pytorch初学笔记(六):DataLoader的使用
目录
一、DataLoader介绍
1. DataLoader作用
2. 常用参数介绍
二、DataLoader的使用
1. 导入并实例化DataLoader
2. 具体使用
2.1 数据集中数据的读取
2.2 DataLoader中数据的读取
3. 使用tensorboard可视化效果
3.1 改变batchsize
3.2 改变drop_last
3.3 改变shuffle
一、DataLoader介绍
1. DataLoader作用
DataLoader是一个可迭代的数据装载器,组合了数据集和采样器,并在给定数据集上提供可迭代对象。可以完成对数据集中多个对象的集成。
2. 常用参数介绍
torch.utils.data — PyTorch 1.13 documentation
CLASS DataLoader
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False,
drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None,
generator=None, *, prefetch_factor=2, persistent_workers=False, pin_memory_device='')
先导概念介绍:
- Epoch: 所有训练样本都已输入到模型中,称为一个epoch
- Iteration: 一批样本(batch_size)输入到模型中,称为一个Iteration,
- Batchsize: 一批样本的大小, 决定一个epoch有多少个Iteration
常用的主要有以下五个参数:
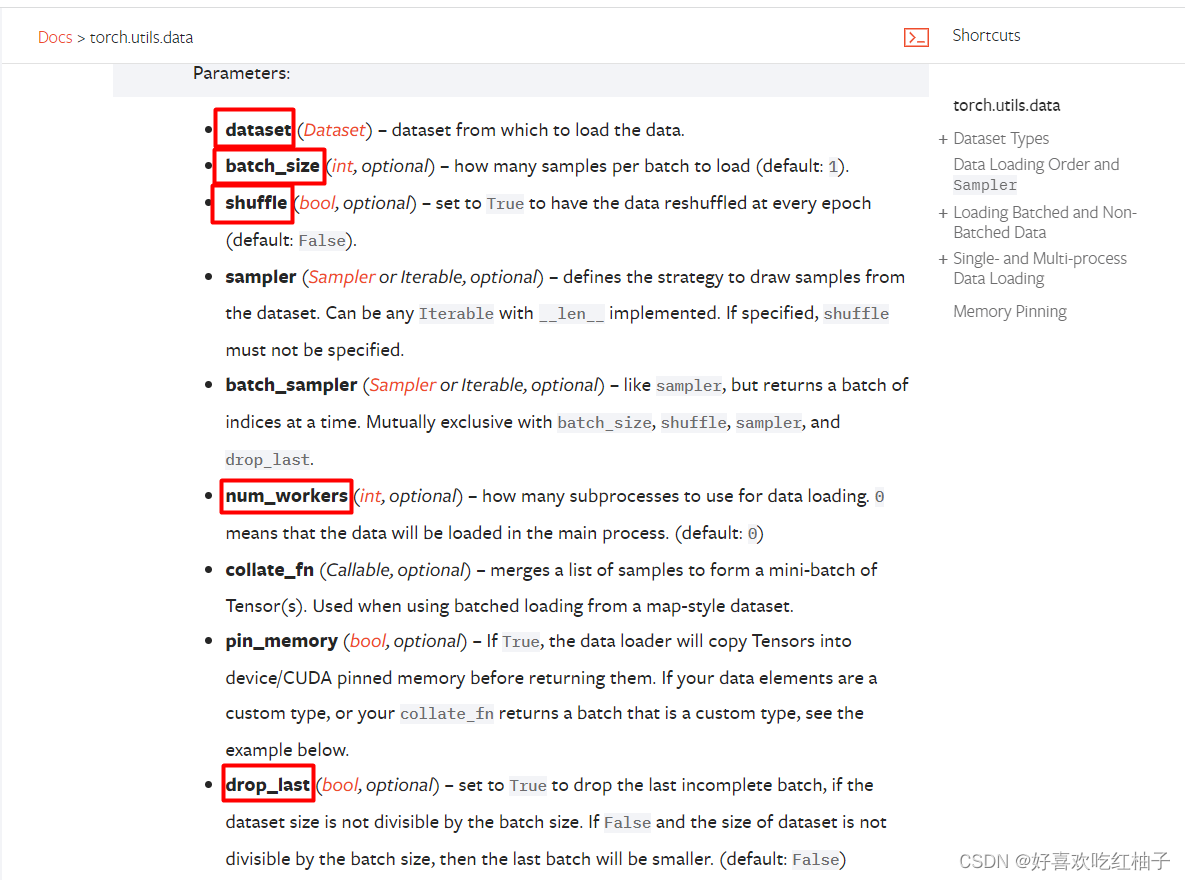
- dataset(数据集):需要提取数据的数据集,Dataset对象
- batch_size(批大小):每一次装载样本的个数,int型
- shuffle(洗牌):进行新一轮epoch时是否要重新洗牌,Boolean型
- num_workers:是否多进程读取机制
- drop_last:当样本数不能被batchsize整除时, 是否舍弃最后一批数据
二、DataLoader的使用
我们使用CIFAR10的测试数据集来完成DataLoader的使用。
1. 导入并实例化DataLoader
创建一个dataloader,设置批大小为4,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次。
#导入数据集的包 import torchvision.datasets #导入dataloader的包 from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter #创建测试数据集 test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor()) #创建一个dataloader,设置批大小为4,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次 test_dataloader = DataLoader(dataset=test_dataset,batch_size=4,shuffle=True,num_workers=0,drop_last=False)2. 具体使用
2.1 数据集中数据的读取
由于数据集中的数据已经被我们转换成了tensor型,我们用dataset[0]输出第一张图片,使用shape属性输出tensor类型的大小,target代表图片的标签。
img,target = test_dataset[0] print(img.shape,target)可以看到图片有RGB3个通道,大小为32*32,target为3。

2.2 DataLoader中数据的读取
在dataset中,每一个对象元组由一张图片对象img和一个标签target组成;
而dataloader中会分别对一个批次中的图片和标签进行打包,因此dataloader中,每一个对象由元组由batchsize张图片对象imgs和batchsize个标签targets组成。
- 对一个批次中的所有图片对象进行打包,形成一个对象,我们叫它imgs
- 对一个批次中所有的标签进行打包,形成一个对象,我们叫它targets

我们需要通过for循环来取出loader中的对象,loader中的对象个数=数据集中对象个数/batch_size,故应为10000/4=2500个对象。
核心代码:
for data in test_dataloader: imgs,targets = data print(imgs.shape) print(targets)
#导入数据集的包 import torchvision.datasets #导入dataloader的包 from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter #创建测试数据集 test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor()) #创建一个dataloader,设置批大小为4,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次 test_dataloader = DataLoader(dataset=test_dataset,batch_size=4,shuffle=True,num_workers=0,drop_last=False) #测试数据集中第一张图片对象 img,target = test_dataset[0] print(img.shape,target) #打印数据集中图片数量 print(len(test_dataset)) #loader中对象 for data in test_dataloader: imgs,targets = data print(imgs.shape) print(targets) #dataloader中对象个数 print(len(test_dataloader))
loader中的对象格式:
- imgs的维度变成了4*3*32*32,即四张图片,每张图片3个通道,每张图片大小为32*32。
- targets里有4个target,分别是四张图片的target。

loader中的对象个数:
2500个,数据集中图片个数为10000,10000/4=2500,验证正确。说明loader中数据按4个一组打包。

3. 使用tensorboard可视化效果
3.1 改变batchsize
修改数据集的batchsize为64,writer中调用的方法为add_images(),因为需要读取的图片有多张。
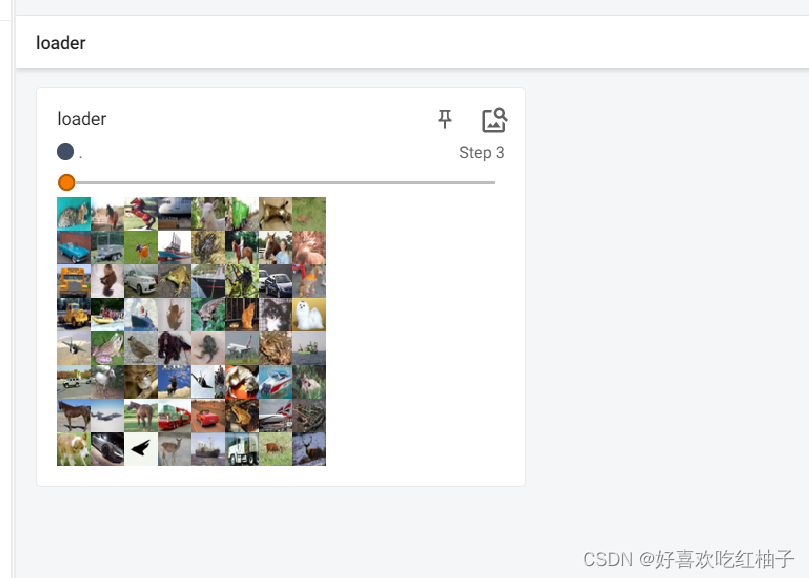
#导入数据集的包 import torchvision.datasets #导入dataloader的包 from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter #创建测试数据集 test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor()) #创建一个dataloader,设置批大小为64,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次 test_dataloader = DataLoader(dataset=test_dataset,batch_size=64,shuffle=True,num_workers=0,drop_last=False) writer = SummaryWriter("log") #loader中对象 step = 0 for data in test_dataloader: imgs,targets = data writer.add_images("loader",imgs,step) step+=1 writer.close()结果如下所示,可以看到一个step中有64张图片。
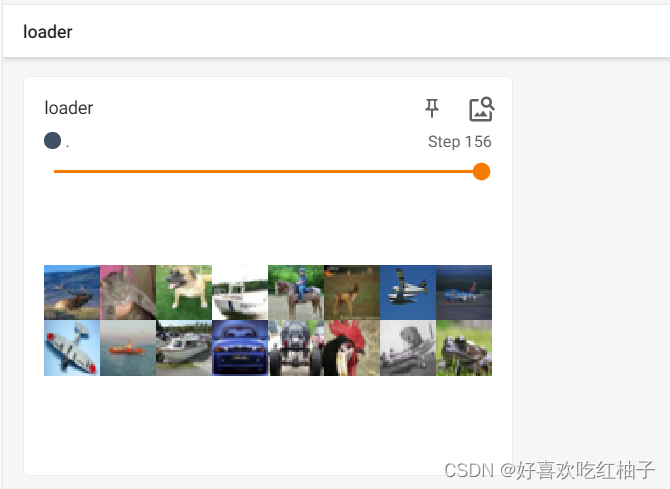
但是我们发现step156时只取了16张图片,是因为10000张图片每次取64张是不能整除的,因此最后剩下了16张,单独放在最后一个step中,对最后剩余数量的图片进行保留是因为我们设置的drop_last=False。
3.2 改变drop_last
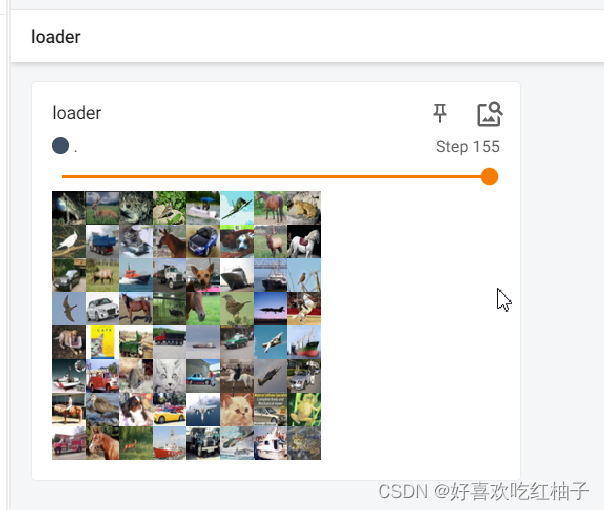
如果我们改变drop_last=True,则不会保留最后的16张图片,会被舍弃,只保留能被整除的批次。

结果如下所示,可以看到最后一步为155步,没了最后的16张图片,只保留了所有能整除的64的step。
3.3 改变shuffle
每一轮epoch之后就是分配完了一次数据,而shuffle决定了是否在新一轮epoch开始时打乱所有图片的属性进行分配。
在代码中epoch就是最外层的循环,假设我们的epoch=2,即需要分配两次数据:
- shuffle=TRUE代表第一轮循环结束后会打乱数据集中所有图片的顺序重新进行分配。
- shuffle=FALSE代表第一轮循环结束后不打乱数据集中所有图片的顺序,还是按原顺序进行分配。
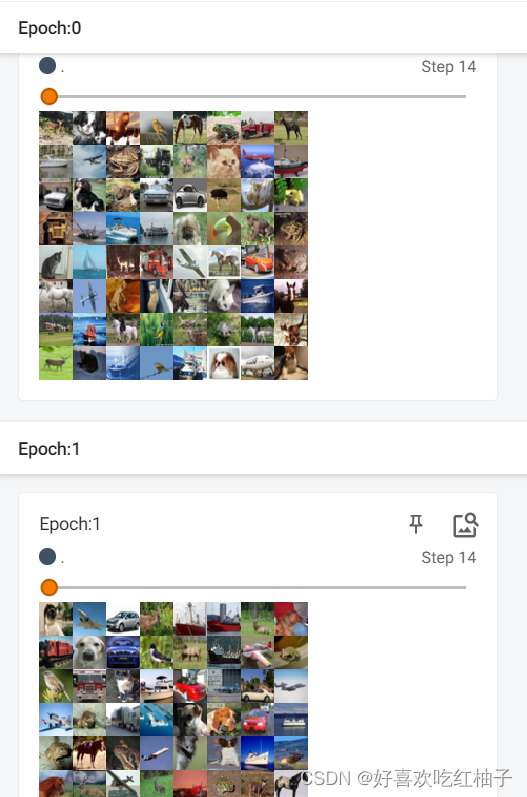
3.3.1 shuffle=False时
#导入数据集的包 import torchvision.datasets #导入dataloader的包 from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter #创建测试数据集 test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10",train=False,transform=torchvision.transforms.ToTensor()) #创建一个dataloader,设置批大小为64,每一个epoch重新洗牌,不进行多进程读取机制,不舍弃不能被整除的批次 test_dataloader = DataLoader(dataset=test_dataset,batch_size=64,shuffle=False,num_workers=0,drop_last=True) writer = SummaryWriter("log") #loader中对象 for epoch in range(2): step = 0 for data in test_dataloader: imgs, targets = data writer.add_images("Epoch:{}".format(epoch), imgs, step) step += 1 writer.close()可以看到epoch=0和epoch=1的每一个step中的图片都是分配的相同的,说明每一轮大循环开始前没有在数据集中重新打乱顺序。
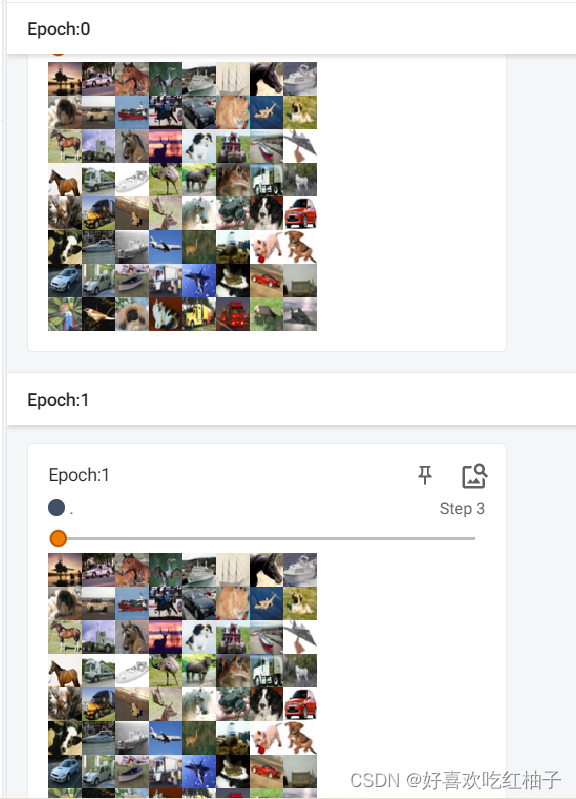
3.3.2 shuffle=True时

可以看到epoch=0和epoch=1的每一个step中的图片不同了,说明每一轮大循环开始前都在数据集中重新打乱了顺序。
参考资料
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)_翻滚的小@强的博客-CSDN博客_dataloader读取顺序
DataLoader的使用_哔哩哔哩_bilibili