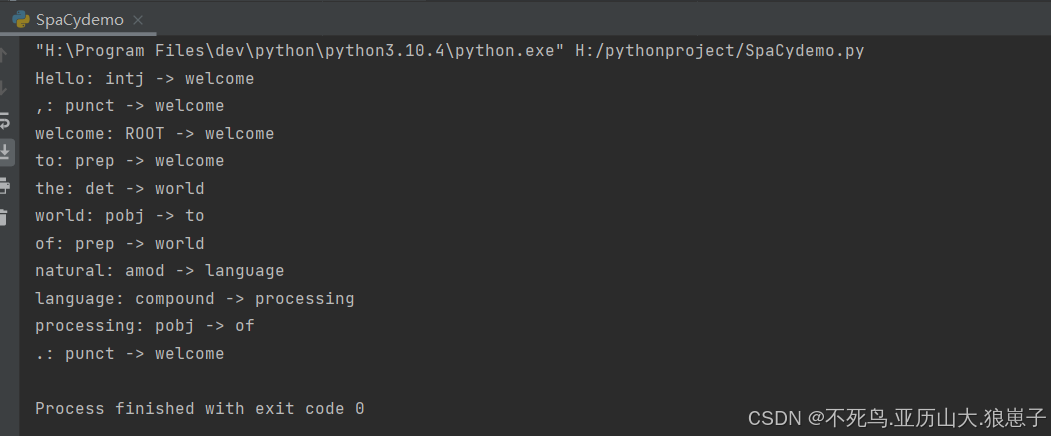
import spacy # 记在英文模型 nlp = spacy.load('en_core_web_lg') # 处理文本 text = "Hello, welcome to the world of natural language processing." doc = nlp(text) for token in doc: print(f'{token.text}: {token.dep_} -> {token.head.text}')结果如下:
5 高级功能
5.1 词向量
词向量(Word Vectors)是用于表示单词的高维向量,能够捕捉单词间的语义关系。SpaCy支持预训练的词向量,可以直接加载和使用。
这边我换了一个模型en_core_web_md,各位可以按照上面的步骤自行安装。
import spacy # 加载包含词向量的更大模型 nlp_large = spacy.load('en_core_web_md') # 获取词向量 doc_large = nlp_large("king queen man woman") for token in doc_large: print(f'{token.text}: {token.vector[:5]}')结果如下:

5.2 文本相似度
文本相似度计算是NLP中的常见任务之一,用于判断两个文本之间的相似程度。SpaCy的词向量可以用来计算句子或文档的相似度。
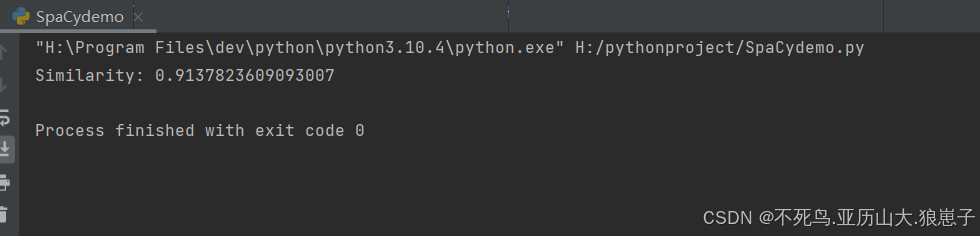
import spacy # 加载包含词向量的更大模型 nlp_large = spacy.load('en_core_web_md') doc1 = nlp_large("I love machine learning.") doc2 = nlp_large("I enjoy artificial intelligence.") similarity = doc1.similarity(doc2) print(f'Similarity: {similarity}') 结果如下:
5.3 自定义管道组件
SpaCy允许在其处理管道中添加自定义组件,以实现更个性化的处理。这对于特定任务非常有用。
import spacy from spacy.language import Language @Language.component("my_component") def my_component(doc): # Do something to the doc here print(f"Custom component processed:{doc}") return doc nlp = spacy.load('en_core_web_lg') nlp.add_pipe("my_component", name="print_info", last=True) print(nlp.pipe_names) doc = nlp("This is a sentence.")结果如下:

5.4 训练自定义模型
SpaCy还允许用户训练自己的自定义NER模型。这对于处理特定领域的文本非常有用。以下是一个简单的示例,展示了如何训练一个自定义NER模型。
import spacy import random from spacy.training.example import Example # 创建空白模型 nlp = spacy.blank("en") # 添加NER管道 ner = nlp.add_pipe("ner") # 添加自定义实体标签 ner.add_label("GADGET") # 定义训练数据 TRAIN_DATA = [ ("Apple releases new iPhone.", {"entities": [(14, 20, "GADGET")]}), ("Google launches new Pixel phone.", {"entities": [(21, 26, "GADGET")]}) ] # 开始训练 nlp.begin_training() for i in range(10): random.shuffle(TRAIN_DATA) losses = {} for text, annotations in TRAIN_DATA: doc = nlp.make_doc(text) example = Example.from_dict(doc, annotations) nlp.update([example], losses=losses) print(losses) # 测试自定义模型 doc = nlp("Amazon announces new Kindle.") for ent in doc.ents: print(ent.text, ent.label_)结果如下: