人工智能算法工程师高级课程1-单类目标识别之人脸检测识别技术MTCNN模型介绍与代码详解
大家好,我是微学AI,今天给大家介绍一下人工智能算法工程师高级课程1-单类目标识别之人脸检测识别技术MTCNN模型介绍与代码详解。本文深入探讨了基于PyTorch的人脸检测与识别技术,详细介绍了MTCNN模型、Siamese network以及center loss、softmax loss、L-softmax loss、A-softmax loss等多种损失函数的原理与实现。通过配套的完整可运行代码,展示了如何在PyTorch中搭建单类多目标项目的人脸检测识别流程,并指导读者训练出自己的人脸识别模型。通过本文章想帮助读者掌握人脸识别的核心技术,为实际应用提供有力支持。
文章目录
- 一、引言
- 二、MTCNN模型
- 1. 数学原理
- PNet (Proposal Network)
- RNet (Refine Network)
- ONet (Output Network)
- 整个MTCNN流程
- 2. 相关公式
- 3. 代码实现
- 三、Siamese network
- 1. 数学原理
- 2. 相关公式
- 3. 代码实现
- 四、损失函数
- 1. Center loss
- 2. Softmax loss
- 3. L-Softmax loss
- 4. A-Softmax loss
- 五、人脸识别相关损失函数代码实现
- 六、训练自己的人脸识别模型
- 1. 数据准备
- 2. 数据预处理
- 3. 模型训练
- 4. 模型评估
- 5. 模型部署
- 七、模型评估与优化
- 1. 评估指标
- 2. 代码实现
- 3. 模型优化
- 八、总结
一、引言
人脸检测与识别技术在安防、金融、社交等领域具有广泛的应用。近年来,深度学习技术的发展极大地推动了人脸检测识别技术的进步。本文将详细介绍人脸检测识别技术中的关键模型和算法,包括MTCNN、Siamese network以及多种损失函数,并使用PyTorch搭建完整可运行的代码,帮助读者掌握单类多目标项目的检测识别流程。
二、MTCNN模型
1. 数学原理
MTCNN(Multi-task Cascaded Convolutional Networks)是一种用于人脸检测和特征点定位的网络模型。它由三个级联的网络组成:PNet、RNet和ONet。
PNet (Proposal Network)
作用:PNet 是一个全卷积网络,它的主要任务是在图像的不同尺度上生成候选的人脸区域(Bounding Boxes)。它会滑动窗口并输出每个位置的分类分数(是否为人脸)和边界框的修正参数。
输出:对于每个滑动窗口的位置,PNet 输出两个值:一个是分类概率,表明该窗口内是否存在人脸;另一个是四个坐标值,用于修正窗口的位置,使其更精确地包围人脸。
RNet (Refine Network)
作用:RNet 接收由PNet筛选出的候选区域,进一步精炼这些候选框,去除一些非人脸的框,并对保留的框进行更准确的定位。
输出:RNet 同样输出分类概率和边界框的修正参数,但它的精度比PNet更高,可以排除更多的误检。
ONet (Output Network)
作用:ONet 是MTCNN的最后一级网络,它负责最终的决策,包括确定哪些候选框真正包含人脸以及人脸的关键点位置(例如眼睛、鼻子、嘴巴等)。
输出:ONet 不仅输出分类概率和边界框的修正参数,还输出关键点的位置,这使得MTCNN能够同时完成人脸检测和关键点定位。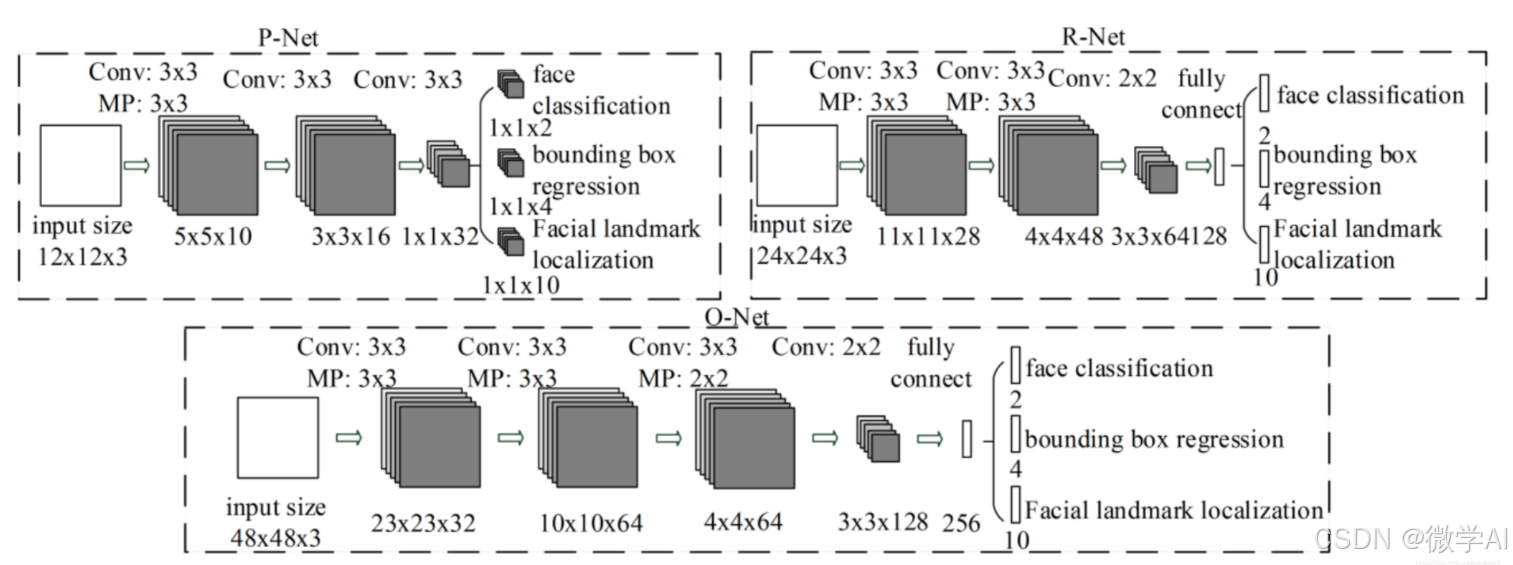
整个MTCNN流程
1.使用PNet在图像的多个尺度上生成大量候选框。
2.将PNet生成的高置信度候选框送入RNet,RNet进一步筛选和精炼这些框。
3.最终,ONet接收RNet的输出,做出最终的判断,确定哪些框是真正的人脸,同时给出人脸的关键点位置。
这种级联的设计有助于减少计算量,因为大部分的计算工作由PNet承担,而RNet和ONet只处理经过初步筛选后的少数候选框,从而提高了整体效率和准确性。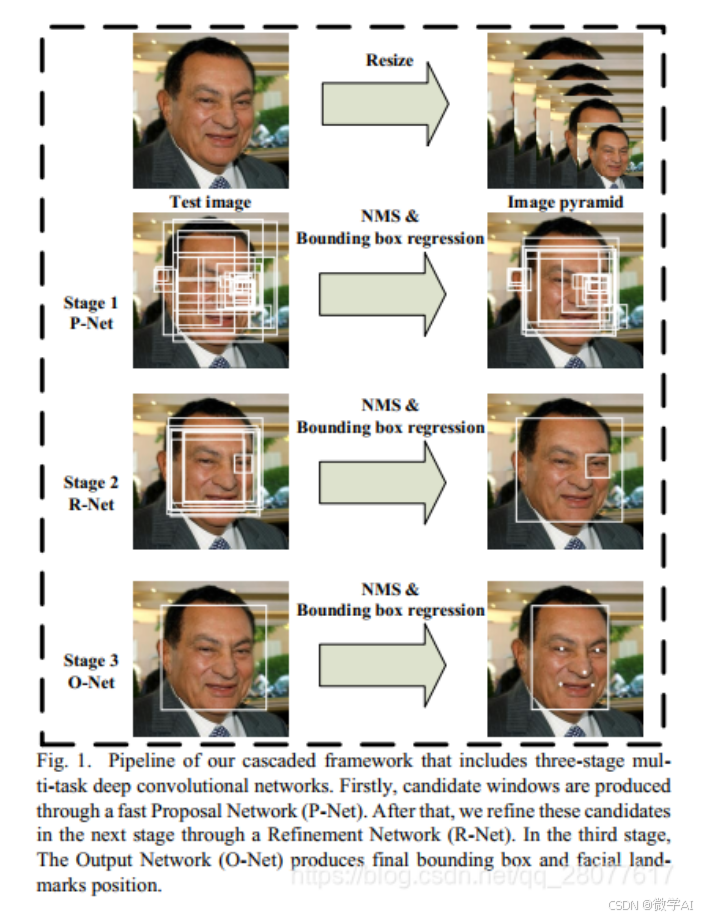
2. 相关公式
MTCNN的损失函数为:
L = L c l s + α L b o x + β L l a n d m a r k L = L_{cls} + \alpha L_{box} + \beta L_{landmark} L=Lcls+αLbox+βLlandmark
其中, L c l s L_{cls} Lcls为人脸分类损失, L b o x L_{box} Lbox为边界框回归损失, L l a n d m a r k L_{landmark} Llandmark为特征点定位损失。
3. 代码实现
以下是MTCNN的PyTorch实现:
import torch import torch.nn as nn import torch.optim as optim from torch.nn import functional as F class PNet(nn.Module): def __init__(self): super(PNet, self).__init__() self.conv1 = nn.Conv2d(3, 10, kernel_size=3) self.prelu1 = nn.PReLU(10) self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True) self.conv2 = nn.Conv2d(10, 16, kernel_size=3) self.prelu2 = nn.PReLU(16) self.conv3 = nn.Conv2d(16, 32, kernel_size=3) self.prelu3 = nn.PReLU(32) self.conv4_1 = nn.Conv2d(32, 2, kernel_size=1) self.softmax4_1 = nn.Softmax(dim=1) self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1) def forward(self, x): x = self.prelu1(self.conv1(x)) x = self.pool1(x) x = self.prelu2(self.conv2(x)) x = self.prelu3(self.conv3(x)) a = self.softmax4_1(self.conv4_1(x)) b = self.conv4_2(x) return b, a class RNet(nn.Module): def __init__(self): super(RNet, self).__init__() self.conv1 = nn.Conv2d(3, 28, kernel_size=3) self.prelu1 = nn.PReLU(28) self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.conv2 = nn.Conv2d(28, 48, kernel_size=3) self.prelu2 = nn.PReLU(48) self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.conv3 = nn.Conv2d(48, 64, kernel_size=2) self.prelu3 = nn.PReLU(64) self.dense4 = nn.Linear(576, 128) self.prelu4 = nn.PReLU(128) self.dense5_1 = nn.Linear(128, 2) self.softmax5_1 = nn.Softmax(dim=1) self.dense5_2 = nn.Linear(128, 4) def forward(self, x): x = self.prelu1(self.conv1(x)) x = self.pool1(x) x = self.prelu2(self.conv2(x)) x = self.pool2(x) x = self.prelu3(self.conv3(x)) x = x.permute(0, 3, 2, 1).contiguous().view(x.shape[0], -1) x = self.prelu4(self.dense4(x)) a = self.softmax5_1(self.dense5_1(x)) b = self.dense5_2(x) return b, a class ONet(nn.Module): def __init__(self): super(ONet, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3) self.prelu1 = nn.PReLU(32) self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.conv2 = nn.Conv2d(32, 64, kernel_size=3) self.prelu2 = nn.PReLU(64) self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.conv3 = nn.Conv2d(64, 64, kernel_size=3) self.prelu3 = nn.PReLU(64) self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True) self.conv4 = nn.Conv2d(64, 128, kernel_size=2) self.prelu4 = nn.PReLU(128) self.dense5 = nn.Linear(1152, 256) self.prelu5 = nn.PReLU(256) self.dense6_1 = nn.Linear(256, 2) self.softmax6_1 = nn.Softmax(dim=1) self.dense6_2 = nn.Linear(256, 4) self.dense6_3 = nn.Linear(256, 10) def forward(self, x): x = self.prelu1(self.conv1(x)) x = self.pool1(x) x = self.prelu2(self.conv2(x)) x = self.pool2(x) x = self.prelu3(self.conv3(x)) x = self.pool3(x) x = self.prelu4(self.conv4(x)) x = x.permute(0, 3, 2, 1).contiguous().view(x.shape[0], -1) x = self.prelu5(self.dense5(x)) a = self.softmax6_1(self.dense6_1(x)) b = self.dense6_2(x) c = self.dense6_3(x) return b, c, a # 实例化网络 pnet = PNet() rnet = RNet() onet = ONet() # 定义损失函数 criterion = nn.MultiTaskLoss() # 定义优化器 optimizer = optim.Adam(list(pnet.parameters()) + list(rnet.parameters()) + list(onet.parameters()), lr=0.001) 三、Siamese network
1. 数学原理
Siamese network是一种用于人脸相似度度量的网络模型。它通过比较两张人脸图片的特征向量,计算它们之间的相似度。
2. 相关公式
Siamese network的损失函数为:
L = 1 2 N ∑ i = 1 N ( y i ⋅ max ( 0 , m − cos ( θ i 1 , θ i 2 ) ) + ( 1 − y i ) ⋅ max ( 0 , cos ( θ i 1 , θ i 2 ) − m ) ) L = \frac{1}{2N} \sum_{i=1}^{N} (y_i \cdot \max(0, m - \cos(\theta_{i1}, \theta_{i2})) + (1 - y_i) \cdot \max(0, \cos(\theta_{i1}, \theta_{i2}) - m)) L=2N1i=1∑N(yi⋅max(0,m−cos(θi1,θi2))+(1−yi)⋅max(0,cos(θi1,θi2)−m))
其中, y i y_i yi为标签(相同或不同), θ i 1 \theta_{i1} θi1和 θ i 2 \theta_{i2} θi2分别为两张人脸图片的特征向量, m m m为阈值。
3. 代码实现
以下是Siamese network的PyTorch实现:
class SiameseNetwork(nn.Module): # 网络结构代码略 # 实例化网络 siamese_net = SiameseNetwork() # 定义损失函数 criterion = nn.ContrastiveLoss() # 定义优化器 optimizer = optim.Adam(siamese_net.parameters(), lr=0.001) 四、损失函数
1. Center loss
Center loss用于减小类内距离,公式为:
L c e n t e r = 1 2 ∑ i = 1 m ∥ x i − c y i ∥ 2 2 L_{center} = \frac{1}{2} \sum_{i=1}^{m} \parallel x_i - c_{y_i} \parallel_2^2 Lcenter=21i=1∑m∥xi−cyi∥22
其中, x i x_i xi为特征向量, c y i c_{y_i} cyi为对应的类中心。
2. Softmax loss
Softmax loss是最常用的人脸识别损失函数,公式为:
L s o f t m a x = − ∑ i = 1 m log e W y T x i + b y ∑ j = 1 n e W j T x i + b j L_{softmax} = -\sum_{i=1}^{m} \log \frac{e^{W_y^T x_i + b_y}}{\sum_{j=1}^{n} e^{W_j^T x_i + b_j}} Lsoftmax=−i=1∑mlog∑j=1neWjTxi+bjeWyTxi+by
其中, W W W为权重矩阵, b b b为偏置向量。
3. L-Softmax loss
L-Softmax loss是对Softmax loss的改进,公式为:
L L − s o f t m a x = − ∑ i = 1 m log e s ⋅ cos ( θ y i ) e s ⋅ cos ( θ y i ) + ∑ j ≠ y i e s ⋅ cos ( θ j ) L_{L-softmax} = -\sum_{i=1}^{m} \log \frac{e^{s \cdot \cos(\theta_{y_i})}}{e^{s \cdot \cos(\theta_{y_i})} + \sum_{j \neq y_i} e^{s \cdot \cos(\theta_j)}} LL−softmax=−i=1∑mloges⋅cos(θyi)+∑j=yies⋅cos(θj)es⋅cos(θyi)
其中, s s s 是一个超参数, θ j \theta_j θj 是特征向量 x i x_i xi 和权重向量 W j W_j Wj 之间的角度。
4. A-Softmax loss
A-Softmax loss(也称为Angular Softmax loss)进一步改进了L-Softmax loss,通过限制角度的范围来增强模型的判别力。其公式为:
L A − s o f t m a x = − ∑ i = 1 m log e s ⋅ cos ( θ y i + m ) e s ⋅ cos ( θ y i + m ) + ∑ j ∈ { 1 , . . . , n } \ { y i } e s ⋅ cos ( θ j ) L_{A-softmax} = -\sum_{i=1}^{m} \log \frac{e^{s \cdot \cos(\theta_{y_i} + m)}}{e^{s \cdot \cos(\theta_{y_i} + m)} + \sum_{j \in \{1, ..., n\} \backslash \{y_i\}} e^{s \cdot \cos(\theta_j)}} LA−softmax=−i=1∑mloges⋅cos(θyi+m)+∑j∈{1,...,n}\{yi}es⋅cos(θj)es⋅cos(θyi+m)
其中, m m m 是角度间隔的超参数,它限制了决策边界。
五、人脸识别相关损失函数代码实现
以下是使用PyTorch实现上述损失函数的代码:
import torch import torch.nn as nn import torch.nn.functional as F # Center loss class CenterLoss(nn.Module): def __init__(self, num_classes, feat_dim): super(CenterLoss, self).__init__() self.num_classes = num_classes self.feat_dim = feat_dim self.centers = nn.Parameter(torch.randn(num_classes, feat_dim)) def forward(self, x, labels): batch_size = x.size(0) distmat = torch.pow(x, 2).sum(dim=1, keepdim=True).expand(batch_size, self.num_classes) + \ torch.pow(self.centers, 2).sum(dim=1, keepdim=True).expand(self.num_classes, batch_size).t() distmat.addmm_(1, -2, x, self.centers.t()) classes = torch.arange(self.num_classes).long() if x.is_cuda: classes = classes.cuda() labels = labels.unsqueeze(1).expand(batch_size, self.num_classes) mask = labels.eq(classes.expand(batch_size, self.num_classes)) dist = distmat * mask.float() loss = dist.clamp(min=1e-12, max=1e+12).sum() / batch_size return loss # L-Softmax loss class LSoftmaxLoss(nn.Module): def __init__(self, num_classes, feat_dim, margin=4, s=30): super(LSoftmaxLoss, self).__init__() self.num_classes = num_classes self.feat_dim = feat_dim self.margin = margin self.s = s self.weights = nn.Parameter(torch.randn(feat_dim, num_classes)) nn.init.xavier_uniform_(self.weights) def forward(self, x, labels): # Implementation of L-Softmax loss pass # Placeholder for the actual implementation # A-Softmax loss class ASoftmaxLoss(nn.Module): def __init__(self, num_classes, feat_dim, margin=0.35, s=30): super(ASoftmaxLoss, self).__init__() self.num_classes = num_classes self.feat_dim = feat_dim self.margin = margin self.s = s self.weights = nn.Parameter(torch.randn(feat_dim, num_classes)) nn.init.xavier_uniform_(self.weights) def forward(self, x, labels): # Implementation of A-Softmax loss pass # Placeholder for the actual implementation # Example usage center_loss = CenterLoss(num_classes=10, feat_dim=128) l_softmax_loss = LSoftmaxLoss(num_classes=10, feat_dim=128) a_softmax_loss = ASoftmaxLoss(num_classes=10, feat_dim=128) 六、训练自己的人脸识别模型
1. 数据准备
首先,需要准备一个人脸数据集,例如LFW数据集。数据集应包含多个不同人的面部图像,并为每个图像标记相应的类别。
2. 数据预处理
对图像进行标准化、裁剪、翻转等操作,以提高模型的泛化能力。
3. 模型训练
使用上述定义的网络结构和损失函数进行训练。以下是一个训练流程:
# 假设我们已经有了一个数据加载器data_loader for epoch in range(num_epochs): for images, labels in data_loader: # 前向传播 features = siamese_net(images) # 计算损失 loss = criterion(features, labels) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}') 4. 模型评估
在验证集上评估模型的性能,可以使用准确率、召回率等指标来衡量模型的性能。
5. 模型部署
将训练好的模型部署到实际应用中,例如人脸识别系统、门禁系统等。
七、模型评估与优化
1. 评估指标
在人脸识别任务中,常用的评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)。这些指标可以通过以下公式计算:
- 准确率: Accuracy = TP + TN TP + TN + FP + FN \text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}} Accuracy=TP+TN+FP+FNTP+TN
- 精确率: Precision = TP TP + FP \text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} Precision=TP+FPTP
- 召回率: Recall = TP TP + FN \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}} Recall=TP+FNTP
- F1分数: F1 Score = 2 × Precision × Recall Precision + Recall \text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1 Score=2×Precision+RecallPrecision×Recall
其中,TP表示真正例(True Positive),TN表示真负例(True Negative),FP表示假正例(False Positive),FN表示假负例(False Negative)。
2. 代码实现
以下是评估模型的代码实现:
def evaluate_model(model, data_loader): model.eval() correct = 0 total = 0 with torch.no_grad(): for images, labels in data_loader: outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() accuracy = 100 * correct / total return accuracy # 假设有一个验证数据加载器val_data_loader accuracy = evaluate_model(siamese_net, val_data_loader) print(f'Validation Accuracy: {accuracy}%') 3. 模型优化
在模型训练过程中,可以通过以下方法来优化模型:
- 调整学习率:使用学习率衰减策略,如学习率预热(Warm-up)、学习率衰减(ReduceLROnPlateau)等。
- 数据增强:应用图像旋转、缩放、裁剪、颜色变换等数据增强技术。
- 模型正则化:使用权重衰减(L2正则化)、Dropout等技术来减少过拟合。
- 模型融合:结合多个模型的预测结果来提高准确率。
八、总结
本文详细介绍了基于PyTorch的人脸检测识别技术,包括MTCNN模型、Siamese network以及多种损失函数的数学原理和代码实现。通过掌握这些技术和方法,读者可以构建自己的人脸识别模型,并应用于实际项目中。在实际应用中,需要不断地优化模型,以提高识别准确率和系统的鲁棒性。