Ollama深度探索:AI大模型本地部署的全面教程
目录
- 引言
- 一、Ollama概述
- 1、定义与定位
- 2、核心功能
- 3、技术优势
- 4、应用场景
- 二、安装与配置
- 1、系统要求
- 2、安装方法
- 3、配置指南
- 4、启动Ollama服务
- 四、快速开始
- 1、启动Ollama
- 2、部署运行模型
- 3、REEST API
- 五、自定义模型
- 1、定制化的必要性
- 2、使用Modelfile定制模型
- 3、参数调整
- 4、训练和微调模型
- 六、高级功能
- 1、多模态模型支持
- 2、REST API的高级用法
- 3、编程语言库
- 结语
引言
我们正处在人工智能技术飞速发展的时代,其中大型语言模型(LLMs)已成为技术革新的前沿话题。这些模型以其强大的语言理解和生成能力,正在改变我们与机器交互的方式,并在自然语言处理(NLP)、内容创作、代码生成等多个领域展现出巨大的潜力。
本地化AI的新篇章
Ollama作为一个创新的工具,它的核心使命是简化大型语言模型在本地环境中的运行和管理。这不仅为开发者提供了一个强大的平台来部署和定制AI模型,而且也使得终端用户能够更加私密和安全地与这些智能系统进行交互。
隐私与便捷性的平衡
随着对数据隐私和安全性的日益关注,Ollama提供了一种解决方案,允许用户在不依赖外部服务器或云服务的情况下,直接在本地机器上运行复杂的AI模型。这种离线使用方式对于那些对隐私敏感或网络连接不稳定的用户来说尤其有价值。
面向未来的技术
Ollama不仅仅是一个技术工具,它代表了一种面向未来的思维方式。通过提供易于使用的接口和丰富的模型库,Ollama正在推动AI技术的民主化,让更多人能够访问和利用这些先进的模型,以解决实际问题并创造新的可能性。
一、Ollama概述
1、定义与定位
Ollama是一个专为本地环境设计的轻量级、可扩展的框架,用于构建和运行大型语言模型(LLMs)。它不仅仅是一个简单的运行时环境,而是一个完整的生态系统,提供了从模型创建、运行到管理的全套解决方案。Ollama的出现,标志着在本地机器上部署和操作复杂AI模型的新纪元。
2、核心功能
Ollama的核心功能包括但不限于以下几点:
- 模型运行:支持多种大型语言模型的本地运行,无需依赖远程服务器。
- 模型管理:提供模型的下载、更新、删除等管理功能。
- 自定义模型:允许用户通过Modelfile自定义模型参数和行为。
- API支持:提供REST API和编程语言库(如Python和JavaScript),方便集成到各种应用中。
- 多模态能力:支持图像等多模态数据的处理和分析。
- 安全性:注重数据的加密和安全传输,保护用户隐私。
3、技术优势
Ollama的技术优势在于其对本地化部署的重视,以及对开发者友好的接口设计:
- 本地化部署:降低了对网络的依赖,提高了数据处理的隐私性。
- 易用性:简化了模型部署流程,使得即使是初学者也能快速上手。
- 灵活性:通过Modelfile和API,提供了高度的定制性和集成性。
- 社区支持:拥有活跃的社区和丰富的文档,便于用户学习和交流。
4、应用场景
Ollama的应用场景广泛,包括但不限于:
- 自然语言处理:文本生成、翻译、摘要等。
- 代码生成与辅助:自动生成代码、代码补全等。
- 教育与研究:作为教学工具,帮助学生理解AI模型的工作原理。
- 企业解决方案:定制化模型以满足特定业务需求。
二、安装与配置
1、系统要求
在开始安装Ollama之前,确保您的系统满足以下基本要求:
- 操作系统:macOS、Windows 10及以上版本、Linux(包括但不限于Ubuntu、Fedora)
- 内存:至少4GB RAM,推荐8GB或以上,具体取决于所运行模型的大小
- 硬盘空间:至少100GB的空闲空间,用于安装Ollama及其模型库
2、安装方法
Ollama支持多种安装方式,包括通过包管理器、Docker或从源代码编译。
通过包管理器安装
- 对于macOS用户,可以使用Homebrew进行安装:
brew install ollama - 对于Linux用户,可以使用包管理器如apt(Ubuntu)或dnf(Fedora):
或者curl -fsSL https://ollama.com/install.sh | shsudo apt install ollama # Ubuntu sudo dnf install ollama # Fedora
- 对于macOS用户,可以使用Homebrew进行安装:
Docker安装
- Ollama提供了官方的Docker镜像,可以通过Docker Hub获取并运行:
docker pull ollama/ollama docker run -p 11434:11434 ollama/ollama
- Ollama提供了官方的Docker镜像,可以通过Docker Hub获取并运行:
从源代码编译
- 如果您希望从源代码编译Ollama,需要先安装Go语言环境和cmake:
git clone https://github.com/your/ollama.git cd ollama make build
- 如果您希望从源代码编译Ollama,需要先安装Go语言环境和cmake:
3、配置指南
安装完成后,进行基本配置以确保Ollama能够正常运行。
环境变量配置
- 根据需要配置环境变量,例如
OLLAMA_HOME指向Ollama的安装目录。
- 根据需要配置环境变量,例如
防火墙和网络设置
- 确保防火墙规则允许Ollama的端口(默认为11434)进行网络通信。
验证安装
- 使用以下命令验证Ollama是否安装成功:
ollama --version
- 使用以下命令验证Ollama是否安装成功:
模型库访问
- 运行Ollama服务前,确保可以访问Ollama的模型库,以便下载和使用预构建的模型。
4、启动Ollama服务
Ollama服务可以通过命令行界面(CLI)启动。
使用以下命令启动Ollama服务:
ollama serve服务启动后,您可以通过Web界面或API与Ollama进行交互。
四、快速开始
1、启动Ollama
在您的系统中成功安装Ollama之后,您可以通过以下步骤快速启动并运行您的第一个模型:
启动服务:打开终端或命令提示符,输入以下命令以启动Ollama服务:
ollama serve 2、部署运行模型
Ollama提供了丰富的预构建模型库,您可以根据自己的需求选择合适的模型进行部署。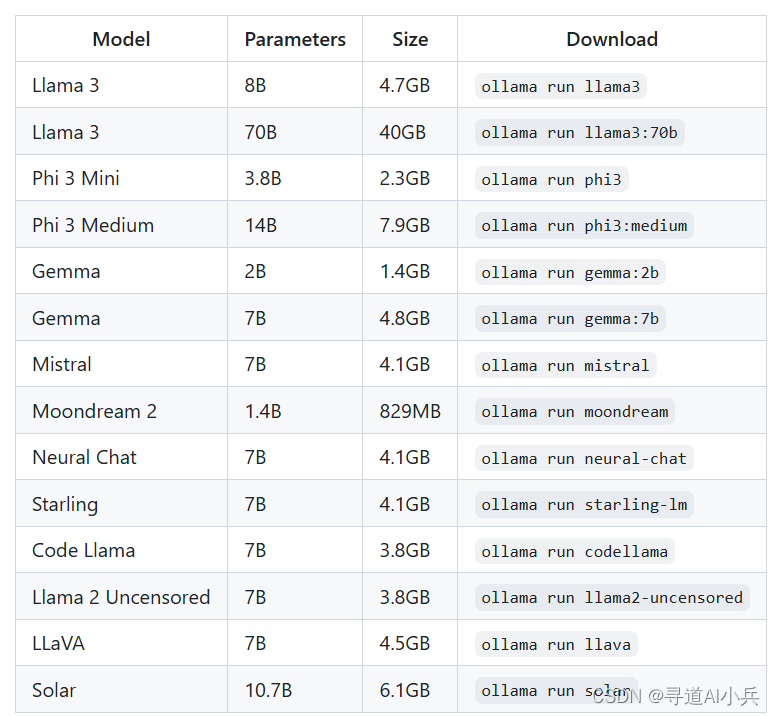
- 查看模型列表:
使用以下命令列出所有可用的模型:
ollama list - 查看版本:
查看 Ollama 版本
ollama -v - 运行模型:
下载完成后,使用以下命令部署运行模型:
ollama run llama3 ollama run llama3 "你是谁?" 样例如下: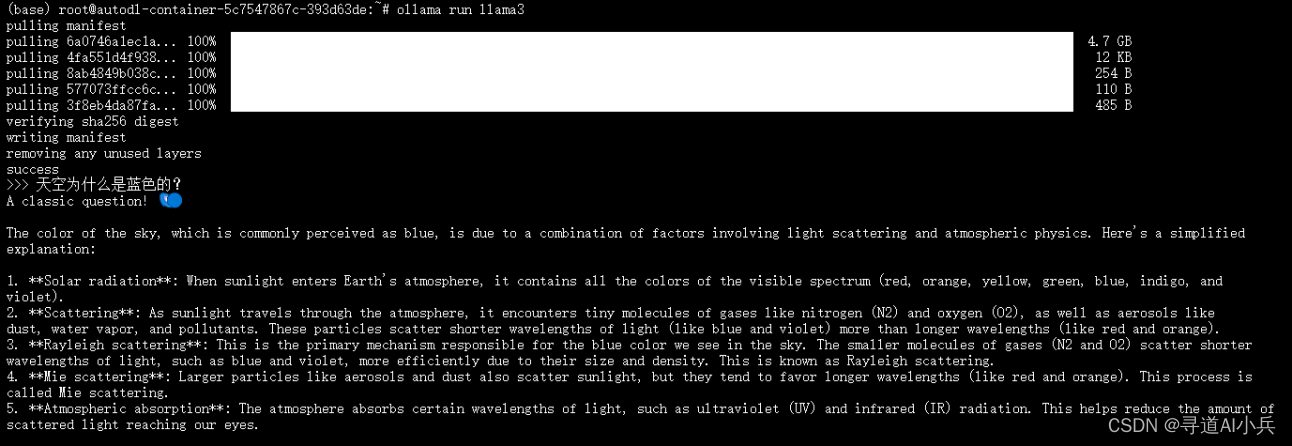
- 多行输入:
ollama run my_model """ Hello, world! """ 3、REEST API
如果您更喜欢使用编程方式,可以通过Ollama的REST API与模型交互。例如,使用curl发送请求:
1.生成响应
POST /api/generate 使用提供的模型为给定提示生成响应。这是一个流式处理终结点,因此会有一系列响应。最终响应对象将包括来自请求的统计信息和其他数据。
参数
model:(必填)型号名称
prompt:生成响应的提示
images:(可选)base64
编码图像列表(对于多模态模型,例如llava)
高级参数(可选):
format:返回响应的格式。目前唯一接受的值是json
options:模型文件文档中列出的其他模型参数,例如temperature
system:系统消息(覆盖Modelfile)
template:要使用的提示模板(覆盖Modelfile)
context:从上一个请求返回的上下文参数,这可用于保持较短的对话记忆/generate
stream:如果响应将作为单个响应对象返回,而不是对象流false
raw:如果不对提示应用任何格式。如果您在对 API的请求中指定了完整的模板化提示,则可以选择使用该参数trueraw
keep_alive:控制模型在请求后加载到内存中的时间(默认:5m)
示例:
curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt": "Why is the sky blue?" }' 输出:
{ "model": "llama3", "created_at": "2023-08-04T08:52:19.385406455-07:00", "response": "The", "done": false } 2.聊天对话:
POST /api/chat 在与提供的模型的聊天中生成下一条消息。这是一个流式处理终结点,因此会有一系列响应。可以使用 禁用流式处理。最终响应对象将包括来自请求的统计信息和其他数据。“stream”: false
参数
model:(必填)型号名称
messages:聊天的消息,这可以用来保留聊天记忆
该对象具有以下字段:message
role:消息的角色,或systemuserassistant
content:消息内容
images(可选):要包含在消息中的图像列表(对于多模态模型,例如llava)
高级参数(可选):
format:返回响应的格式。目前唯一接受的值是json
options:模型文件文档中列出的其他模型参数,例如temperature
stream:如果响应将作为单个响应对象返回,而不是对象流false
keep_alive:控制模型在请求后加载到内存中的时间(默认:5m)
示例:
curl http://localhost:11434/api/chat -d '{ "model": "llama3", "messages": [ { "role": "user", "content": "why is the sky blue?" } ] }' 输出:
{ "model": "llama3", "created_at": "2023-08-04T08:52:19.385406455-07:00", "message": { "role": "assistant", "content": "The", "images": null }, "done": false } 五、自定义模型
1、定制化的必要性
在许多应用场景中,预构建的模型可能无法完全满足特定的需求。Ollama提供了一系列工具和方法,允许用户根据自己的需求对模型进行定制化,以实现最佳的性能和效果。
2、使用Modelfile定制模型
Modelfile是Ollama中用于定义和管理模型的配置文件。通过Modelfile,用户可以调整模型参数、嵌入自定义提示、修改上下文长度等。
- 拉取模型:
Ollama 库中的模型可以通过提示进行自定义。例如,要自定义模型:llama3
ollama pull llama3 创建Modelfile:
创建一个Modelfile文件,指定基础模型和所需的参数调整:FROM: llama3 PARAMETER: - temperature: 0.5 - num_ctx: 512 TEMPLATE: "自定义的提示词模板" SYSTEM: message: "自定义的系统消息"使用Modelfile创建模型:
使用Ollama CLI工具根据Modelfile创建新的定制模型:ollama create my_custom_model -f path/to/you_Modelfile.yaml运行定制模型:
创建完成后,可以像运行普通模型一样运行定制模型:ollama run my_custom_model "输入你的提示"
3、参数调整
模型参数调整是定制化过程中的重要组成部分,可以显著影响模型的行为和输出。
温度参数:
调整温度参数可以控制模型输出的创造性和随机性。上下文长度:
根据任务的需要调整模型处理的上下文长度。随机种子:
设置随机种子可以复现模型的输出结果。
4、训练和微调模型
如果拥有特定领域的数据集,可以通过训练或微调模型来提高其在该领域的性能。
准备数据集:
收集并预处理特定领域的数据,准备用于模型训练。微调模型:
使用Ollama的训练工具对模型进行微调:ollama train my_custom_model --dataset path/to/dataset
六、高级功能
1、多模态模型支持
Ollama的多模态模型支持允许模型同时处理文本和图像数据,为用户提供更丰富的交互体验。
多模态数据处理:
用户可以上传图像文件,模型将分析图像内容并结合文本提示生成响应:from ollama import MultiModalModel model = MultiModalModel('multimodal-model-name') response = model.generate_from_image('/path/to/image.png')图像和文本的融合:
Ollama能够理解图像内容与文本之间的关联,生成与两者都相关的输出。应用场景:
多模态模型适用于图像描述、视觉问答等场景。
2、REST API的高级用法
Ollama的REST API不仅支持基本的模型运行,还提供了更高级的功能,如批量处理和参数定制。
批量生成:
通过API发送批量请求,同时生成多个输入的响应:POST /api/generate { "model": "llama3", "prompts": ["Why is the sky blue?", "What is AI?"] }定制化参数:
通过API发送定制化的参数,如温度、上下文长度等:POST /api/generate { "model": "llama3", "prompt": "Describe the process of photosynthesis.", "parameters": { "temperature": 0.7, "max_tokens": 100 } }模型管理API:
使用API进行模型的下载、更新和管理:POST /api/models/download { "model_id": "llama-13b" }
3、编程语言库
Ollama提供了多种编程语言的库,方便开发者在自己的应用程序中集成Ollama的功能。
Python库:
使用ollama-python库在Python应用程序中调用Ollama模型:import ollama client = ollama.Client() response = client.generate(model_id='my_model', prompt='Hello, world!')JavaScript库:
在Web应用程序中使用ollama-js库与Ollama服务交互。其他语言支持:
Ollama致力于提供更多编程语言的库,以满足不同开发者的需求。
结语
随着本指南的结束,我们对Ollama的探索也达到了尾声。从基础的安装与配置,到高级功能的应用,再到实际案例的分析和未来潜力的展望,我们见证了Ollama作为一个强大的本地AI模型运行平台所展现的广泛能力和深远影响。
希望Ollama成为您在AI旅程中的得力助手,助您在智能时代的浪潮中乘风破浪。再次感谢您的阅读,祝您在使用Ollama的过程中获得丰富成果。

🎯🔖更多专栏系列文章:AIGC-AI大模型开源精选实践
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!