HTTP背后的故事:理解现代网络如何工作的关键(一)
一.HTTP是什么
概念:1.HTTP (全称为 "超文本传输协议") 是一种应用非常广泛的 应用层协议。2.HTTP 诞生与1991年. 目前已经发展为最主流使用的一种应用层协议.
3.HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3 基于 UDP 实现) 4.目前我们主要使用的还是 HTTP1.1 和 HTTP2.0。 在TCP/IP 五层协议栈角度,HTTP属于是在应用层的协议。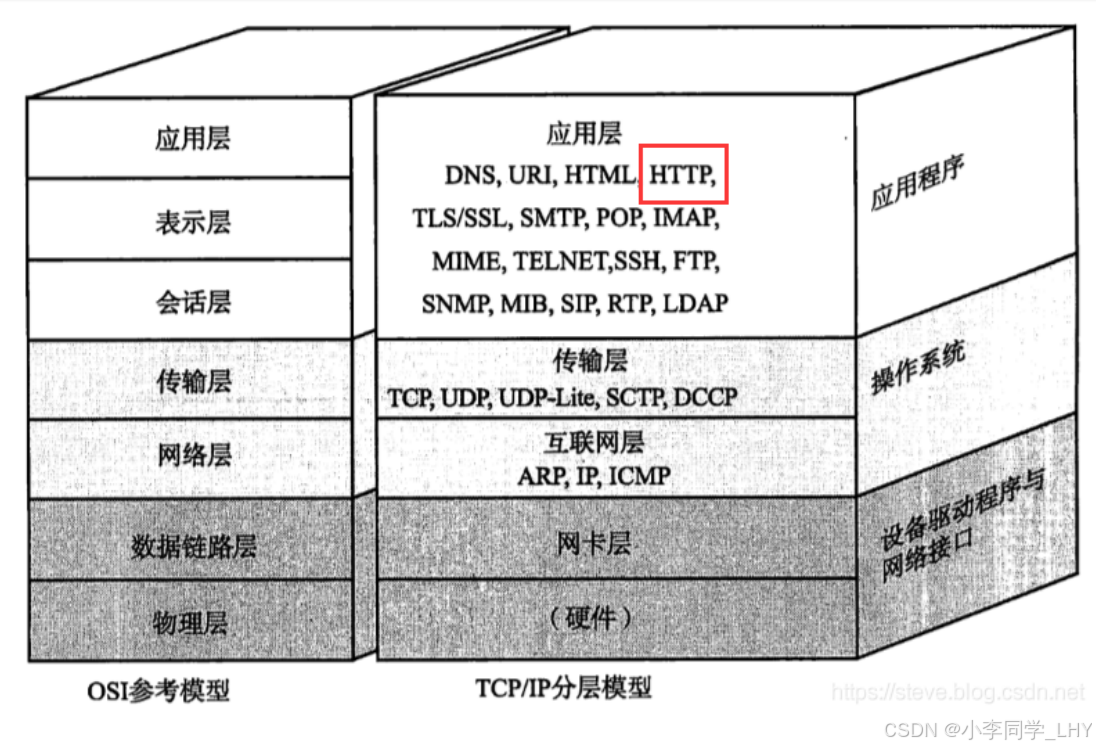 我们知道,其实Java程序员使用Java的最主要的场景就是做网站,而网站=后端(HTTP服务器)+前端(浏览器), 我们平时打开一个网站, 就是通过 HTTP 协议来传输数据的,而HTTP也是基于TCP来实现的。
我们知道,其实Java程序员使用Java的最主要的场景就是做网站,而网站=后端(HTTP服务器)+前端(浏览器), 我们平时打开一个网站, 就是通过 HTTP 协议来传输数据的,而HTTP也是基于TCP来实现的。 补充:如何理解超文本呢?一张图解释就可以了。

二.HTTP的作用
2.1理解 HTTP 协议的工作过程
概念:HTTP 协议最主要的应用场景就是网站.,浏览器和服务器之间进行传输数据。客户端(手机,PC),和服务器之间的数据传输,也很可能是 HTTP。 比如我在浏览器访问CSDN的服务器,服务器再给我返回请求。

 注意:
注意:

2.2理解应用层协议
我们已经学过 TCP/IP , 已经知道目前数据能从客户端进程经过路径选择跨网络传送到服务器端进程 [ IP+Port ]. 可是,仅仅把数据从A点传送到B点就完了吗?这就好比,在淘宝上买了一部手机,卖家[ 客户端 ]把手机通过顺丰[ 传送+路径选择 ] 送到买家 [ 服务器 ] 手里就完了吗? 当然不是,买家还要使用这款产品,还要在使用之后,给卖家打分评论。这层协议叫做应用层协议。而应用是有不同的场景的,所以应用层协议是有不同种类的,其中经典协议之一的HTTP就是其中的佼佼者.
再回到我们刚刚说的买手机的例子,顺丰相当于 TCP/IP 的功能,那么买回来的手机都附带了说 明书【产品介绍,使用介绍,注意事项等】,而该说明书指导用户该如何使用手机,此时的说明书可以理解为用户层协议。
三.HTTP报文格式
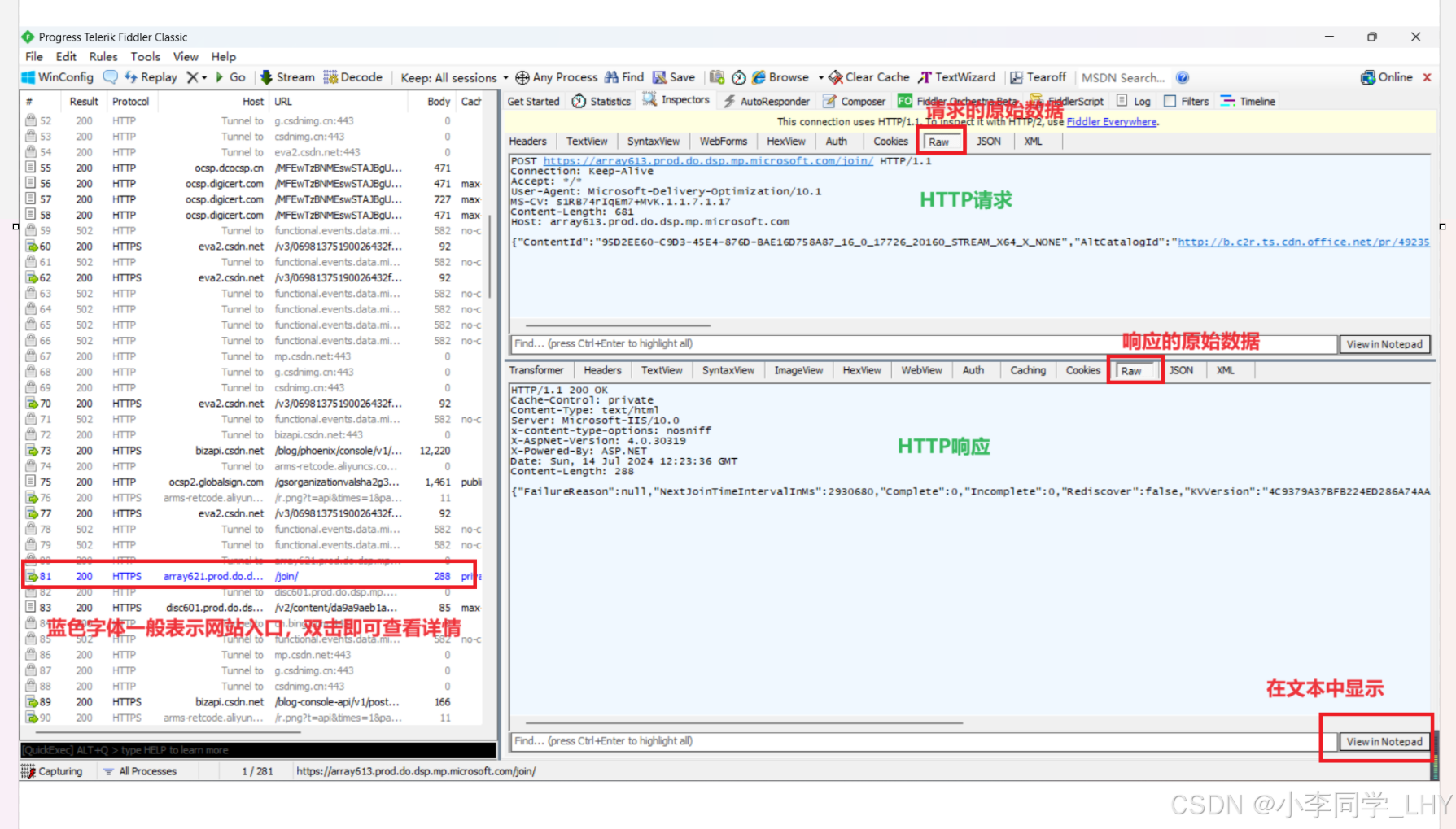
3.1抓包工具的使用
要查看报文格式,要先下载一个抓包工具,抓包工具本质上是一个"代理程序”,能够获取到网络上传输的数据,并显示出来,从而给程序员提供一些参考。这里的抓包工具使用Fiddler,这是专注于HTTP的抓包。
下载地址:
Web Debugging Proxy and Troubleshooting Tools|Fiddler (telerik.com)

 如果是学生使用的话,使用经典版即可,是免费的。
如果是学生使用的话,使用经典版即可,是免费的。
除了上述操作之外,另外,还需要关闭电脑上本身的代理程序.
有的小伙伴为了翻墙,电脑上本身就有代理(单独的程序/浏览器插件),确保你其他的代理都是关闭状态,因为Fiddler 也是一个代理程序代理之间可能会冲突。

代理就可以简单理解为一个跑腿小弟. 你想买罐冰阔落, 又不想自己下楼去超市, 那么就可以把钱给你的跑腿小弟, 跑腿小弟来到超市把钱给超市老板, 再把冰阔落拿回来交到你手上. 这个过程中, 这个跑腿小弟对于 "你" 和 "超市老板" 之间的交易细节, 是非常清楚的.浏览器访问 csdn.com 时, 就会把 HTTP 请求先发给 Fiddler, Fiddler 再把请求转发给 csdn的服务器. 当 csdn服务器返回数据时, Fiddler 拿到返回数据, 再把数据交给浏览器.因此 Fiddler 对于浏览器和 csdn服务器之间交互的数据细节, 都是非常清楚的.
补充:
1.打开一个网站,其实浏览器和服务器之间进行的 HTTP 交互不是只有一次,而是通常有很多次!!
第一次交互是拿到这个页面的 html.
2.html 还会依赖其他的 css 和 js, 图片等. html 被浏览器加载之后,又会发一些其他的 http 请求,获取到 CSS,js 等
3.当执行 js 的时候js代码里可能又要触发很多的 http 请求,获取到一些数据.....
3.1HTTP请求
HTTP请求的基本格式包含四个部分。
1.首行

2.请求头(header)

从第二行,一直到后面都是请求头,类似于 TCP 报头/IP 报头.重要的属性信息
咱们这里是文本的方式组织的.
报头中包含了很多的键值对.每个键值对占一行.键和值之间使用:空格 来分割
此处的键值对都有哪些,都是什么含义? 全都是 HTTP 协议规定的
3.空行
请求头最下面会有一个空行,这个空行就表示结束标记
4.正文(body)
http的载荷部分,有的http请求有body,有的就没有。
总结:
首行: [方法] + [url] + [版本] Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部 分结束 Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有 一个Content-Length属性来标识Body的长度;3.2HTTP响应
HTTP响应的基本格式包含四个部分。
1.首行
 2.响应头(键值对)
2.响应头(键值对)

3.空行

4.响应正文(body) 载荷

总结:

四.URL
概念:平时我们俗称的 "网址" 其实就是说的 URL (Uniform Resource Locator 统一资源定位符),描述一个网络上的资源位置。
互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它. URL 的详细规则由 因特网标准RFC1738 进行了约定. (https://datatracker.ietf.org/doc/html/rfc1738)顺便可以认识一下它的小弟,URI(唯一资源标识符)
URL格式:

片段标识符:
用来标识当前页面的某个部分
通过不同的片段标识可以完成页面内的跳转.


举一个简单的例子:
就像是我们生活中用来找到特定地方或事物的地址或导航指令。想象一下,你想要去参观一个远在他乡的朋友的新家,URL就是这个过程中不可或缺的“指南”。
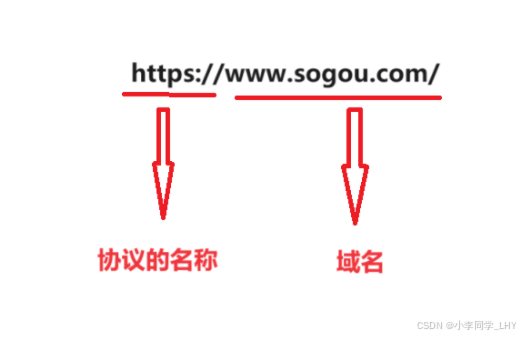
协议类型(Protocol):就像是你选择的交通方式。在这个例子中,没有直接对应的“协议”,但我们可以想象为“步行”、“驾车”或“乘坐公共交通”。URL中的协议部分(如
http://或https://)告诉浏览器或系统如何与资源通信,就像是你决定是开车去还是坐公交去。域名(Domain Name):类似于地址中的“北京市海淀区中关村大街XX号XX小区”。这是URL中最容易识别和记忆的部分,它指向了一个特定的网站或资源的位置。在我们的例子中,小区名就像是网站的域名,比如
www.example.com。路径(Path):指的是从域名指向的具体资源的位置,就像“1号楼2单元301室”。在URL中,路径部分详细说明了要访问的资源在服务器上的位置。例如,在URL
https://www.example.com/news/article123.html中,/news/article123.html就是路径,它告诉服务器你想要查看的是“news”目录下的“article123.html”文件。查询字符串(Query String):有时你可能需要在到达具体地址时提供一些额外的信息,比如你朋友的门牌号或者房间号(虽然这个例子中没有直接对应)。在URL中,查询字符串通过
?后跟一系列键值对(如?name=John&age=30)来传递这些额外信息。它告诉服务器你想要查看的页面需要特别关注或处理哪些数据。片段标识符(Fragment Identifier):这更像是进入房间后,你告诉朋友你想直接去看书架上的某本书。在URL中,片段标识符通过
#后跟一个标识符(如#section2)来指定页面上的一个特定部分。浏览器会直接滚动到该标识符对应的位置,而不是加载整个新页面。
这是一个最简单的URL:
补充:
1.如何找到网络上资源位置
(1) 通过 ip 地址知道服务器在哪
(2) 过 端口号 知道程序是哪个
(3) 过 路径 知道是访问哪个资源
2.查询字符串,是客户端给服务器传递信息的重要途径
这里的组织方式是按照键值对的方式来组织的 (又是键值对
这里的键值对的内容,都是程序员自定义的
结合上述的 IP 地址,端口号,路径,查询字符串,就可以描述出一个网络资源了。
4.1关于URL encode
在此之前先说明query string
什么是query string?
概念:query String(查询字符串)是URL中用于传递额外信息给服务器的一部分。它通常位于URL的末尾,紧跟在路径(Path)之后,由问号(?)开始,后面跟着一系列由&符号分隔的键值对(Key-Value Pairs)。每个键值对由一个等号(=)连接键和值。
假设有一个搜索引擎的URL,用户想要搜索“apple”这个词。该URL可能看起来像这样:
https://www.example.com/search?query=apple
在这个例子中,查询字符串是?query=apple。它包含一个键(query)和一个值(apple),告诉服务器用户想要搜索的关键词是“apple”。
如果搜索请求包含多个参数,它们可以通过&符号分隔。例如,如果用户想要同时指定搜索的关键词和结果页面的排序方式,URL可能看起来像这样:
https://www.example.com/search?query=apple&sort=relevance
在这个例子中,查询字符串包含了两个键值对:query=apple 和 sort=relevance。服务器将解析这些参数,并根据用户的请求返回相关的搜索结果,同时按照相关性进行排序。
query string 里都是是自定义的键值对。
在 URL 中,本身有些特殊符号具有特定的含义,比如:/ :? @ .....
如果 url 的 query string 中也包含同样的符号,咋办?
如果直接写进去,可能就会使服务器/浏览器解析失败!!就访问不了服务器
汉字也是要转义的,汉字的 utf8 / gbk 等编码值其中可能某个字节就恰好和某个符号的 ascii 码一致~~
靠谱的方法就是对上述符号进行“转义“,
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式 此时的c++中的"+" 被转义成了 "%2B"。同时urldecode就是urlencode的逆过程;
此时的c++中的"+" 被转义成了 "%2B"。同时urldecode就是urlencode的逆过程;