【旅游景点项目日记 | 第二篇】基于Python中的Selenium爬取携程旅游网景点详细数据
创始人
2025-01-08 13:32:55
0次

文章目录
- 3.使用Python的Selenium框架爬取携程旅游网景点详细数据
- 3.1前提环境
- 3.2思路
- 3.3代码详讲
- 3.3.1查询指定城市的所有景点
- 3.3.2获取详细景点的访问路径
- 3.3.3获取景点的详细信息
- 3.4数据库设计
- 3.5全部代码
- 3.6效果图
3.使用Python的Selenium框架爬取携程旅游网景点详细数据
3.1前提环境
- 确保安装python3.x环境
- 以管理员身份打开cmd,安装selenium、pymysql、datetime,默认安装最新版即可
pip install selenium pip install pymysql pip install datetime 确保chrome安装对应版本的驱动(将该驱动放在chrome安装路径下),用于控制chrome浏览器,并将路径添加到环境变量的Path变量中,如图所示!
#安装chrome驱动教程链接: https://blog.csdn.net/linglong_L/article/details/136283810
3.2思路
- 搜索指定城市景点,网站通过分页进行展示;
- 使用selenium每个景点的详细访问路径,并点击该路径获取详细景点信息,再通过正则表达式获取需要的内容;
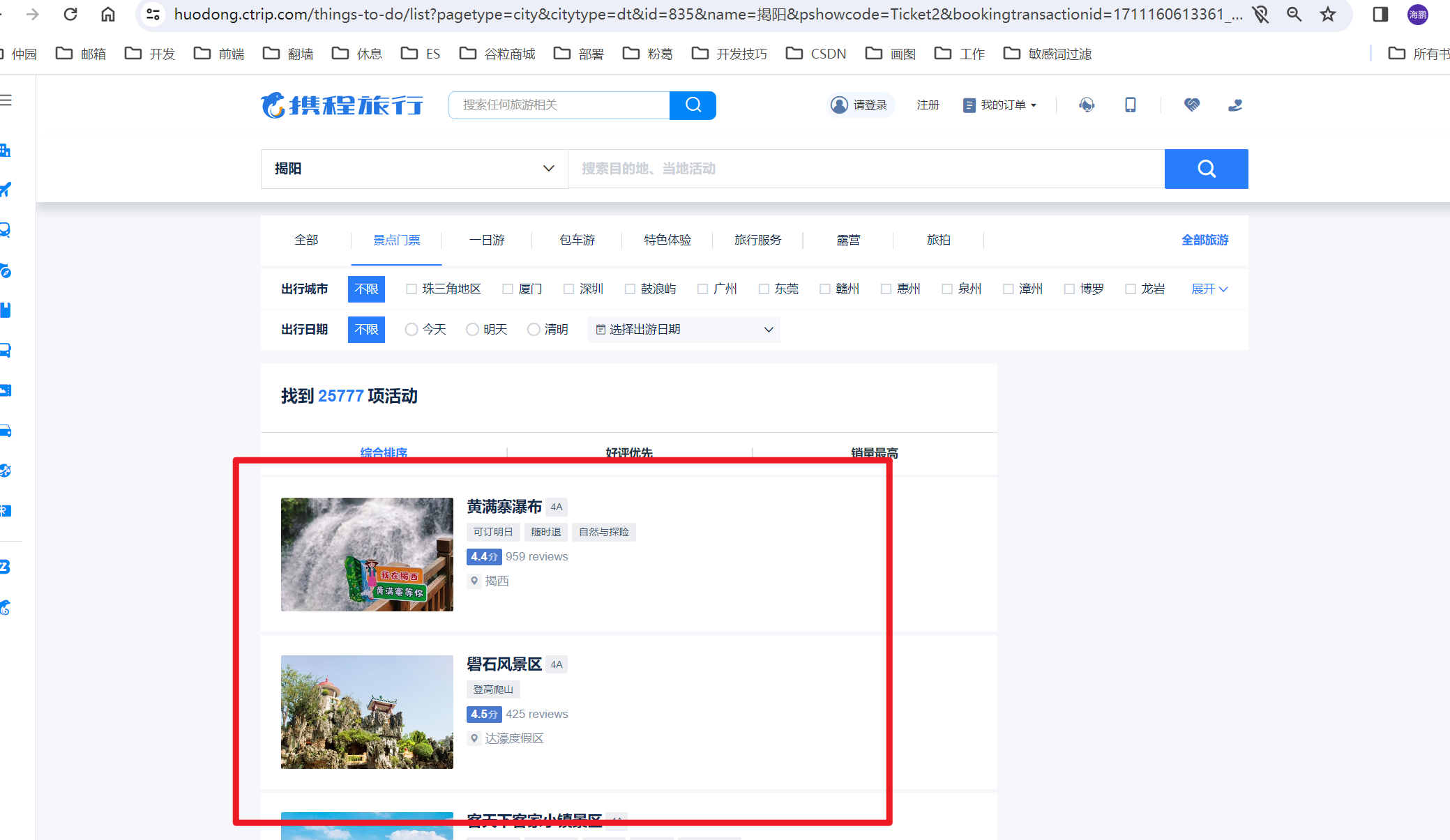
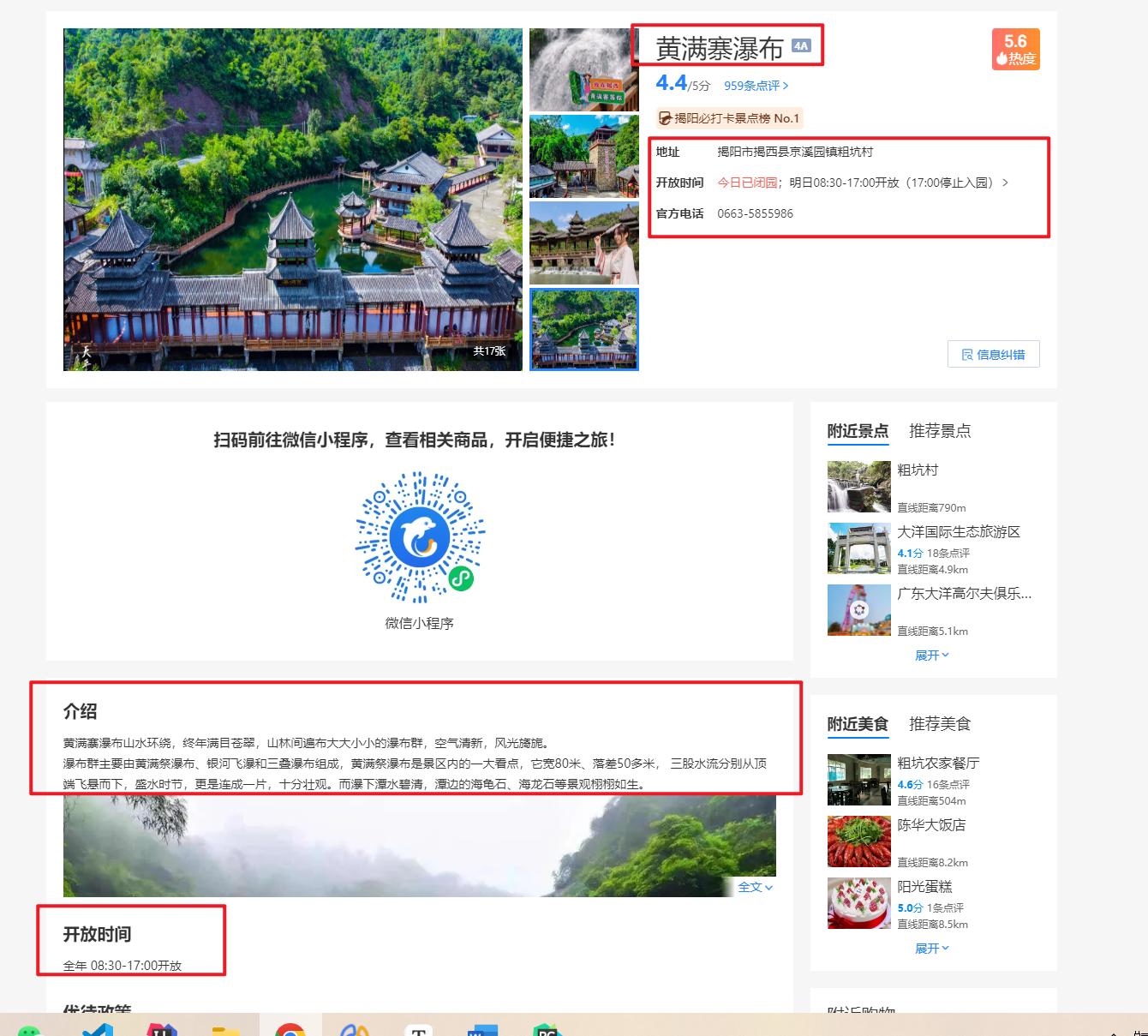
如下图,景点的详细信息有:景点名称、景点等级(1-5A)、景点地址、开放时间(有两种,我们采用下面的)、联系电话、景点介绍、景点图片等内容
3.3代码详讲
3.3.1查询指定城市的所有景点
- 控制打开chrome,并访问指定查询所有景点路径
def __init__(self): options = Options() options.add_argument('--headless') service = Service() self.chrome = Chrome(service=service) self.chrome.get( 'https://huodong.ctrip.com/things-to-do/list?pagetype=city&citytype=dt&keyword=%E6%A2%85%E5%B7%9E&id=523&name=%E6%A2%85%E5%B7%9E&pshowcode=Ticket2&kwdfrom=srch&bookingtransactionid=1711160613361_6064') time.sleep(3) self.page = 1 self.headers = { 'cookie': 'suid=lh/P1+4RKuhAYg684ErS+g==; suid=lh/P1+4RKuhAYg684ErS+g==', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', } 3.3.2获取详细景点的访问路径
- 使用selenium的根据class定位元素方法,找到详细景点的href属性,即为该景点的访问路径
- 并通过page属性控制访问的页数
#获取景点请求路径 def get_url(self): while True: content = self.chrome.find_element(By.CLASS_NAME, "right-content-list").get_attribute('innerHTML') cons = re.findall(r'href="(.*?)" title="(.*?)"', content) for con in cons: self.detail_url = 'https:' + con[0] self.title = con[1] print(self.detail_url, self.title) self.get_detail() self.chrome.find_element(By.CLASS_NAME,'u_icon_enArrowforward').click() time.sleep(1) self.page += 1 if self.page == 120: break 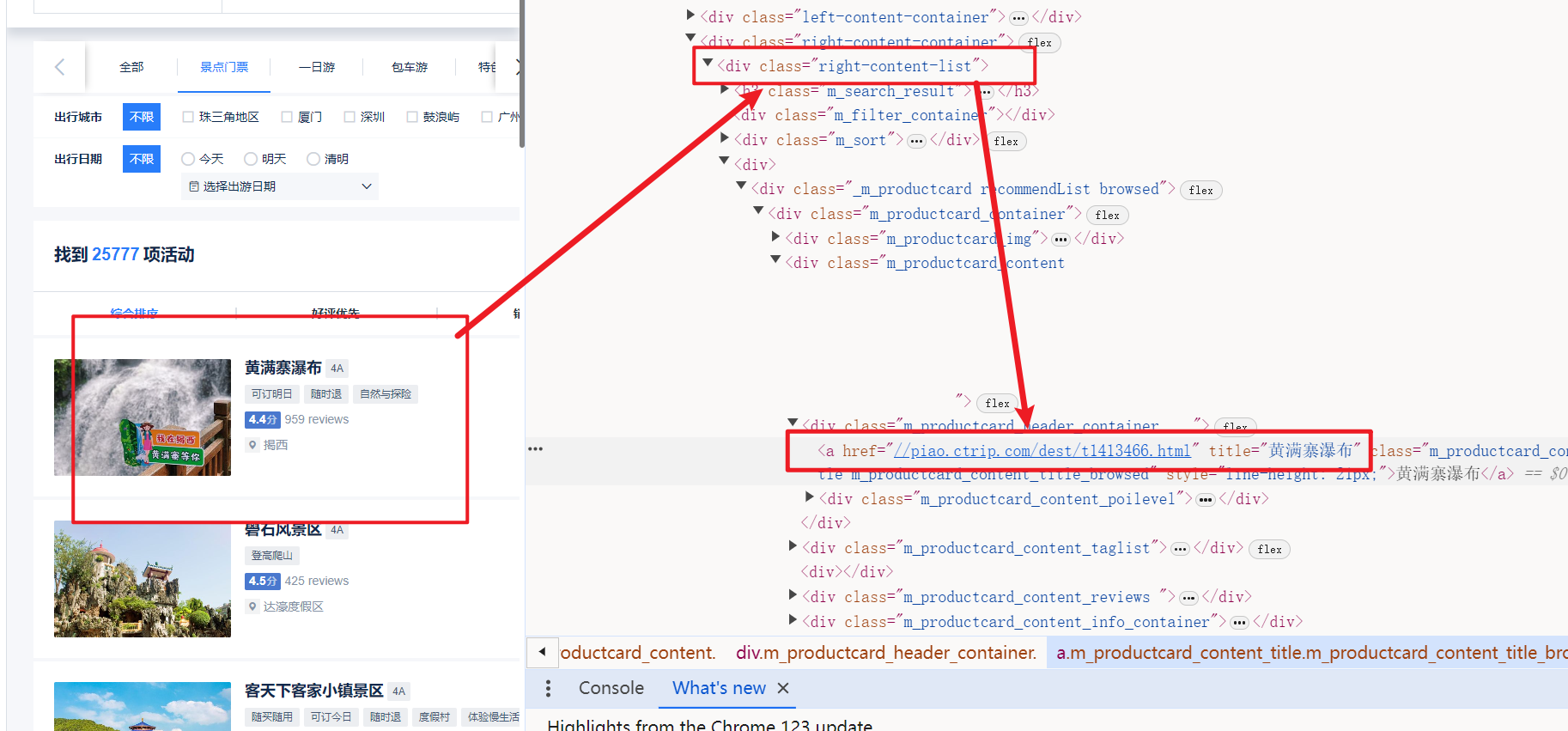
3.3.3获取景点的详细信息
- 景点的详细信息有:景点名称、景点等级(1-5A)、景点地址、开放时间(有两种,我们采用下面的)、联系电话、景点介绍、景点图片等内容
- 通过正则表达式获取,详细代码如下:
- 并每次获取详细信息之后,将信息保存到mysql数据库中
def get_detail(self): detail_con = requests.get(self.detail_url, verify=False, headers=self.headers).text # time.sleep(2) '''使用正则获取信息''' self.title = ''.join(re.findall(r'(.*?)<', detail_con, re.DOTALL)) print('景点名称:'+self.title) #self.rank = ''.join(re.findall(r'rankText">(.*?)<', detail_con, re.DOTALL)) self.address = ''.join(re.findall(r'地址
(.*?)<', detail_con, re.DOTALL)) self.mobile = ''.join(re.findall(r'官方电话
(.*?)<', detail_con, re.DOTALL)) self.quality_grade= ''.join(re.findall(r'
(.*?) 'cookie': 'suid=lh/P1+4RKuhAYg684ErS+g==; suid=lh/P1+4RKuhAYg684ErS+g==', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', } #获取景点请求路径 def get_url(self): while True: content = self.chrome.find_element(By.CLASS_NAME, "right-content-list").get_attribute('innerHTML') cons = re.findall(r'href="(.*?)" title="(.*?)"', content) for con in cons: self.detail_url = 'https:' + con[0] self.title = con[1] print(self.detail_url, self.title) self.get_detail() self.chrome.find_element(By.CLASS_NAME,'u_icon_enArrowforward').click() time.sleep(1) self.page += 1 if self.page == 120: break def get_detail(self): detail_con = requests.get(self.detail_url, verify=False, headers=self.headers).text # time.sleep(2) '''使用正则获取信息''' self.title = ''.join(re.findall(r'(.*?)<', detail_con, re.DOTALL)) print('景点名称:'+self.title) #self.rank = ''.join(re.findall(r'rankText">(.*?)<', detail_con, re.DOTALL)) self.address = ''.join(re.findall(r'地址
(.*?)<', detail_con, re.DOTALL)) self.mobile = ''.join(re.findall(r'官方电话
(.*?)<', detail_con, re.DOTALL)) self.quality_grade= ''.join(re.findall(r'
(.*?)id}?onlyContent=true&onlyShelf=true' ticket_res = requests.get(ticket_url, verify=False, headers=self.headers).text # time.sleep(1) ticket_ret = etree.HTML(ticket_res) ticket = ticket_ret.xpath('//table[@class="ticket-table"]//div[@class="ttd-fs-18"]/text()') price = ticket_ret.xpath( '//table[@class="ticket-table"]//td[@class="td-price"]//strong[@class="ttd-fs-24"]/text()') print(ticket) print(price) '''拿到的列表里可能存在不确定数量的空值,所以这里用while True把空值全部删除,这样才可以确保门票种类与价格正确对应上''' while True: try: ticket.remove(' ') except: break while True: try: price.remove(' ') except: break ''' 这里多一个if判断是因为我发现有些详情页即便拿到门票信息并剔除掉空值之后仍然存在无法对应的问题,原因是网页规则有变动, 所以一旦出现这种情况需要使用新的匹配规则,否则会数据会出错(不会报错,但信息对应会错误) ''' if len(ticket) != len(price): ticket = ticket_ret.xpath( '//table[@class="ticket-table"]/tbody[@class="tkt-bg-gray"]//a[@class="ticket-title "]/text()') price = ticket_ret.xpath('//table[@class="ticket-table"]//strong[@class="ttd-fs-24"]/text()') while True: try: ticket.remove(' ') except: break while True: try: price.remove(' ') except: break print(ticket) print(price) ticket_dict = dict(zip(ticket, price)) print(ticket_dict) if __name__ == '__main__': jy_jd = Jy_jd() jy_jd.get_url() 3.6效果图


上一篇:【亲测有效】Win11(23H2)重启后任务栏Copilot图标恢复
下一篇:正确解决selenium.common.exceptions.SessionNotCreatedException: Message: session not created异常的有效解决方法
相关内容
热门资讯
为了进一步!微信小程序免费黑科...
为了进一步!微信小程序免费黑科技透视,新道游app辅助器教材教程(有挂规律)1、玩家可以在微信小程序...
如何分辨真伪!新超凡软件辅助,...
【福星临门,好运相随】;如何分辨真伪!新超凡软件辅助,微乐陕西小程序脚本,新版2025教程(原来有开...
实测发现!微乐贵阳捉鸡麻将挂软...
您好:微乐贵阳捉鸡麻将挂软件这款游戏可以开挂的,确实是有挂的,很多玩家在这款游戏中打牌都会发现很多用...
带你了解!牛总管一定要牛辅助,...
带你了解!牛总管一定要牛辅助,雀友会潮汕图片辅助器,wepoke教程(原来有开挂辅助神器)是一款可以...
推荐十款!爱玩联盟辅助下载,悟...
推荐十款!爱玩联盟辅助下载,悟空大厅微信辅助,解说技巧(原来有开挂辅助黑科技);推荐十款!爱玩联盟辅...
最新技巧!雀友会辅助潮汕麻将脚...
最新技巧!雀友会辅助潮汕麻将脚本,微信小程序微乐怎么才能发好牌,2025版教程(原来有开挂辅助助手)...
玩家亲测!欢乐达人脚本,wep...
玩家亲测!欢乐达人脚本,wepoker插件下载,科技教程(原来有开挂辅助app);作为系统规律正版授...
推荐攻略!悟空大厅辅助助手下载...
推荐攻略!悟空大厅辅助助手下载安装,hhpoker是正规的吗,揭秘教程(原来有开挂辅助器);是一种具...
玩家必看!花花生活圈私人局辅助...
玩家必看!花花生活圈私人局辅助器,新青鸟辅助,高科技教程(原来有开挂辅助器);AI辅助机器人普及解说...
技术分享!兴动平台辅助下载,财...
技术分享!兴动平台辅助下载,财神十三张脚本辅助,wepoke教程(原来有开挂辅助挂);最新版2026...