Lottery 分布式抽奖(个人向记录总结)
1.搭建(DDD+RPC)架构
DDD——微服务架构(微服务是对系统拆分的方式)
(Domain-Driven Design 领域驱动设计)
DDD与MVC同属微服务架构
是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建模,以应对系统规模过大时引起的软件复杂性的问题。
DDD分层
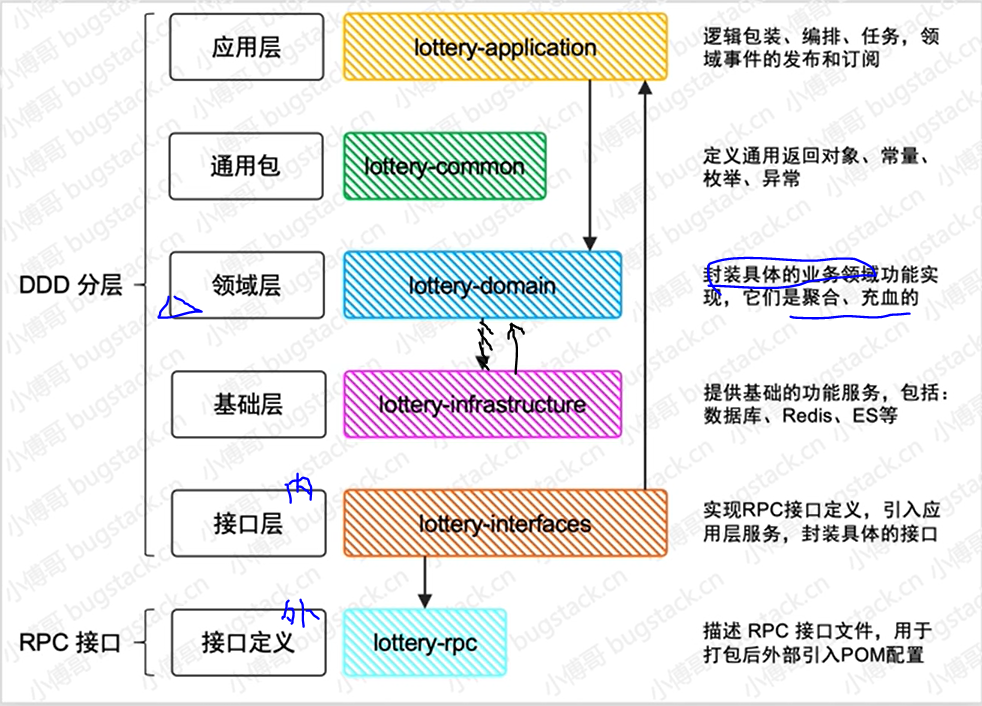
RPC接口:对外提供接口调用整个服务
DDD分层:(箭头是剪头尾对头的引用)
- 接口层:对内提供接口【接口调用应用层,应用层调用领域层】
- 基础层:对数据仓储服务【基础层引用领域层,领域层来定义仓储服务的接口,基础层去做仓储服务的实现】
- 领域层:(核心)封装具体业务功能
- 通用层:返回对象、枚举
- 应用层:逻辑包装
MVC与DDD区别
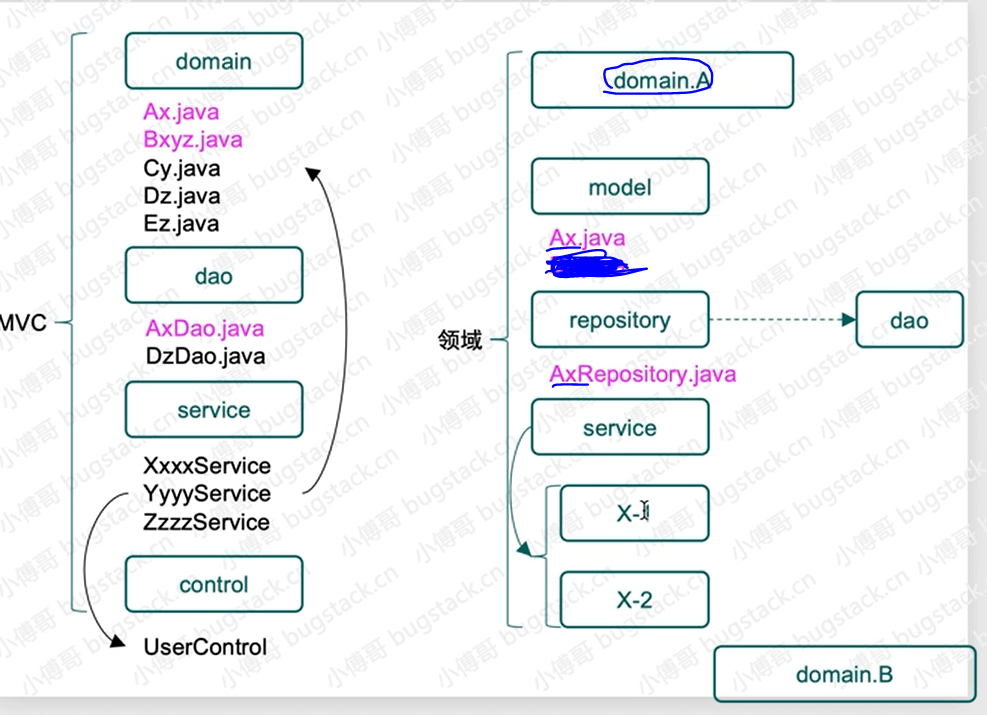
驱动设计模式:
具体来说,对于这么一个抽奖领域domain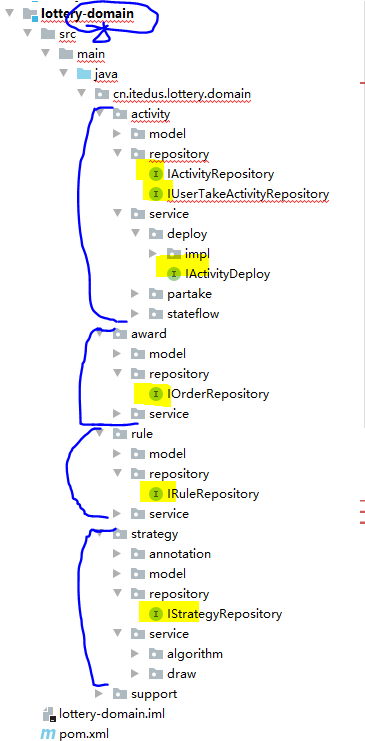
【上图repository包】这里只定义接口,在基础层infrastructure进行实现。
model,用于提供vo、req、res 和 aggregates 聚合对象。
repository,对数据库,其实也就是对Mysql、Redis等数据的统一包装。
service,是具体的业务领域逻辑实现层,在这个包下定义了algorithm抽奖算法实现和具体的抽奖策略包装 draw 层,对外提供抽奖接口 IDrawExec#doDrawExec。
也就是说,这些model里的这些对象都是用于服务自己的领域,不会去服务其他领域。
为什么使用斐波那契散列索引(感觉有点怪多余)
为了尽量均匀散列减少碰撞
使用斐波那契散列索引,使用斐波那契计算能起到不错的散列效果。
2.模版模式处理抽奖流程
职责分离,标准定义。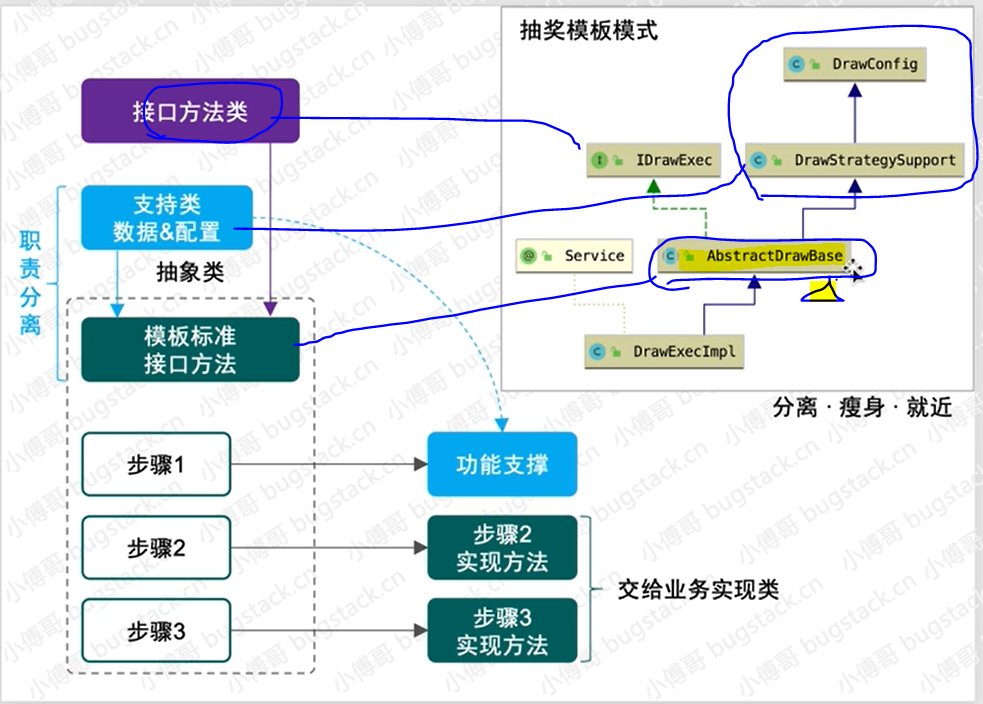
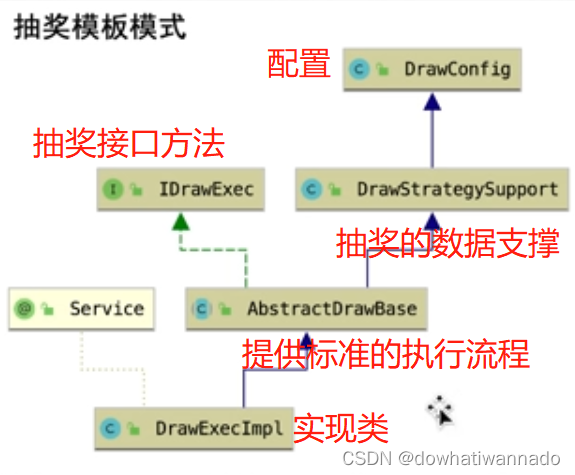
配置类:配置抽奖策略
抽象接口方法:【抽奖执行接口】
抽奖数据支撑:支撑类继承配置类里的方法,并提供数据服务
抽象类:提供标准的执行流程***【模板】(上面几个部分这么分就是为了将抽象类瘦身,将标准流程)
实现类:针对情景的具体业务实现*(将会在这@Service("drawExec")业务逻辑的实现层)
整个实现过程流式:这样将接口间的职责进行分离,将接口间的功能职责分离;
模板模式应用
本章节最大的目标在于把抽奖流程标准化,需要考虑的一条思路线包括:
- 1根据入参策略ID获取抽奖策略配置
- 2校验和处理抽奖策略的数据初始化到内存
- 3获取那些被排除掉的抽奖列表,这些奖品可能是已经奖品库存为空,或者因为风控策略不能给这个用户薅羊毛的奖品
- 4执行抽奖算法
- 5包装中奖结果
1,2是基础配置,3,4是需要根据自身具体业务实现——所以定义抽象类等具体业务去实现
模板方法定义好标准流程后,其他开发人员格子各自开发自己的业务,不会破坏整体的开发结构。
关于模版模式的核心点在于由抽象类定义抽象方法执行策略,也就是说父类规定了好一系列的执行标准,这些标准的串联成一整套业务流程
遇到适合的场景使用这样的设计模式也是非常方便的,因为他可以控制整套逻辑的执行顺序和统一的输入、输出,而对于实现方只需要关心好自己的业务逻辑即可
3.简单工厂搭建发奖domain
本质:就是为了简化if else判断不同类型使用不同的代码处理, 使用map将不同的类型和对应的代码联系到一起。让代码变得更整洁。
工厂模式:是一种创建型设计模式,在父类中提供一个创建对象的方法,允许子类决定实例化对象的类型。
奖品服务交给工厂,工厂提供对外的发奖服务,由工厂进行统一包装【减少使用ifelse,使用map将奖品类型map过来】。
“发放奖品”工厂作用:外部提供一个奖品类型,工厂提供这个奖品类型需要提供什么样的服务去处理。
4.状态模式完成状态流转
状态模式(State Pattern):属于行为型模式,是允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
在软件开发中,经常需要根据对象的不同状态进行不同的逻辑处理,通常情况下我们会使用if-else/switch-case进行判断处理,但是大量的逻辑判断语句会使程序臃肿,不利用程序的扩展与维护。这时可以将不同状态下的逻辑处理抽象分离出来,使程序更加健壮。状态模式这批篇博客例子挺好
【这里也是用的map,将对应状态】
怎么使用的:
传一个状态实例,实现类里调用对应状态的要进行的操作。
5.策略模式选择生成ID算法
策略模式属于行为模式的一种,一个类的行为或算法可以在运行时进行更改。
使用策略模式把三种生成ID的算法进行统一包装,由调用方根据不同的场景来选择出适合的ID生成策略。
这里三种方式生成ID雪花算法、随机算法、日期算法,分别用在订单号、策略ID、活动号的生成上。【使用map】
优惠策略的选取也是使用策略模式详见 实战策略模式「模拟多种营销类型优惠券,折扣金额计算策略场景」
6.分库分表来缓解缓存压力
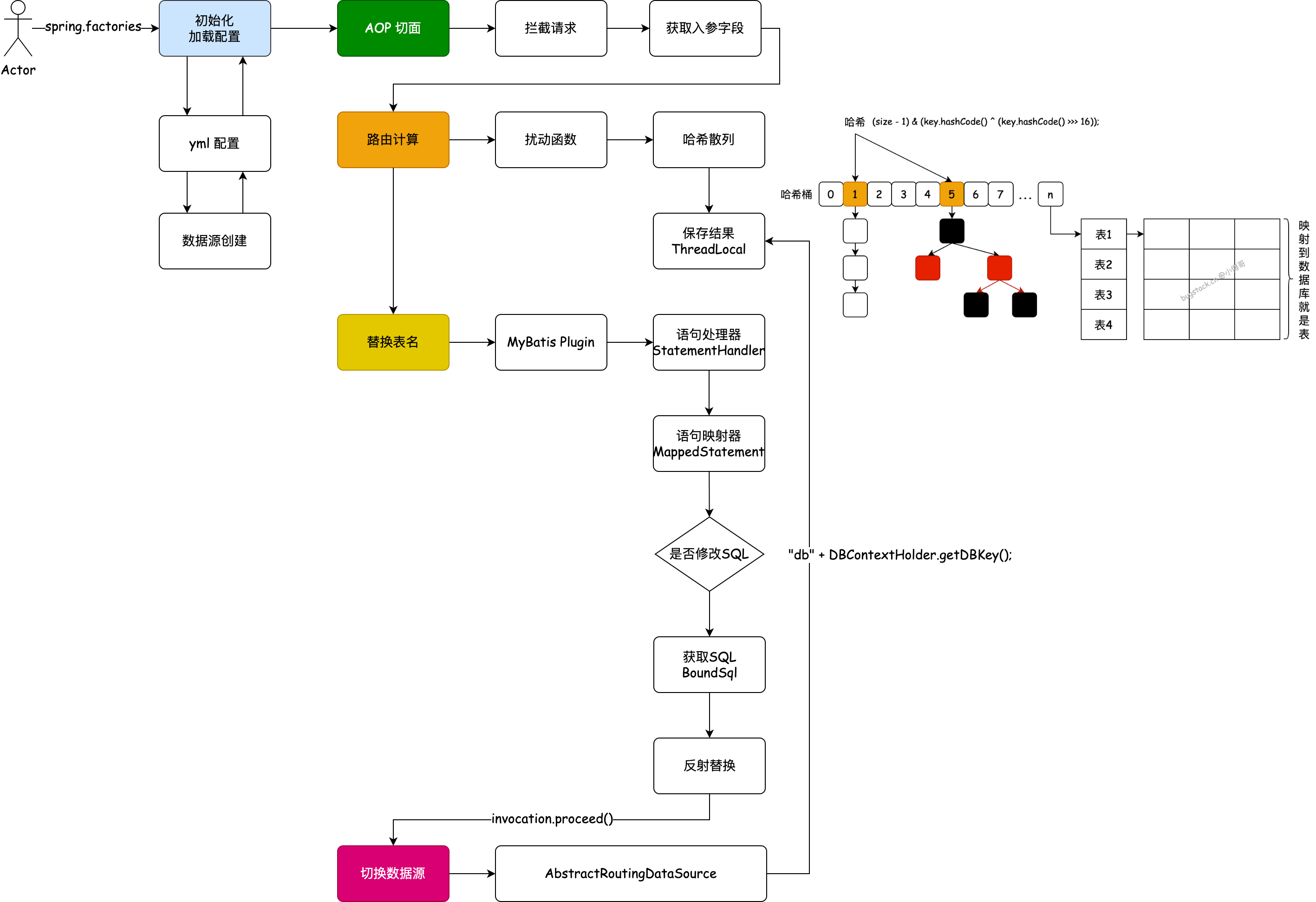
基于 HashMap 核心设计原理,使用哈希散列+扰动函数的方式,把数据散列到多个库表中的组件。
由于业务体量较大,数据增长较快,所以需要把用户数据拆分到不同的库表中去,减轻数据库压力。
分库分表操作主要有垂直拆分和水平拆分:
- 垂直拆分:指按照业务将表进行分类,分布到不同的数据库上,这样也就将数据的压力分担到不同的库上面。最终一个数据库由很多表的构成,每个表对应着不同的业务,也就是专库专用。
- 水平拆分:如果垂直拆分后遇到单机瓶颈,可以使用水平拆分,区别是:垂直拆分是把不同的表拆到不同的数据库中,而本章节需要实现的水平拆分,是把同一个表拆到不同的数据库中。如:user_001、user_002
这里实现的是水平拆分的路由设计。
大致思路:
分库:通过AOP方式,拦截@dbRouter注解,(将用户ID、订单ID)通过一致性Hash计算目标数据源,缓存到Threadlocal里。配置DynamicDataSource,从Threadlocal中读取目标数据源key执行切换。
分表:利用MyBatis拦截器,在@DBRouterStrategy(true)标记的类里,从Threadlocal中读取目标ID,补全SQL语句。
计算落到那个库中然后动态切换数据源;
计算落到那个表中然后mybatis拦截器,拦截到对应的sql语句然后添加上具体的表单号。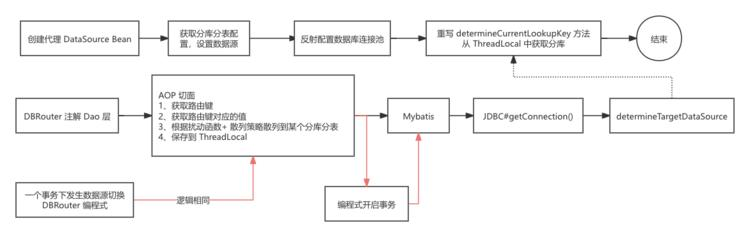
只分库部分表只加@DBRouter路由,就到对应的
既分库又分表需要再@Mapper下加@DBRouterStrategy(splitTable = true)
(1)数据库路由设计要包括哪些技术知识点
- AOP 切面拦截的使用:这是因为需要给使用数据库路由的方法做上标记,便于处理分库分表逻辑。
- 数据源的切换操作:既然有分库那么就会涉及在多个数据源间进行链接切换,以便把数据分配给不同的数据库。
- 数据库表寻址操作:一条数据分配到哪个数据库,哪张表,都需要进行索引计算。在方法调用的过程中最终通过 ThreadLocal 记录。
- 数据散列的操作:让数据均匀的分配到不同的库表中去。
(2)为什么分库分表?
分库分表基本是单表200万,才分,你们为什么分库分表?
- 我们分库分表用的非常熟。但不能为了等到系统到了200万数据,才拆。那么工作量会非常大
- 我们的做法是,因为有成熟方案,所以前期就分库分表了。但,为了解释服务器空间。所以把分库分表的库,用服务器虚拟出来机器安装。这样即不过多的占用服务器资源,也方便后续数据量真的上来了,好拆分。
- 同时,抽奖系统,是瞬时峰值较高的系统,历史数据不一定多。所以我们希望,用户可以**快速的检索到个人数据,做最优响应。**因为大家都知道,抽奖这东西,push发完,基本就1~3分钟结束,10分钟人都没了。所以我们这也是做了分库分表的理由。
(3)库表数量设置为什么是2的n次幂
算法基于HashMap,分表数量也要基于HashMap从而更好的散列,避免id字段都分配到一个库表上去不均匀。
7. 编程式事务领取活动开发
由于多次切换数据源导致使用注解式的事务失效,所以这里使用编程式事务,在开始之前将路由切换好。
好处:不用等抛出异常再事务回滚
扩展路由组件,拆解路由策略满足编程式路由配合编程式事务一起使用。
使用模板模式开发领取活动领域,因为在领取活动中需要进行活动的日期、库存、状态等校验,并处理扣减库存、添加用户领取信息、封装结果等一系列流程操作,因此使用抽象类定义模板模式更为妥当。
通过编程式事务将参与次数表的活动次数扣减与写入用户领取活动表连在一起合并为一个事务。
每次写入参与活动时,会生成uuid用来防重,由uid(用户ID)+活动id+参与次数组成
8.应用层编排抽奖过程
领域层:写入一些功能
应用层:流程编排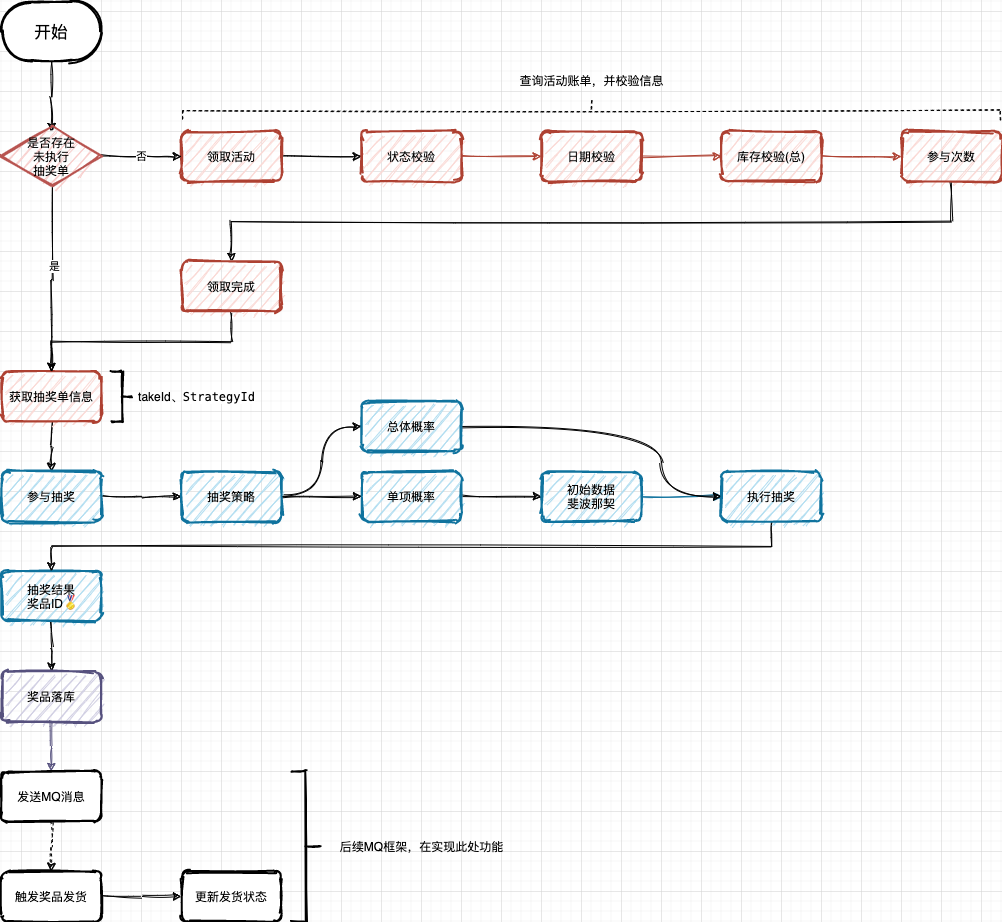
(1)抽奖整个活动过程的流程编排,主要包括:对活动的领取、对抽奖的操作、对中奖结果的存放,以及如何处理发奖,MQ触发发奖流程。
对于每一个流程节点编排的内容,都是在领域层开发完成的,而应用层只是做最为简单的且很薄的一层。其实这块也很符合目前很多低代码的使用场景,通过界面可视化控制流程编排,生成代码。
(2)给user_take_activity表增加state【活动单使用状态 0未使用、1已使用】用于记录当前领取的活动有没有执行抽奖。目的是当抽奖过程中发生失败(系统,网络等原因),还触发到数据库中,这时用于保留未使用抽奖的状态。
同时,state还可以将两张表做一个幂等性的事务处理。
(幂等性问题就是同一个接口,多次发出同一个请求,必须保证操作只执行一次。)
(3)将user_take_activity表和 user_strategy_export_00(0-3) 表做一个幂等性的事务:
用户领取活动表user_take_activity使用takeID生成user_strategy_export_表的UUID来防重,达到一次参加活动只生成一个抽奖单。
UUID设置了unique唯一约束
抽奖单的UUID由领取活动表的takeid而来。
9.规则引擎,量化人群参与活动
使用组合模式搭建用于量化人群的规则引擎,用于用户参与活动之前,通过规则引擎过滤性别、年龄、首单消费、消费金额、忠实用户等各类身份来量化出具体可参与的抽奖活动。通过这样的方式控制运营成本和精细化运营。
(1)增加规则引擎开发需要的相关的配置类表:rule_tree规则树(包括名字,描述等)'、rule_tree_node(节点类型,值,规则)、rule_tree_node_line(节点连接情况from,to)
(2)运用组合模式搭建规则引擎领域服务,包括:logic 逻辑过滤器、engine 引擎执行器
(3)修改 lottery-infrastructure 基础层中仓储实现类更为合适的的注解为 @Repository 包括: ActivityRepository、RuleRepository、StrategyRepository、UserTakeActivityRepository
(1)为什么使用组合模式?组合模式是一种结构型模式,它将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
如果使用if-else语句去判断是哪种数据会比较麻烦且代码量大大增加,对以后的维护增加了难度,使用组合模式解决了这个问题,让代码更加干净整洁,为后续添加更多决策信息的时候更加轻便,且维护起来更加简单。
(2)这个规则树为啥要放到数据库里啊,直接写在代码里判断不行么?
放在数据库可以动态化配置,要的是这个。否则后面调整,只能改代码了。
决策树: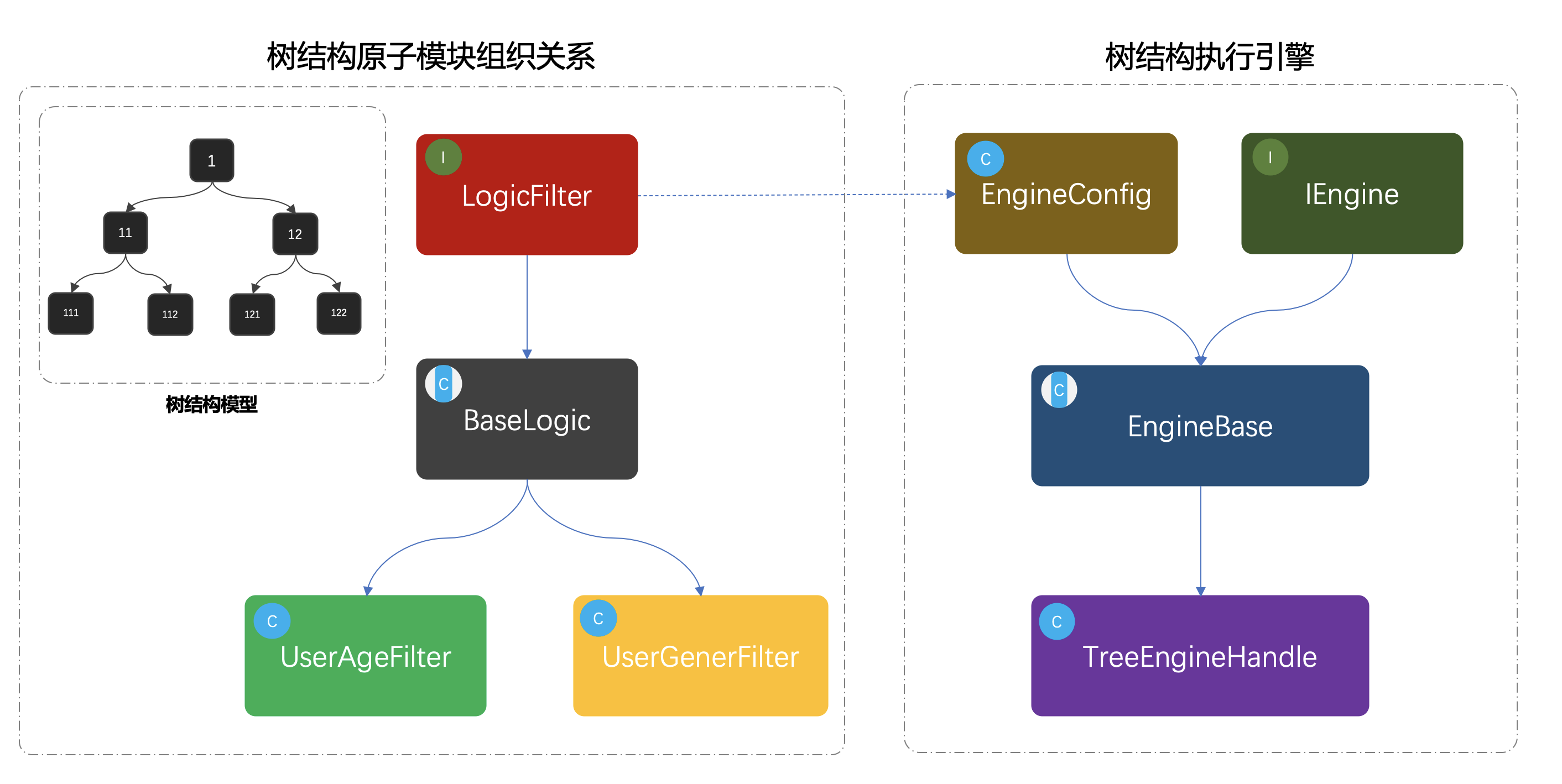
树结构原子模块的组织关系:开发每个节点(过滤器)的逻辑这每一个节点是用来作比对的
节点开发完后,执行引擎根据规则来串联节点关系得到决策树,最后遍历决策树得到过滤后的活动。
10.门面接口封装和对象转换
在领域层编写各种活动参与过程,抽奖过程,规则过程
在应用层进行逻辑包装
在接口层对外部提供应用
描述:在 lottery-interfaces 接口层创建 facade 门面模式 包装抽奖接口,并在 assembler 包 使用 MapStruct 做对象转换操作处理。
- 补充 lottery-application 应用层对规则引擎的调用,添加接口方法 IActivityProcess#doRuleQuantificationCrowd
- 删掉 lottery-rpc 测试内容,新增加抽奖活动展台接口 ILotteryActivityBooth,并添加两个抽奖的接口方法,普通抽奖和量化人群抽奖。
- 开发 lottery-interfaces 接口层,对抽奖活动的封装,并对外提供抽奖服务。
对象转换
背景:以 DDD 设计的结构框架,在接口层和应用层需要做防污处理,也就是说不能直接把应用层、领域层的对象直接暴露处理,因为暴露出去可能会随着业务发展的过程中不断的添加各类字段,从而破坏领域结构。那么就需要增加一层对象转换,也就有了 vo2dto、dto2vo 的操作。但这些转换的字段又基本都是重复的,在保证性能的情况下,一些高并发场景就只会选择手动编写 get、set,但其实也有很多其他的方式,转换性能也不差,这里我们列举一下。
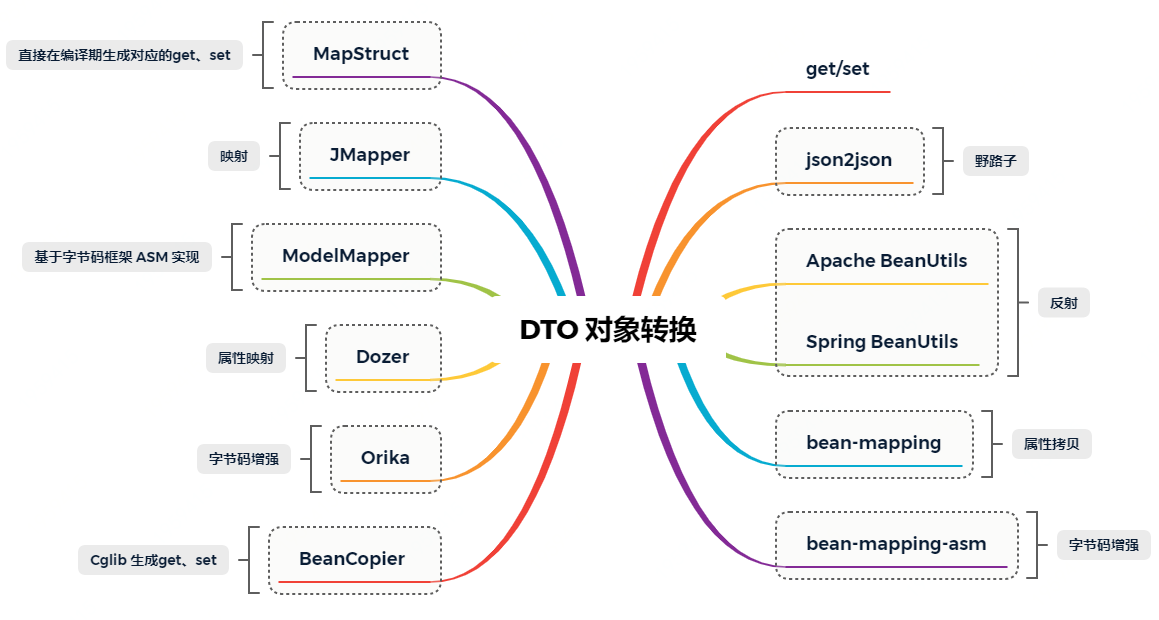
上图总结:BeanUtils.copyProperties 是大家代码里最常出现的工具类,但只要你不把它用错成 Apache 包下的,而是使用 Spring 提供的,就基本还不会对性能造成多大影响。
但如果说性能更好,**可替代手动get、set的,还是 MapStruct 更好用,**因为它本身就是在编译期生成get、set代码,和我们写get、set一样。
(1)MapStruct 对象转换操作
MapStruct使用:只需要定义一个 Mapper 接口,MapStruct就会自动实现这个映射接口,避免了复杂繁琐的映射实现。
//MapStruct 对象转换操作 @Mapper(componentModel = "spring", unmappedTargetPolicy = ReportingPolicy.IGNORE, unmappedSourcePolicy = ReportingPolicy.IGNORE) public interface AwardMapping extends IMapping { @Mapping(target = "userId", source = "uId") @Override AwardDTO sourceToTarget(DrawAwardVO var1); @Override DrawAwardVO targetToSource(AwardDTO var1); } - 定义接口 AwardMapping 继承 IMapping
- 如果一些接口字段在两个对象间不是同名的,则需要进行配置,就像 uId -> userId
11.MQ解耦抽奖发货流程
描述:使用MQ消息的特性,把用户抽奖到发货到流程进行解耦。这个过程中包括了消息的发送、库表中状态的更新、消息的接收消费、发奖状态的处理等。
Kafka:是一个高性能、可扩展的分布式发布订阅消息系统,主要用于处理大规模的实时数据流。它可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。
Kafka的Topic是一个消息的逻辑分类。一套消息系统中为多个模块(比如:订单模块和商品模块)提供服务。那就要对不同类型的消息进行逻辑分类,具体分类的方式就是用Topic进行区分,不同类别的消息具有不同的Topic。
Zookeeper:则是一个分布式协调服务,负责管理和协调分布式系统中的各种资源。
Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。MQ消息队列:消息队列(Message Queue,简称MQ)指保存消息的一个容器,其实本质就是一个保存数据的队列。
消息中间件是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的构建。
消息中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性的系统架构。目前使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
主要用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。以下介绍消息队列在实际应用中常用的使用场景:异步处理,应用解耦,流量削峰和消息通讯四个场景。
这里对MQ总结的挺好 全面了解消息队列MQ应用解耦:一般一个流程到另一个流程需要函数方法调用,而使用了MQ就可以不用直接调用而是通过订阅状态获取通知消息。
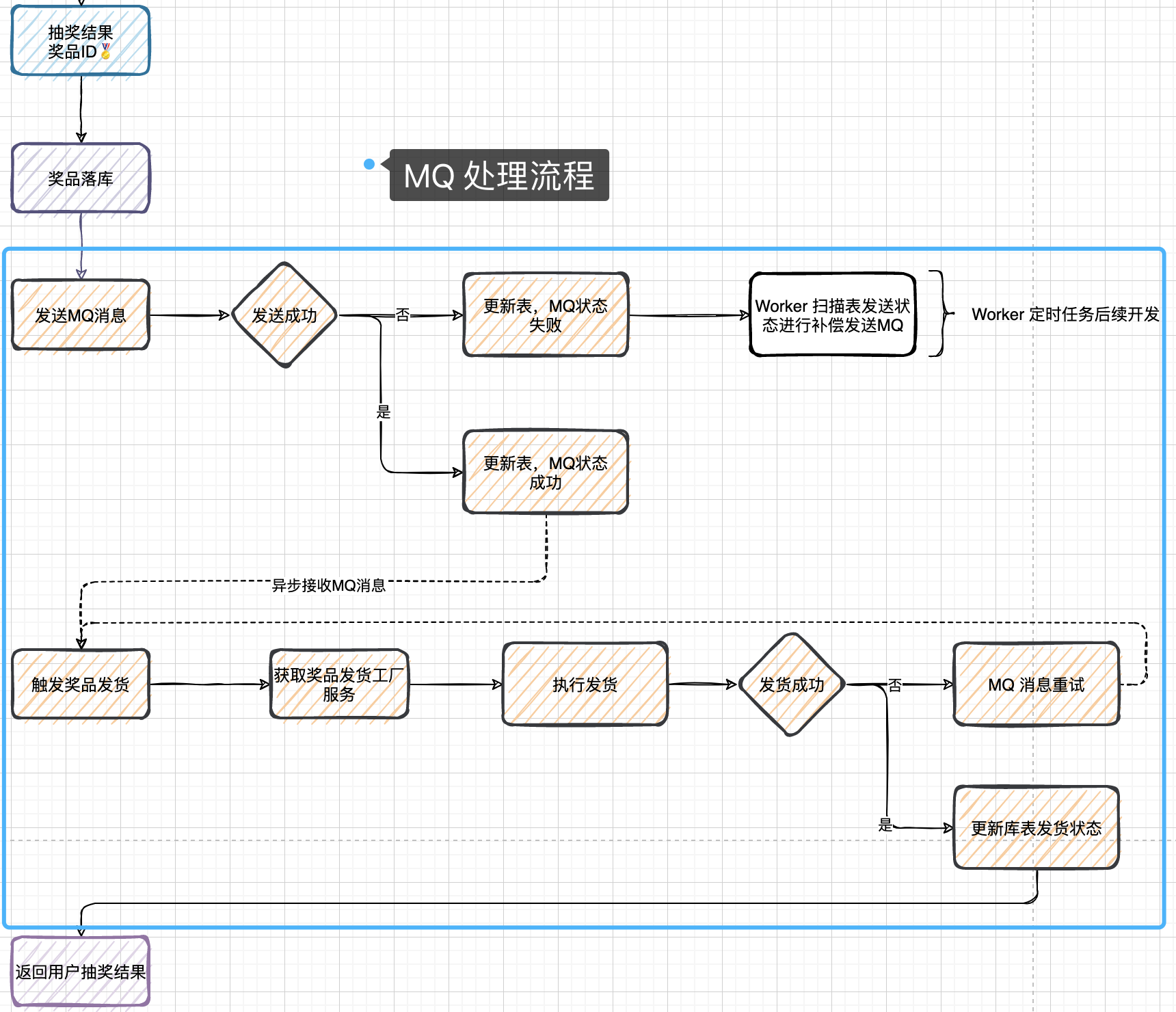
(1)用kafka+MQ处理发奖流程
MQ处理时需要考虑:(1)MQ发送失败需要Worker进行补偿发送(2)MQ消费(接收)失败,进行重试
这两次发送失败而发送多次,但对数据库的操作只能是一次,所以要进行幂等性操作。
- 在数据库表 user_strategy_export 添加字段 mq_state 这个字段用于发送 MQ 成功更新库表状态,如果 MQ 消息发送失败则需要通过定时任务补偿 MQ 消息。
- 启动 kafka 新增 topic:lottery_invoice 用于发货单消息,当抽奖完成后则发送一个发货单,再异步处理发货流程,这个部分就是MQ的解耦流程使用。
(1)生产消息:
lottery.application.mq.producer
@Component public class KafkaProducer { private Logger logger = LoggerFactory.getLogger(KafkaProducer.class); @Resource private KafkaTemplate kafkaTemplate; /** * MQ主题:中奖发货单 */ public static final String TOPIC_INVOICE = "lottery_invoice"; /** * 发送中奖物品发货单消息 * * @param invoice 发货单 */ public ListenableFuture> sendLotteryInvoice(InvoiceVO invoice) { String objJson = JSON.toJSONString(invoice); logger.info("发送MQ消息 topic:{} bizId:{} message:{}", TOPIC_INVOICE, invoice.getuId(), objJson); return kafkaTemplate.send(TOPIC_INVOICE, objJson); } } 我们会把所有的生产消息都放到 KafkaProducer 中,并对外提供一个可以发送 MQ 消息的方法。
因为我们配置的类型转换为 StringDeserializer 所以发送消息的方式是 JSON 字符串,当然这个编解码器是可以重写的,满足你发送其他类型的数据。
(2)消费消息:
lottery.application.mq.consumer
@Component public class LotteryInvoiceListener { private Logger logger = LoggerFactory.getLogger(LotteryInvoiceListener.class); @Resource private DistributionGoodsFactory distributionGoodsFactory; @KafkaListener(topics = "lottery_invoice", groupId = "lottery")//@Header(KafkaHeaders.RECEIVED_TOPIC)用于获取监听的TopicName public void onMessage(ConsumerRecord record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) { Optional message = Optional.ofNullable(record.value());//用于返回一个指定值的 Optional 对象,如果是null就返回一个空的 Optional 对象;否则,返回一个包含该值的 Optional 对象。 // 1. 判断消息是否存在 if (!message.isPresent()) { return; } // 2. 处理 MQ 消息 try { // 1. 转化对象(或者你也可以重写Serializer) InvoiceVO invoiceVO = JSON.parseObject((String) message.get(), InvoiceVO.class); // 2. 获取发送奖品工厂,执行发奖 IDistributionGoods distributionGoodsService = distributionGoodsFactory.getDistributionGoodsService(invoiceVO.getAwardType()); DistributionRes distributionRes = distributionGoodsService.doDistribution(new GoodsReq(invoiceVO.getuId(), invoiceVO.getOrderId(), invoiceVO.getAwardId(), invoiceVO.getAwardName(), invoiceVO.getAwardContent())); Assert.isTrue(Constants.AwardState.SUCCESS.getCode().equals(distributionRes.getCode()), distributionRes.getInfo()); // 3. 打印日志 logger.info("消费MQ消息,完成 topic:{} bizId:{} 发奖结果:{}", topic, invoiceVO.getuId(), JSON.toJSONString(distributionRes)); // 4. 消息消费完成 ack.acknowledge(); } catch (Exception e) { // 发奖环节失败,消息重试。所有到环节,发货、更新库,都需要保证幂等。 logger.error("消费MQ消息,失败 topic:{} message:{}", topic, message.get()); throw e; } } } 每一个 MQ 消息的消费都会有一个对应的 XxxListener 来处理消息体,如果你使用一些其他的 MQ 可能还会看到一些抽象类来处理 MQ 消息集合。
在这个 LotteryInvoiceListener 消息监听类中,主要就是通过消息中的发奖类型获取到对应的奖品发货工厂,处理奖品的发送操作。
在奖品发送操作中,已经补全了 DistributionBase# updateUserAwardState 更新奖品发送状态的操作。
(3)抽奖流程解耦:
// 5. 发送MQ,触发发奖流程 InvoiceVO invoiceVO = buildInvoiceVO(drawOrderVO); ListenableFuture> future = kafkaProducer.sendLotteryInvoice(invoiceVO);//发送一个中奖结果的发货单 future.addCallback(new ListenableFutureCallback>() {//消息发送完毕后进行回调处理,更新数据库中 MQ 发送的状态 @Override public void onSuccess(SendResult stringObjectSendResult) { // 5.1 MQ 消息发送完成,更新数据库表 user_strategy_export.mq_state = 1 activityPartake.updateInvoiceMqState(invoiceVO.getuId(), invoiceVO.getOrderId(), Constants.MQState.COMPLETE.getCode()); } @Override public void onFailure(Throwable throwable) { // 5.2 MQ 消息发送失败,更新数据库表 user_strategy_export.mq_state = 2 【等待定时任务扫码补偿MQ消息】 activityPartake.updateInvoiceMqState(invoiceVO.getuId(), invoiceVO.getOrderId(), Constants.MQState.FAIL.getCode()); } }); // 6. 返回结果 return new DrawProcessResult(Constants.ResponseCode.SUCCESS.getCode(), Constants.ResponseCode.SUCCESS.getInfo(), drawAwardVO); 消息发送完毕后进行回调处理,更新数据库中 MQ 发送的状态,如果:场景-1:mq_state = 2 发送消息失败,定时任务扫描后直接触发发送,并更新发送状态。场景-2:mq_state = 1 且更新时间与现在时间对比超过15分钟或者10分钟,那么定时任务扫描触发发送MQ,并更新发送状态。【这个定时任务是:Worker扫描表后续状态进行补偿发送MQ】
现在从用户领取活动、执行抽奖、结果落库,到 发送MQ处理后续发奖的流程就解耦了,因为用户只需要知道自己中奖了,但发奖到货是可以等待的,毕竟发送虚拟商品的等待时间并不会很长,而实物商品走物流就更可以接收了。所以对于这样的流程进行解耦是非常有必要的,否则你的程序逻辑会让用户在界面等待更久的时间。
这块的流程是:
发送MQ,然后根据发送情况更新mq_state
但当:(1)发送成功但没更新mq_state时出故障。这会导致重发,那就又接收一遍??怎么知道需要重发的??【后续开发】
(2)
12.xxl job处理活动状态扫描
XXL-JOB 系统简介:
XXL-JOB是一个分布式任务调度平台,处理需要使用定时任务解决的场景。其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
任务需要在多台机器上跑
名词总结:
在代码发那个面这一整 个Project:叫做工程
业务:比如抽奖、添加购物车、删除购物车
事务:Spring的事务是逻辑上的一组操作,要么都执行,要么都不执行。
系统(应用):整个外卖平台、营销平台。有的时候也分开把每个微服务叫系统,比如前台系统、交易系统、支付系统等。
微服务:一套商城内,商品、下单、支付、发货、结算、营销(抽奖、优惠券)每一个是一套微服务,来构成整个商城。