深度学习训练基于Pod和RDMA

目录
编辑
引言
RDMA技术概述
InfiniBand
iWARP
RoCE
Pod和容器化环境
深度学习训练与RDMA结合
MPI和RDMA
深度学习框架与RDMA
实战:基于Pod和RDMA的深度学习训练
环境准备
步骤
YAML
性能和优势
结论
引言
随着深度学习在人工智能领域的快速发展,其在计算机视觉、自然语言处理、自动驾驶等多个领域都展现了强大的能力。然而,单个GPU的计算能力和内存大小已无法满足大规模深度学习训练的需求。为了使用更多的计算能力并缩短训练时间,分布式训练已成为解决大规模深度学习问题的关键方法。其中,RDMA(Remote Direct Memory Access)网络因其极高带宽与极低延迟的特性,在分布式训练中发挥着重要作用。本文将详细介绍如何在基于Pod的容器化环境中,利用RDMA网络进行深度学习训练。
RDMA技术概述
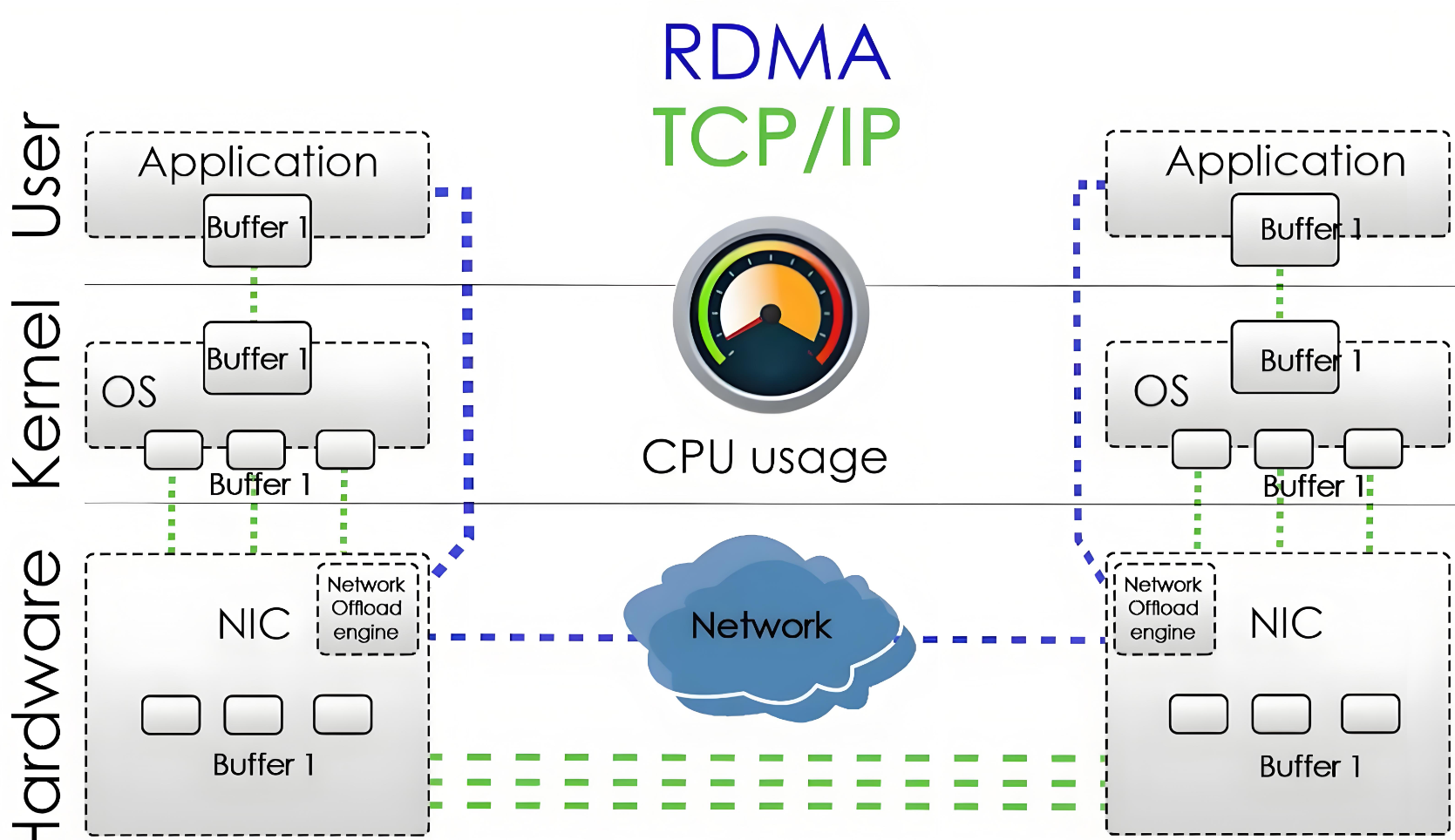
RDMA技术提供了一种跨过CPU、操作系统和TCP/IP协议栈,直接访问远端内存到本地内存的方式。它具有低延迟和低CPU使用率的优点。RDMA技术主要有三种实现方式:InfiniBand、iWARP和RoCE。其中,RoCE因其综合性能较好、兼容性较优、价格普惠而受到广泛认可。
InfiniBand
InfiniBand设计之初就考虑了RDMA,从硬件级别保证可靠传输,但网卡和交换机的价格昂贵,兼容性差。
iWARP
iWARP基于TCP或SCTP实现RDMA,对网络设备的要求较少,但TCP连接需要占用内核资源,市场认可度较低。
RoCE
RoCE基于Ethernet实现RDMA,消耗的资源比iWARP少,支持的特性比iWARP多,需要FCoE实现可靠传输。RoCE的综合性能较好,价格普惠,且最新版本RoCEv2支持IPv4和IPv6,具有良好的可扩展性和应用前景。
Pod和容器化环境
在容器化集群环境中运行分布式模型训练时,通常使用Pod作为容器的基本单位。Pod是Kubernetes中的最小部署单元,可以包含一个或多个容器。在基于Pod的环境中,容器网络接口(CNI)用于实现容器间的网络通信。
深度学习训练与RDMA结合
MPI和RDMA
MPI(Message Passing Interface)是一门比较老的技术,在高性能计算界几乎是标配,其对RDMA优化较好。MPI最大的优势有两点:一是MPI有一个高性能allreduce的实现,底层实现了tree aggregation;二是程序可以无缝移植到异构高性能计算环境,例如InfiniBand。
深度学习框架与RDMA
已有的深度学习框架大部分是基于传统的TCP/IP技术实现数据通信,在向RDMA网络移植时,有不同的技术方法可以选择:IPoIB、MPI以及RDMA Verbs。在这三种方法的选择上,需要在易用性和性能方面做出权衡。不合适的决策可能导致复杂且难以维护的代码实现。
例如,MXNet是一个模块化的深度学习框架,通过修改MXNet使其可以在RDMA网络上运行,可以将深度学习训练过程的通信部分划分为三个层次:点对点通信、Allreduce通信以及端到端训练。依据这种层次划分,可以提出增量式的移植与优化方法,使得性能的提升更有据可循。实验结果表明,在使用100个GPU时,并行效率可以从IPoIB版本的53%提升到96%,接近线性加速。
实战:基于Pod和RDMA的深度学习训练
环境准备
- 硬件环境:
- 服务器:若干台支持RDMA的服务器
- 网卡:支持RoCE或InfiniBand的网卡
- 交换机:支持RoCE或InfiniBand的交换机
- 软件环境:
- Kubernetes集群:用于管理Pod和容器
- 深度学习框架:如TensorFlow、PyTorch或MXNet
- MPI库:如mvapich2或MPICH
- 容器网络接口(CNI)插件:支持RDMA的CNI插件
步骤
- 部署Kubernetes集群:
- 在服务器上安装Kubernetes,并配置网络插件以支持RDMA。
- 配置RDMA网络:
- 在服务器上安装并配置RDMA网卡和驱动。
- 配置交换机以支持RDMA网络。
- 部署深度学习框架:
- 在Kubernetes集群中部署深度学习框架,并配置其使用RDMA进行通信。
- 编写分布式训练代码:
- 使用MPI编写分布式训练代码,并配置其使用RDMA进行通信。
- 将代码打包成容器镜像,并上传到Kubernetes集群中。
- 创建Pod并启动训练:
- 使用Kubernetes的YAML文件定义Pod,并指定使用RDMA网络。
- 启动Pod并开始进行分布式训练。
YAML
在Kubernetes中,要配置一个使用GPU和RDMA网络的Pod,需要创建一个YAML文件来定义Pod的规格。以下是一个示例YAML文件,它定义了一个使用example-gpu-dnn镜像的Pod,并假设你已经有一个支持RDMA的网络插件在Kubernetes集群中运行。
apiVersion: v1 kind: Pod metadata: name: example-gpu-dnn-pod labels: app: example-gpu-dnn spec: containers: - name: example-gpu-dnn-container image: example-gpu-dnn:latest imagePullPolicy: IfNotPresent resources: limits: nvidia.com/gpu: 1 # 请求1个GPU volumeMounts: - name: rdma-device-plugin mountPath: /var/lib/kubelet/device-plugins/ volumes: - name: rdma-device-plugin hostPath: path: /var/lib/kubelet/device-plugins/ type: Directory nodeSelector: kubernetes.io/hostname: your-node-label # 指定运行Pod的节点,需要替换为实际的节点标签 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: feature.node.kubernetes.io/network-rdma.capable operator: In values: - "true" # 确保Pod被调度到支持RDMA的节点上在这个YAML文件中,做了以下几件事情:
- 定义了Pod的元数据和规格。
- 指定了容器使用的镜像
example-gpu-dnn:latest。 - 设置了资源限制,请求1个GPU。
- 挂载了RDMA设备插件的目录,以便容器可以访问RDMA设备。
- 使用了
nodeSelector来指定Pod应该运行在哪个节点上(需要替换为实际的节点标签)。 - 使用了
affinity来确保Pod被调度到支持RDMA的节点上。
注意,需要根据实际环境和需求来调整这个YAML文件。特别是nodeSelector和affinity部分,需要确保它们与你的Kubernetes集群的配置相匹配。此外,如果RDMA设备插件不在/var/lib/kubelet/device-plugins/目录下,需要相应地修改volumeMounts和volumes部分。
性能和优势
通过基于Pod和RDMA的深度学习训练,可以获得以下性能和优势:
- 高通信带宽:RDMA网络提供极高的通信带宽,可以加速数据在节点之间的传输。
- 低延迟:RDMA网络具有极低的延迟,可以减少通信过程中的等待时间。
- 低CPU使用率:RDMA网络绕过CPU进行数据传输,可以降低CPU的使用率。
- 可扩展性:基于Pod的容器化环境可以轻松扩展训练规模,支持更多的GPU和节点。
结论
通过结合Pod和RDMA技术,可以在容器化环境中实现高效、可扩展的深度学习训练。RDMA网络提供的高带宽、低延迟和低CPU使用率特性,可以显著提升分布式训练的性能。未来,随着RDMA技术的不断发展和普及,基于Pod和RDMA的深度学习训练将成为大规模深度学习应用的重要方向。