昇思25天学习打卡营第13天|LLM-基于MindSpore实现的GPT对话情绪识别
创始人
2025-01-07 03:35:43
0次
打卡

目录
打卡
预装环境
流程简述
部分执行结果演示
词向量加载过程
模型结构
模型训练过程
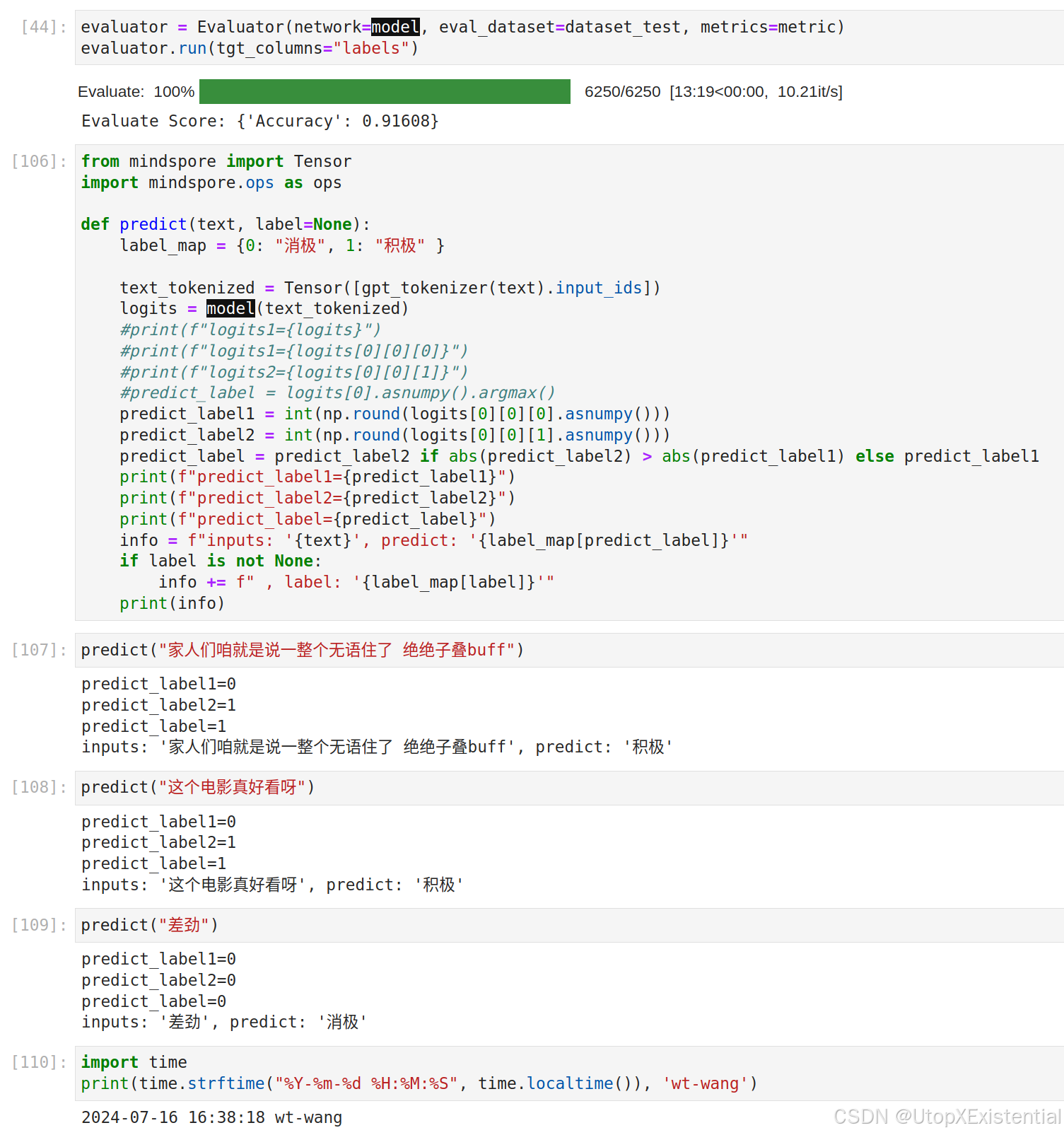
模型预测过程
代码
预装环境
pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14 pip install mindnlp pip install jieba pip install spacy pip install ftfy 环境变量设置:HF_ENDPOINT=https://hf-mirror.com
流程简述
任务:用IMDB开源标注数据集,微调开源的预训练模型GPT,实现对话情绪识别。
1、数据集准备:IMDB数据集,从 https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz 下载数据集并按照7:3切分为训练和验证集。
2、加载TOKEN:用 mindnlp.transformers.GPTTokenizer 加载 tokenizer,并为其添加3个特殊的TOKEN("bos_token"、"eos_token"、"pad_token")
3、预处理训练、验证、测试数据集,包括将文本数据进行tokenizer,并根据设备类型对数据进行批处理和填充,其中训练集打散。
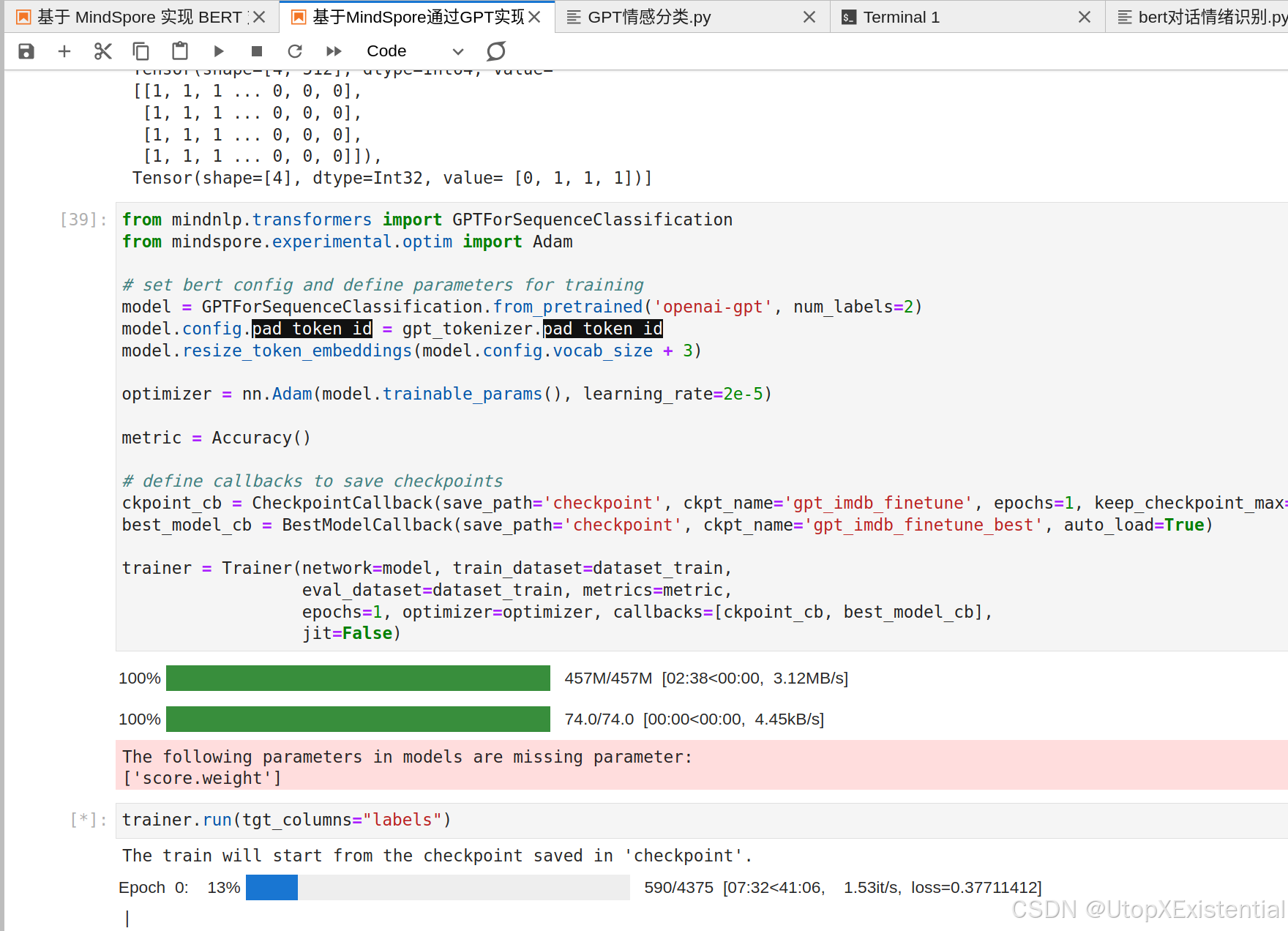
4、预训练模型微调设置:
- 用 mindnlp.transformers.GPTForSequenceClassification 加载预训练的 'openai-gpt' 模型,用于序列分类,配置指定模型的输出标签数量为2(通常是二分类任务)。
- 基于第二个步骤的 tokenzier,为预训练模型配置填充(padding)token ID。
- 为预训练模型配置调整token嵌入层的尺寸(+3,因为第二个步骤手动添加了3个特殊的TOKEN)。
- 定义模型优化器为 nn.Adam ,用于在训练过程中更新模型的参数,学习率设置为2e-5。
- 定义了一个准确率指标 (
metric=mindnlp._legacy.metrics.Accuracy() ),用于评估模型的性能。 - 定义2个回调函数,一个用于保存每个epoch的模型检查点,另一个用于保存最佳模型。
5、开始训练:创建训练器 (mindnlp._legacy.engine.Trainer)并训练,该训练器可以接收模型、训练数据集、评估数据集、评估指标、训练轮数、优化器、回调函数列表以及是否启用JIT编译的选项。
6、创建评估器并评估模型:创建评估器(mindnlp._legacy.engine.Evaluator),用于在测试数据集dataset_test上评估模型的性能。评估器使用了之前定义的预训练模型和评估指标metric。
部分执行结果演示
词向量加载过程
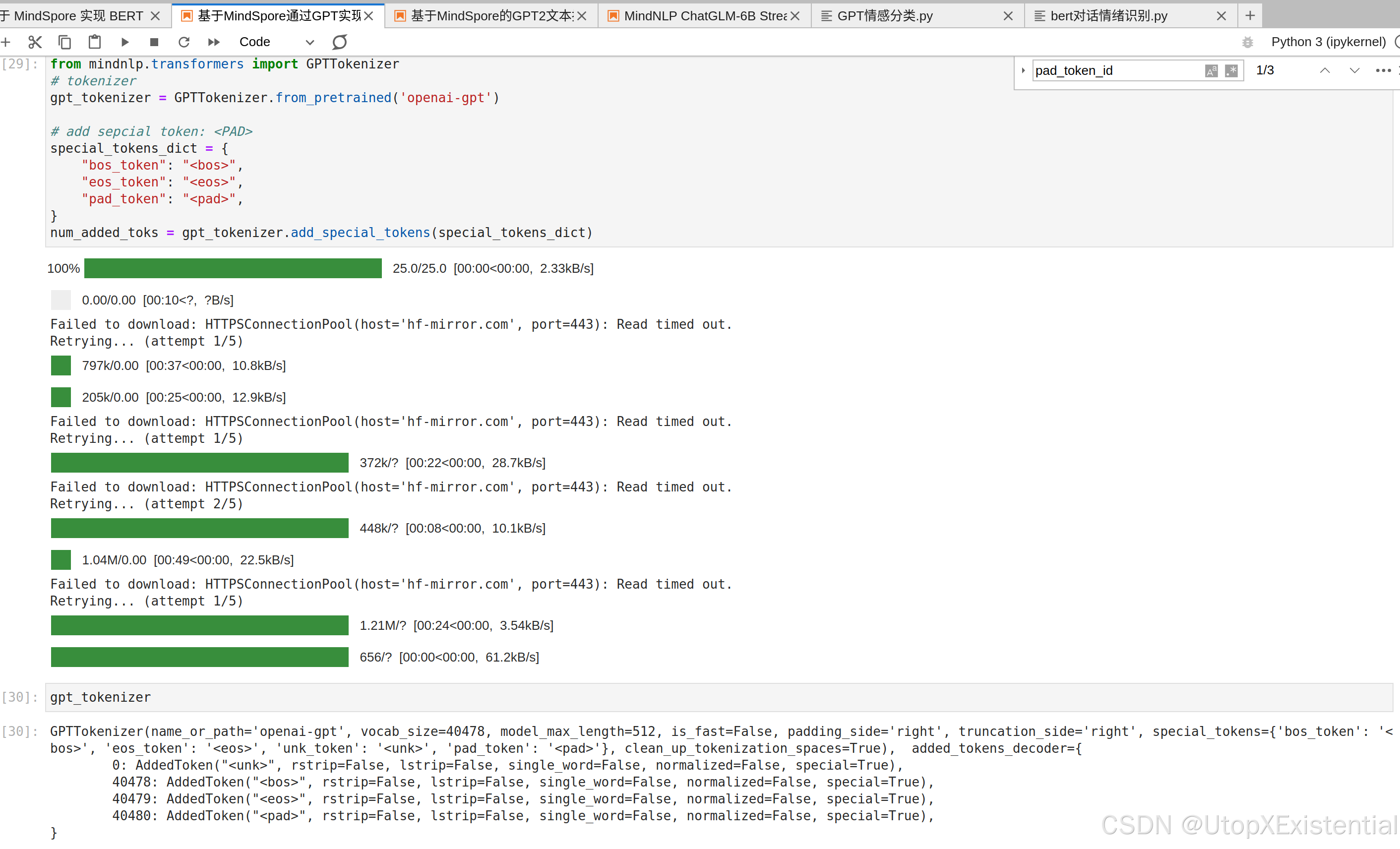
看到词表大小为 40478,模型维度长512,右侧截断,一共有4种特殊的token.
模型结构


模型训练过程


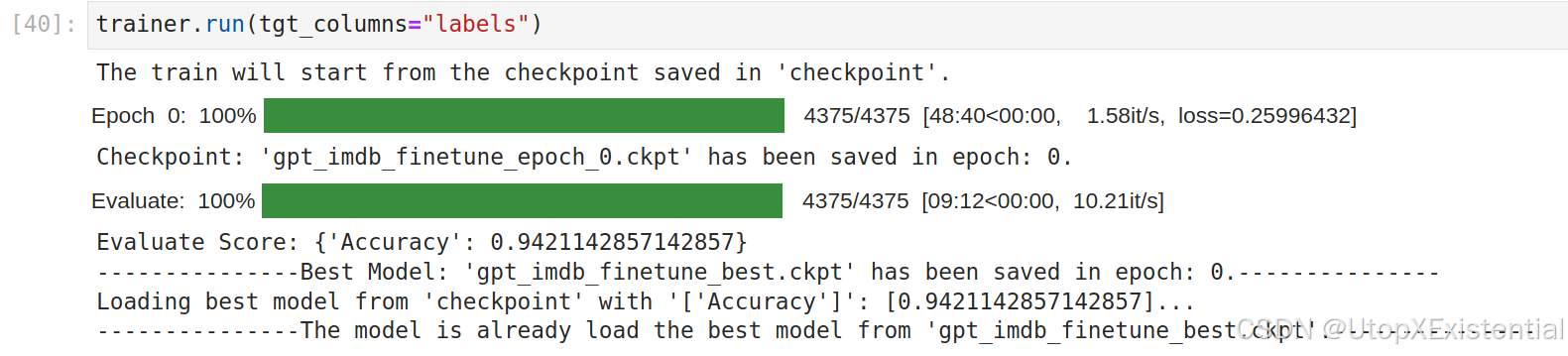 loss降低到了0.2599,精度达到了 0.9421 。一般水平。
loss降低到了0.2599,精度达到了 0.9421 。一般水平。


模型预测过程
代码
import os import numpy as np import mindspore from mindspore.dataset import text, GeneratorDataset, transforms from mindnlp.dataset import load_dataset from mindnlp.transformers import GPTTokenizer from mindspore import nn from mindnlp._legacy.engine import Trainer, Evaluator from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback from mindnlp._legacy.metrics import Accuracy from mindnlp.transformers import GPTForSequenceClassification from mindspore.experimental.optim import Adam def process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False): """ dataset: 待处理的数据集。 tokenizer: 用于将文本转换为token的tokenizer对象. max_seq_len: 文本序列的最大长度,默认为512。 batch_size: 批处理的大小,默认为4。 shuffle: 是否对数据集进行随机打乱,默认为False。 """ ## 判断当前设备目标是否为Ascend(华为的昇腾处理器)。如果是,则is_ascend为True。 is_ascend = mindspore.get_context('device_target') == 'Ascend' def tokenize(text): # 定义了一个内部函数tokenize,用于将文本转换为tokens。 # 根据is_ascend的值来决定是否启用填充策略padding。函数返回token的input_ids和attention_mask。 if is_ascend: tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len) else: tokenized = tokenizer(text, truncation=True, max_length=max_seq_len) return tokenized['input_ids'], tokenized['attention_mask'] if shuffle: ## shuffle参数为True,则对数据集进行打乱 dataset = dataset.shuffle(batch_size) # map dataset ## 用map操作对数据集中的每个文本进行tokenization处理,将文本列text映射为input_ids和attention_mask。 dataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask']) ## 将标签列label的数据类型转换为MindSpore的int32类型,并重命名为labels。 dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels") # # batch dataset ## 根据设备类型将数据集分批处理。如果是在Ascend设备上,直接使用batch操作;否则,使用padded_batch操作来确保每个批次中的序列长度一致,不足部分使用pad token填充。 if is_ascend: dataset = dataset.batch(batch_size) else: dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id), 'attention_mask': (None, 0)}) return dataset imdb_ds = load_dataset('imdb', split=['train', 'test']) imdb_train = imdb_ds['train'] imdb_test = imdb_ds['test'] print("imdb_train data_size: ", imdb_train.get_dataset_size()) print("imdb_test data_size: ", imdb_test.get_dataset_size()) # tokenizer gpt_tokenizer = GPTTokenizer.from_pretrained('openai-gpt') print("openai-gpt GPTTokenizer: ", gpt_tokenizer) # add sepcial token: special_tokens_dict = { "bos_token": "", "eos_token": "", "pad_token": "", } num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict) ## 训练集切分、处理 # split train dataset into train and valid datasets imdb_train, imdb_val = imdb_train.split([0.7, 0.3]) dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True) dataset_val = process_dataset(imdb_val, gpt_tokenizer) dataset_test = process_dataset(imdb_test, gpt_tokenizer) ### 预训练模型加载 # set bert config and define parameters for training model = GPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2) model.config.pad_token_id = gpt_tokenizer.pad_token_id model.resize_token_embeddings(model.config.vocab_size + 3) optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5) metric = Accuracy() # define callbacks to save checkpoints ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='gpt_imdb_finetune', epochs=1, keep_checkpoint_max=2) best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='gpt_imdb_finetune_best', auto_load=True) trainer = Trainer(network=model, train_dataset=dataset_train, eval_dataset=dataset_train, metrics=metric, epochs=1, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb], jit=False) ### 开始训练 trainer.run(tgt_columns="labels") ### 开始评估 evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric) evaluator.run(tgt_columns="labels") 相关内容
热门资讯
绝活儿辅助!广西老友玩老是输怎...
绝活儿辅助!广西老友玩老是输怎么办(辅助挂)都是真的有辅助app(讲解有挂)在进入广西老友玩老是输怎...
法门辅助!福建13水插件(辅助...
法门辅助!福建13水插件(辅助挂)一贯是有辅助技巧(有挂技术)1、许多玩家不知道福建13水插件辅助怎...
办法辅助!潮友会app下载官方...
办法辅助!潮友会app下载官方辅助器(辅助挂)真是真的是有辅助app(有挂教程)该软件可以轻松地帮助...
妙招辅助!邯郸胡乐挂辅助(辅助...
妙招辅助!邯郸胡乐挂辅助(辅助挂)好像存在有辅助插件(有挂方略)1、上手简单,内置详细流程视频教学,...
教程书辅助!乐酷辅助(辅助挂)...
教程书辅助!乐酷辅助(辅助挂)其实存在有辅助脚本(有挂细节)乐酷辅助能透视中分为三种模型:乐酷辅助模...
学习辅助!决战卡五星辅助(辅助...
学习辅助!决战卡五星辅助(辅助挂)本来真的是有辅助软件(有人有挂)学习辅助!决战卡五星辅助(辅助挂)...
绝活辅助!边锋嘉兴麻将辅助器(...
绝活辅助!边锋嘉兴麻将辅助器(辅助挂)真是真的有辅助神器(新版有挂)1、边锋嘉兴麻将辅助器公共底牌简...
举措辅助!枫叶辅助器(辅助挂)...
举措辅助!枫叶辅助器(辅助挂)本来存在有辅助技巧(竟然有挂)1、下载好枫叶辅助器正确养号方法之后点击...
讲义辅助!点我达辅助(辅助挂)...
讲义辅助!点我达辅助(辅助挂)一直存在有辅助技巧(有人有挂)1、点我达辅助辅助器安装包、点我达辅助辅...
模块辅助!威信茶馆有挂的吗(辅...
模块辅助!威信茶馆有挂的吗(辅助挂)一直真的是有辅助脚本(揭秘有挂)1、玩家可以在威信茶馆有挂的吗线...