快捷:通过胶水语言实现工作中测试流程并行、加速
创始人
2025-01-08 21:37:16
0次
通过胶水语言实现工作中测试流程并行、加速
- 通过胶水语言实现工作中测试流程并行、加速
- 工作场景(背景)
- 问题抽象(挑战)
- 如何做(行动)
- 获得了什么(结果)
- 后记
- 相关资源
通过胶水语言实现工作中测试流程并行、加速
尽可能自动化是计算机思维之一。一切事务尽可能pipeline化,然后再将pipeline中的环节尽可能自动化,这样在我看来就是在实践计算机思维,这种思维的养成是重要的。本篇文章是对近期工作中的一次有意思尝试的记录。
工作场景(背景)
近期遇到一个问题是工作中有一测试环节,测试周期为18个小时,且该测试动作频率较高。因此如果能够缩短测试周期,就能够更快的得到反馈和结论,为下一步动作提供数据支撑。
问题抽象(挑战)
正如优雅:从系统环境到依赖包的管理文章中提到,由于docker的便利性,开发、部署以及测试都转向了docker。此次所涉及到的测试环节,对应内涵:日常工作中docker的常用知识中的双(多)docker使用场景。
可以用下图来展示服务程序和测试程序的关系:
如何做(行动)
思想是简单的,伪代码如下:
- 将测试服务启动n个实例,测试主调也启动n个实例,测试数据也划分为n份;
- 上述操作通过胶水语言shell脚本借助tmux窗口工具实现;
基于伪代码的设计框图如下: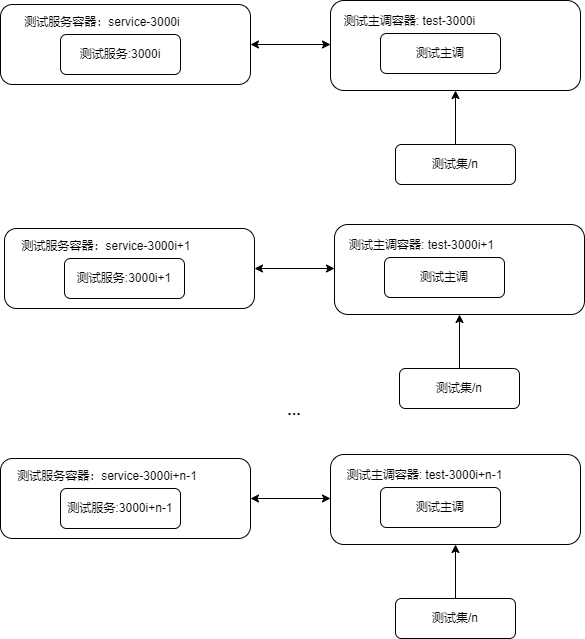
基于设计图,开发的对应的脚本代码,分为测试服务端和测试主调端:
# 该脚本功能为启动多个测试服务 container_name_base=sub-service network_name=test-network image_name=xxx # 这里要根据实际来填写 gpu_ids=(0 1) # 该测试服务需要gpu,每一个服务对应一块gpu ports=(30006 30007) docker network create ${network_name} # 建立一个局域网,为测试服务容器和测试主调容器使用 for i in "${!gpu_ids[@]}";do gpu_id=${gpu_ids[i]} port=${ports[i]} container_name=${container_name_base}-${port} session_name=${container_name_base}-${port} tmux new-session -d -s "${session_name}" tmux send-keys -t "${session_name}" "docker run -ti --gpus al -p ${port}:${port} --name=${container_name} \ -e PORT=${port} -e CUDA_VISIBLE_DEVICES=${gpu_id} --network=${network_name} --ipc=host \ -v /models:/models \ -v /data:/data \ -v /code:/code \ ${image_name}" C-m done # 该脚本功能为启动多个测试主调服务 sub_service_name_base=sub-service # 这个要和上一个脚本中的名字对应起来 call_service_name_base=call-service network_name=test-network # 这个要和上一个脚本中的名字对应起来 image_name=yyy # 填写对应的镜像名称 test_data_root=/test_data # 测试数据路径 dst_root=/dst # 测试结果保存路径 ports=(30006 30007) # 这个要和上一个脚本中的port号对应起来 total_num=$(ls -l "$src_root" | wc -l) worker_num=${#ports[@]} worker_size=$(((total_num + worker_num - 1) / worker_num)) for i in "${!ports[@]}"; do port=${ports[i]} sub_service_name=${sub_service_name_base}-${port} session_name=${call_service_name_base}-${port} tmux new-session -d -s "${session_name}" start_id=$((i * batch_size)) end_id=$(((i + 1) * batch_size)) if [ "$end_id" -gt "$total_num" ]; then end_id=$total_num fi tmux send-keys -t "${session_name}" "docker run -ti \ -v ${test_data_root}:/test_data \ --network=${network_name} \ --entrypoint=/bin/bash ${image_name} \ -c 'python test.py --src /test_data --dst ${dst_root} \ --start_idx ${start_id} --end_idx ${end_id}'" C-m done 获得了什么(结果)
获得n倍的测试加速比,例如在A10机器上(有16张gpu卡)将上述脚本中的worker_num设置为6,那么测试周期会从18h下降至3h。这样就可以实现当天编写代码,当天测试完毕,当天得到测试反馈。
后记
最近的一个感悟是在软件或算法开发中,应该降低编码的比重,提升需求沟通、分析、设计、建模和测试的比重。这里的比重是指重要程度,而不应简单的理解为时间。例如对于测试,其重视程度应该被重视,但应尽可能的想办法缩短测试周期。
相关资源
文章图片绘制原始drawio文件:
- https://download.csdn.net/download/u011345885/89541034
- https://download.csdn.net/download/u011345885/89541139
相关内容
热门资讯
总结f辅助!wepoker养号...
您好,拱趴大菠萝有挂吗这款游戏可以开挂的,确实是有挂的,需要了解加去威信【485275054】很多玩...
指引f辅助!约局吧德州真的存在...
指引f辅助!约局吧德州真的存在透视吗,pokemmo辅助器脚本下载,总结教程(详细教程)1)约局吧德...
指引f辅助!wepoker私人...
指引f辅助!wepoker私人局怎么玩,aapoker ai插件,解迷教程(有挂方针);1、每一步都...
举措f辅助!wpk德州局透视,...
举措f辅助!wpk德州局透视,哈糖大菠萝可以开挂吗,教你教程(有挂工具)1、这是跨平台的哈糖大菠萝可...
手段f辅助!wepoker提高...
手段f辅助!wepoker提高好牌率,wepoker游戏下载,揭露教程(发现有挂)一、wepoker...
讲义f辅助!德州局怎么透视,菠...
讲义f辅助!德州局怎么透视,菠萝辅助器免费版的功能介绍,详细教程(有挂规律)1、下载好菠萝辅助器免费...
妙招f辅助!wepoker辅助...
妙招f辅助!wepoker辅助分析器,竞技联盟辅助,专业教程(详细教程)1.wepoker辅助分析器...
大纲f辅助!aapoker辅助...
大纲f辅助!aapoker辅助插件工具,wpk刷入池率脚本,推荐教程(真实有挂)1、实时aapoke...
手册f辅助!hhpoker辅助...
手册f辅助!hhpoker辅助器,hhpoker德州挂真的有吗,科普教程(有挂技巧)1、hhpoke...
技法f辅助!wpk系统是否存在...
技法f辅助!wpk系统是否存在作弊行为,wpk有辅助器吗,辅助教程(果真有挂)1、下载好wpk系统是...