sql — 窗口函数
1. 基本介绍
1.1 窗口函数介绍
窗口函数是SQL中的一种强大工具,用于在查询结果中进行分析和计算。
与常规聚合函数不同,窗口函数可以在不影响查询结果集的情况下,对结果集中的每一行应用函数,生成额外的信息,例如排名、累计和等。这些函数可以根据定义的窗口范围动态地计算值,而不是像常规聚合函数那样对整个数据集进行计算。
窗口函数通常与OVER子句一起使用,OVER子句定义了窗口的范围,可以指定分区、排序规则等。
1.2 窗口函数分类
窗口函数可以分为排序窗口函数和统计窗口函数两大类。
排序窗口函数主要用于对数据进行排序和排名,包括row_number、rank、dense_rank、percent_rank、ntile;
统计窗口函数则用于进行统计计算,包括count、sum、avg、min、max、first_value、last_value、lag、lead、cume_dist。
2. 样例数据
2.1 样例数据SQL
CREATE TABLE Sales (id INT,region VARCHAR(50),amount DECIMAL(10, 2));INSERT INTO Sales (id, region, amount) VALUES(1, 'North', 1000.50),(2, 'North', 1500.75),(3, 'South', 800.25),(4, 'West', 1200.00),(5, 'East', 2000.30);
3.各个窗口函数介绍
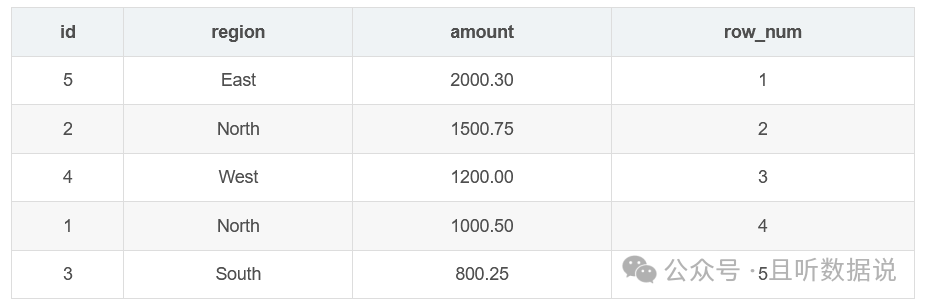
3.1 row_number()窗口函数
row_number函数为结果集中的每一行分配一个唯一的整数,按照指定的排序顺序进行排列。
SELECT id, region, amount, ROW_NUMBER() OVER (ORDER BY amount DESC) AS row_numFROM Sales;
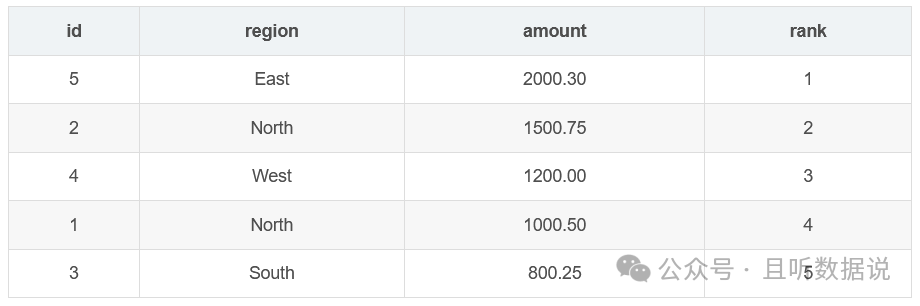
3.2 rank ()窗口函数
rank函数为结果集中的每一行分配一个排名,如果有相同数值,则会跳过相同排名并继续递增。(不连续排名)
rank()函数的结果是:1, 2, 3, 3, 5, 6。
SELECT id, region, amount, RANK() OVER (ORDER BY amount DESC) AS rankFROM Sales;
分区
RANK() OVER (PARTITION BY column ORDER BY column) AS rank_column
PARTITION BY子句用于指定分区列,根据该列的值将数据分成不同的分区。ORDER BY子句用于指定排序列,根据该列的值对每个分区内的行进行排序。
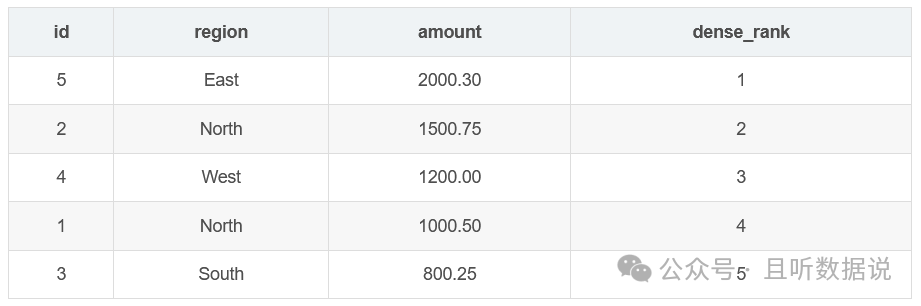
3.3 dense_rank()窗口函数
dense_rank函数为结果集中的每一行分配一个排名,与rank函数类似,但是在遇到相同数值时,dense_rank不会跳过相同排名,而是连续分配相同的排名。(连续排名)
dense_rank()函数的结果是:1, 2, 3, 3, 4, 5
SELECT id, region, amount, DENSE_RANK() OVER (ORDER BY amount DESC) AS dense_rankFROM Sales;
3.4 percent_rank()窗口函数
percent_rank函数计算每一行在排序结果中的相对排名,返回一个介于0和1之间的小数值,用来表示行在排序结果中的相对位置。
SELECT id, region, amount, PERCENT_RANK() OVER (ORDER BY amount DESC) AS percent_rankFROM Sales;
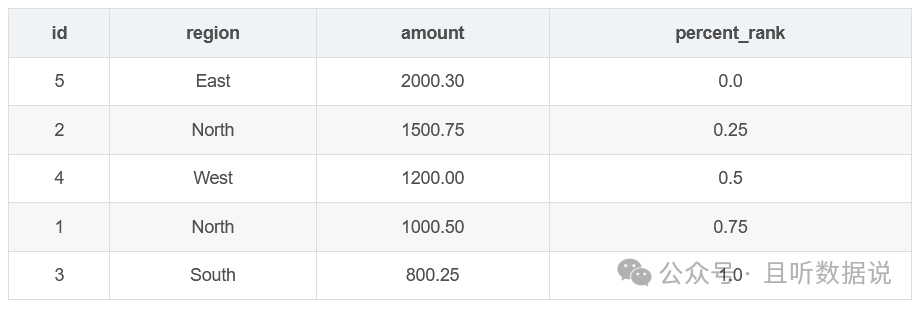
3.5 ntile(n)窗口函数
ntile函数将结果集分割成指定数量的桶,并为每个桶分配一个编号,确保每个桶中的行数量尽可能均匀。
SELECT id, region, amount, NTILE(2) OVER (ORDER BY amount DESC) AS ntileFROM Sales;
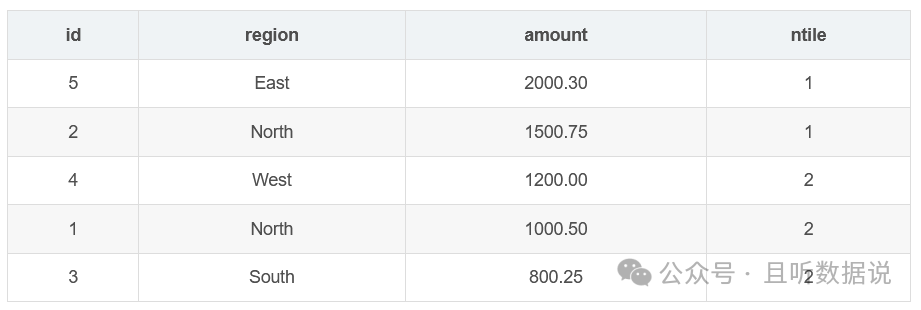
3.6 count(*)窗口函数
count函数计算结果集中行的数量,可以结合分组函数使用,用于统计分组内的行数。
SELECT id, region, amount, COUNT(*) OVER (PARTITION BY region) AS region_countFROM Sales;
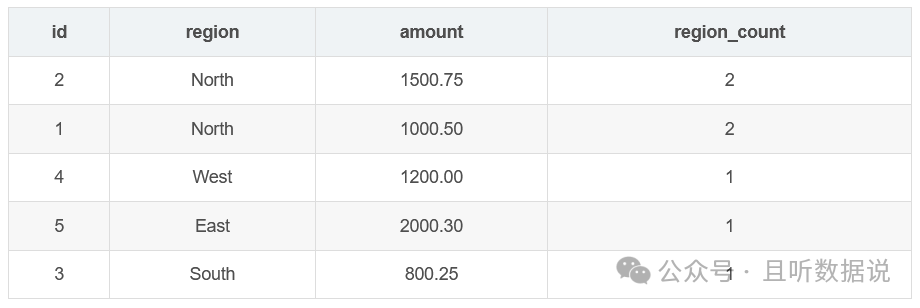
3.7 sum( ) 窗口函数
sum函数计算指定列的总和,并将结果添加到每一行。
SELECT id, region, amount, SUM(amount) OVER () AS total_salesFROM Sales;
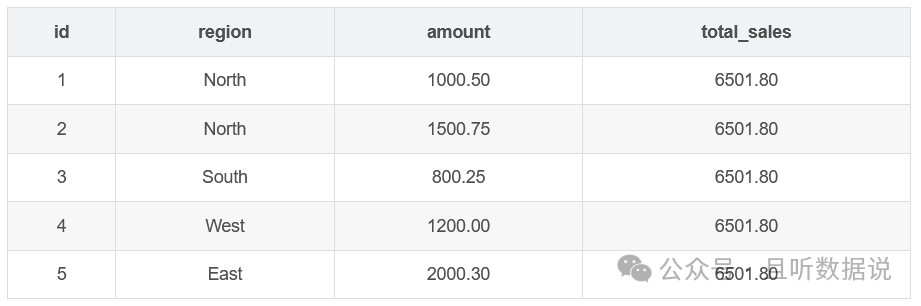
3.8 min() 窗口函数
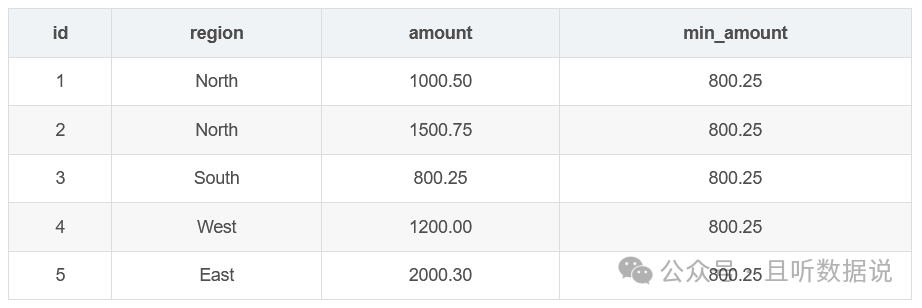
min函数计算指定列的最小值,并将结果添加到每一行。
SELECT id, region, amount, MIN(amount) OVER () AS min_amountFROM Sales;
3.9 max() 窗口函数
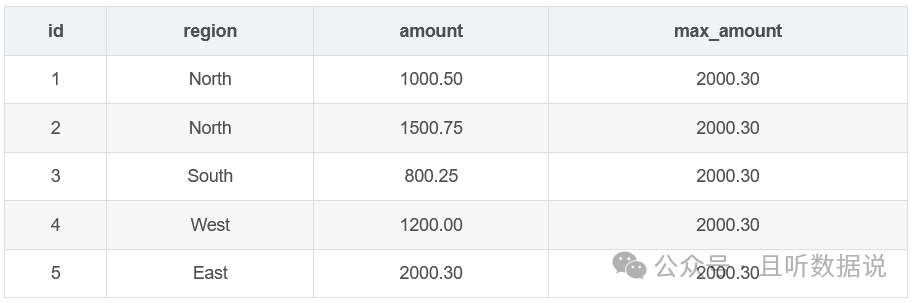
max函数计算指定列的最大值,并将结果添加到每一行。
SELECT id, region, amount, MAX(amount) OVER () AS max_amountFROM Sales;
3.10 avg () 窗口函数
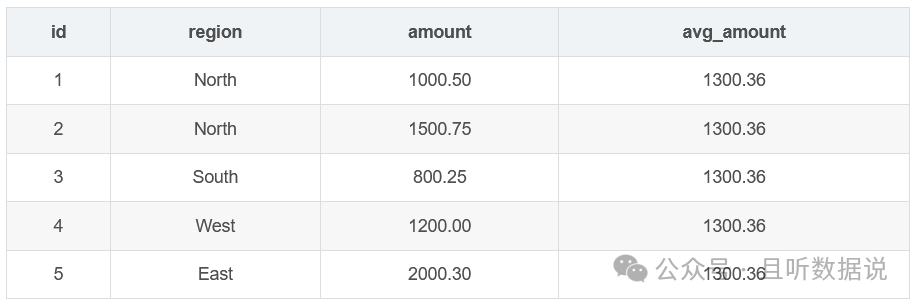
avg函数计算指定列的平均值,并将结果添加到每一行。
SELECT id, region, amount, AVG(amount) OVER () AS avg_amountFROM Sales;
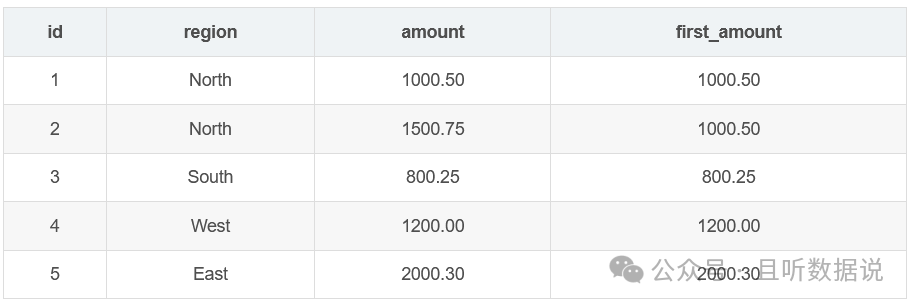
3.11 first_value () 窗口函数
first_value() 函数返回分组内的第一个值,并将其添加到每一行。
SELECT id, region, amount, FIRST_VALUE(amount) OVER (PARTITION BY region ORDER BY id) AS first_amountFROM Sales;