llama-factory微调工具使用入门
一、定义
- 环境配置
- 案例: https://zhuanlan.zhihu.com/p/695287607
- chatglm3 案例
- 多卡训练deepspeed
- llama factory 案例Qwen1.5
- 报错
二、实现
- 环境配置
git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python=3.10 conda activate llama_factory cd LLaMA-Factory pip install -e '.[torch,metrics]' 如果发生冲突: pip install --no-deps -e . 同时对本库的基础安装做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h 
模型下载与可用性校对
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git import transformers import torch # 切换为你下载的模型文件目录, 这里的demo是Llama-3-8B-Instruct # 如果是其他模型,比如qwen,chatglm,请使用其对应的官方demo model_id = "/home/Meta-Llama-3-8B-Instruct" pipeline = transformers.pipeline( "text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto", ) messages = [ {"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"}, {"role": "user", "content": "Who are you?"}, ] prompt = pipeline.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) terminators = [ pipeline.tokenizer.eos_token_id, pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>") ] outputs = pipeline( prompt, max_new_tokens=256, eos_token_id=terminators, do_sample=True, temperature=0.6, top_p=0.9, ) print(outputs[0]["generated_text"][len(prompt):]) 
2. 案例: https://zhuanlan.zhihu.com/p/695287607
2.1 数据准备
将该自定义数据集放到我们的系统中使用,则需要进行如下两步操作
a 复制该数据集到 data目录下
b 修改 data/dataset_info.json 新加内容完成注册, 该注册同时完成了3件事
b1 自定义数据集的名称为adgen_local,后续训练的时候就使用这个名称来找到该数据集
b2 指定了数据集具体文件位置
b3 定义了原数据集的输入输出和我们所需要的格式之间的映射关系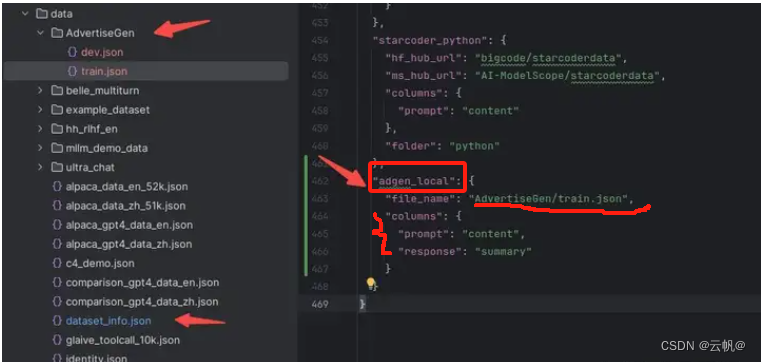
2. 微调:
下载模型
>> git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_train \ --model_name_or_path /home/Meta-Llama-3-8B-Instruct \ --dataset alpaca_gpt4_zh,identity,adgen_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --output_dir ./saves/LLaMA3-8B/lora/sft \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --logging_steps 50 \ --warmup_steps 20 \ --save_steps 100 \ --eval_steps 50 \ --evaluation_strategy steps \ --load_best_model_at_end \ --learning_rate 5e-5 \ --num_train_epochs 5.0 \ --max_samples 1000 \ --val_size 0.1 \ --plot_loss \ --fp16 或者:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train ./examples/train_lora/llama3_lora_sft.yaml 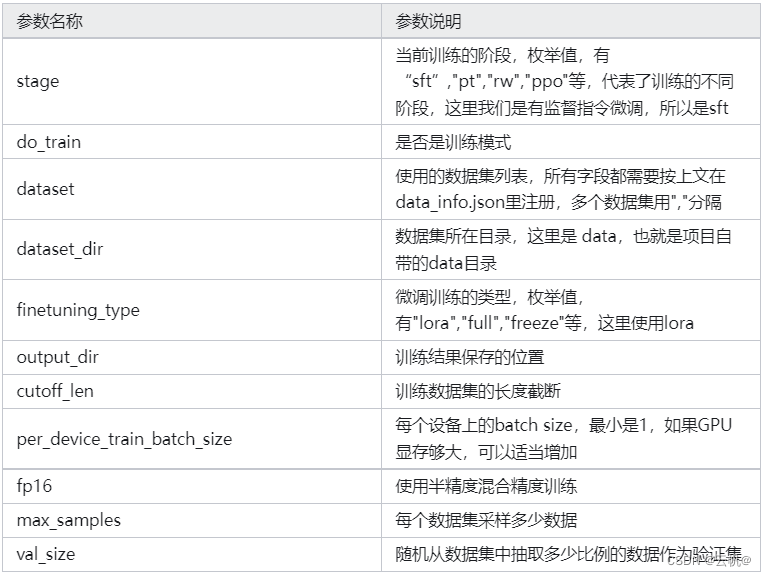

3. 推理
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat ./examples/inferce/llama3_lora_sft.yaml 或
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \ --model_name_or_path /home/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora 
4. 批量预测与训练效果评估
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat ./examples/train/llama3_lora_predict.yaml 或
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_predict \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --dataset alpaca_gpt4_zh,identity,adgen_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --output_dir ./saves/LLaMA3-8B/lora/predict \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_eval_batch_size 1 \ --max_samples 20 \ --predict_with_generate 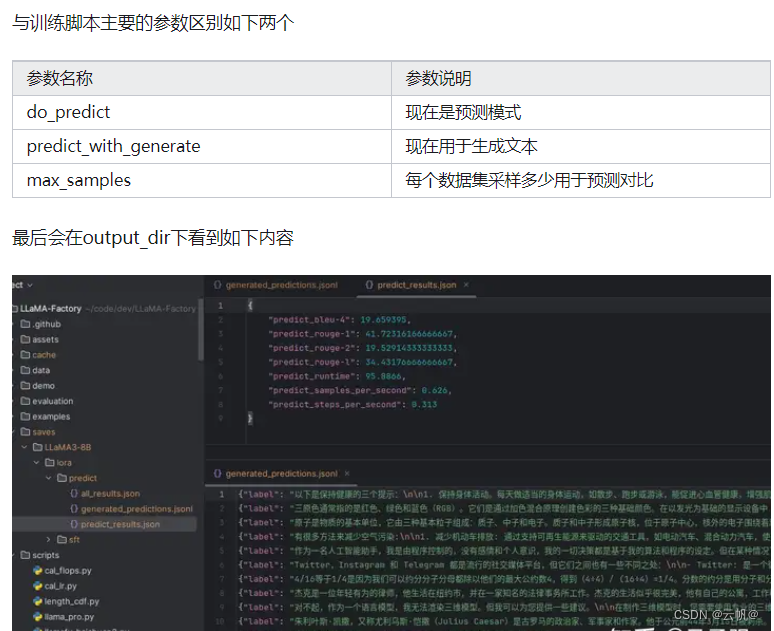
5. LoRA模型合并导出
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \ --model_name_or_path /home/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora \ --export_dir megred-model-path \ --export_size 2 \ --export_device cpu \ --export_legacy_format False CUDA_VISIBLE_DEVICES=0 llamafactory-cli export ./examples/merge_lora/llama3_lora_sft.yaml 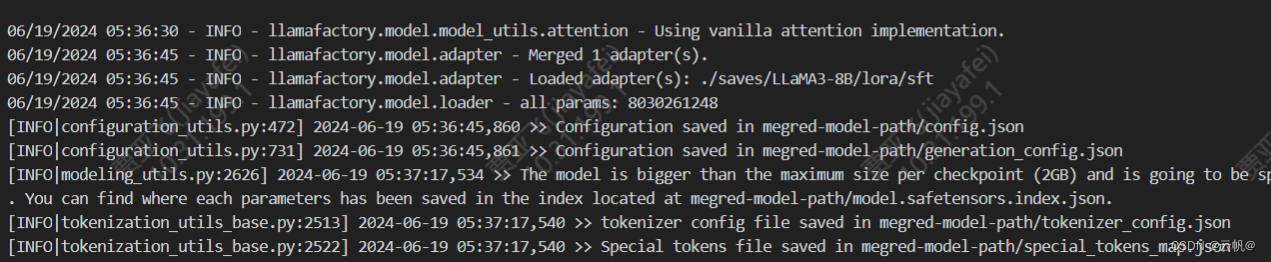
6. api 调用
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 nohup llamafactory-cli api \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora 项目也支持了基于vllm 的推理后端,但是这里由于一些限制,需要提前将LoRA 模型进行merge,使用merge后的完整版模型目录或者训练前的模型原始目录都可。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 nohup llamafactory-cli api \ --model_name_or_path megred-model-path \ --template llama3 \ --infer_backend vllm \ --vllm_enforce_eager>output.log 2>&1 & 
import os from openai import OpenAI from transformers.utils.versions import require_version require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0") if __name__ == '__main__': # change to your custom port port = 8000 client = OpenAI( api_key="0", base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)), ) messages = [] messages.append({"role": "user", "content": "hello, where is USA"}) result = client.chat.completions.create(messages=messages, model="test") print(result.choices[0].message) 
7. 测试
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval ./examples/train/llama3_lora_eval.yaml 或
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --template llama3 \ --task mmlu \ --split validation \ --lang en \ --n_shot 5 \ --batch_size 1 chatglm3 案例
见专题模块多卡训练deepspeed
多卡看llama3_lora_sft_ds0.yaml报错
1,RuntimeError: Failed to import trl.trainer.dpo_trainer because of the following error (look up to see its traceback):
‘FieldInfo’ object has no attribute ‘required’
解决:换干净的环境,重新安装。