解决NLP任务的T为什么可以应用于计算机视觉?
点击下方卡片,关注“小白玩转Python”公众号
几乎所有的自然语言处理任务,从语言建模和masked词预测到翻译和问答,在2017年Transformer架构首次亮相后都经历了革命性的变化。Transformer在计算机视觉任务中也表现出色,只用了2-3年的时间。在这篇文章中,我们探索了两种基础架构,它们使Transformer能够闯入计算机视觉的世界。
目录
视觉Transformer
主要思想
操作
混合架构
结构的丧失
结果
通过masked进行自监督学习
masked自编码视觉Transformer
主要思想
架构
最后评论和示例
视觉Transformer
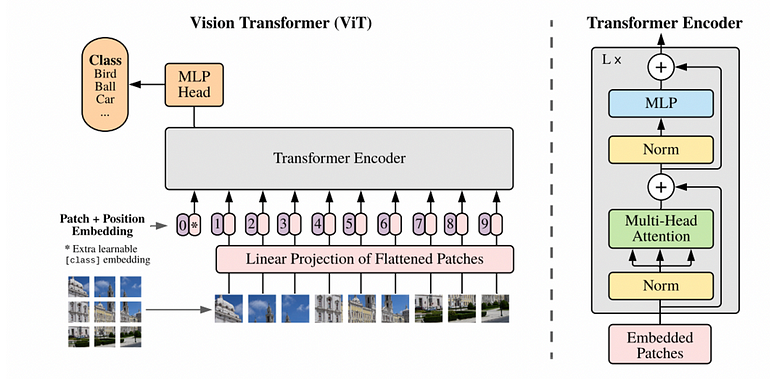
主要思想视觉Transformer的意图是将标准变换器架构泛化,以处理和从图像输入中学习。关于架构的一个主要思想是作者足够透明地强调了:
“受到NLP中Transformer扩展成功的启发,我们尝试直接将标准Transformer应用于图像,尽可能少地进行修改。”
操作可以非常字面地理解“尽可能少的修改”,因为他们几乎完全没有修改。他们实际修改的是输入结构:
在NLP中,Transformer编码器采用代表输入句子/段落的独热向量序列(或等价的标记索引),并返回可用于进一步任务(例如,分类)的上下文embedding向量序列。
为了泛化到计算机视觉,视觉Transformer采用代表输入图像的patch向量序列,并返回可用于进一步任务(例如,分类)的上下文embedding向量序列。
特别是,假设输入图像的维度为(n,n,3),要将其作为输入传递给Transformer,视觉Transformer的操作如下:
将其划分为k²个patch,k为某个值(例如,k=3),如图中所示。
现在每个patch将为(n/k,n/k,3),下一步是将每个patch展平为向量。
patch向量将是维度为3*(n/k)(n/k)的向量。例如,如果图像是(900,900,3),我们使用k=3,那么patch向量将具有维度300300*3,代表展平patch中的像素值。在论文中,作者使用k=16。因此,论文的名称为“一幅图像值16x16个词:大规模图像识别的Transformer”,而不是提供代表单词的独热向量,他们代表代表图像patch的像素向量。
其余的操作与原始Transformer编码器保持不变:
这些patch向量通过一个可训练的embedding层传递
向每个向量添加位置embedding,以保持图像中的空间信息
输出是num_patches编码器表示(每个补丁一个),可用于对补丁或图像级别进行分类
更常见的(如在论文中),在表示前添加CLS标记,相应的用于对整个图像进行预测(类似于BERT)
Transformer解码器呢?
记住它就像Transformer编码器;不同之处在于它使用masked自注意而不是自注意(但相同的输入签名保持不变)。无论如何,你应该很少使用仅解码器的Transformer架构,因为简单地预测下一个patch可能不是非常感兴趣的任务。
混合架构作者还提到,可以以CNN特征图而不是图像本身作为输入来形成混合架构(CNN将输出传递给视觉Transformer)。在这种情况下,我们将输入视为通用的(n,n,p)特征图,patch向量将具有维度(n/k)*(n/k)*p。
结构的丧失你可能会想到这种架构不应该这么好,因为它将图像视为线性结构,而它并不是。作者试图通过提到来描绘这是有意为之:
The two-dimensional neighborhood structure is used very sparingly…position embeddings at initialization time carry no information about the 2D positions of the patches and all spatial relations between the patches have to be learned from scratch
我们将看到Transformer能够学习这一点,这在其实验中的好表现中得到了证明,更重要的是,下一篇论文中的架构。
结果结果的主要结论是,视觉Transformer在小数据集上往往不能超越基于CNN的模型,但在大数据集上接近或超越基于CNN的模型,无论如何都需要显著减少计算量:

在这里我们可以看到,对于JFT-300M数据集(拥有3亿张图像),在该数据集上预训练的ViT模型超越了基于ResNet的基线,同时大大减少了预训练所需的计算资源。可以看到,他们使用的较大的视觉Transformer(ViT-Huge,有632M参数和k=16)使用了ResNet模型所用计算量的约25%,并且仍然超越了它。性能甚至在使用仅<6.8%计算量的ViT-Large时并没有降低那么多。
与此同时,其他人也暴露了结果,当在仅有130万图像的ImageNet-1K上训练时,ResNet的表现明显更好。
通过Masking进行自监督学习作者对自监督的 masked patch 预测进行了初步探索,模仿BERT中使用的masked语言建模任务(即 masked patch并尝试预测它们)。
“We employ the masked patch prediction objective for preliminary self-supervision experiments. To do so we corrupt 50% of patch embeddings by either replacing their embeddings with a learnable [mask] embedding (80%), a random other patch embedding (10%) or just keeping them as is (10%).”
通过自监督预训练,他们较小的ViT-Base/16模型在ImageNet上达到了79.9%的准确率,比从头开始训练有2%的显著提高。但仍然比有监督预训练落后4%。
Masked 自编码视觉Transformer
 主要思想正如我们从视觉Transformer论文中看到的,通过masked输入图像中的patch进行预训练所获得的收益并不像在普通的NLP中那样显著,那里masked预训练可以在一些微调任务中取得最先进的结果。
主要思想正如我们从视觉Transformer论文中看到的,通过masked输入图像中的patch进行预训练所获得的收益并不像在普通的NLP中那样显著,那里masked预训练可以在一些微调任务中取得最先进的结果。
这篇论文提出了一种涉及编码器和解码器的视觉Transformer架构,当使用masked进行预训练时,与基础视觉Transformer模型相比,可以获得显著的改进(与以有监督方式训练基础尺寸视觉Transformer相比,改进高达6%)。

这是一些示例(输入,输出,真实标签)。从某种意义上说,它是一个自编码器,因为它试图在填充缺失patch的同时重建输入。
架构他们的编码器只是我们前面解释的普通视觉Transformer编码器。在训练和推理中,它只采用“观察到”的patch。与此同时,他们的解码器也是普通的视觉Transformer编码器,但它采用:
缺失patch的masked标记向量
已知patch的编码器输出向量
所以对于图像[[A, B, X], [C, X, X], [X, D, E]],其中X表示缺失的patch,解码器将采用补丁向量序列[Enc(A), Enc(B), Vec(X), Vec(X), Vec(X), Enc(D), Enc(E)]。Enc返回给定patch向量的编码器输出向量,X是表示缺失标记的向量。
解码器中的最后一层是一个线性层,它将上下文embedding(由解码器中的视觉Transformer编码器产生)映射到与patch大小相等长度的向量。损失函数是均方误差,它计算原始patch向量和这一层预测的向量之间的差异的平方。在损失函数中,我们只关注由于masked标记而进行的解码器预测,并忽略对应于存在的预测(即,Dec(A),Dec(B),Dec(C)等)。
最后评论和示例作者建议在图像中masked大约75%的patch,这可能令人惊讶;BERT只会masked大约15%的单词。他们这样解释:
“Images,are natural signals with heavy spatial redundancy — e.g., a missing patch can be recovered from neighboring patches with little high-level understanding of parts, objects, and scenes. To overcome this difference and encourage learning useful features, we mask a very high portion of random patches.”
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除