基于Python给出的PDF文档转Markdown文档的方法
注:网上有很多将Markdown文档转为PDF文档的方法,但是却很少有将PDF文档转为Markdown文档的方法。就算有,比如某些网站声称可以将PDF文档转为Markdown文档,尝试过,不太符合自己的要求,而且无法保证文档没有泄露风险。于是本人为了解决这个问题,借助GPT(能使用GPT镜像或者有条件直接使用GPT的,反正能调用GPT接口就行)生成Python代码来完成这个功能。笔记、代码难免存在问题,若有错误,欢迎指出。本次笔记记录于24.1.21。(中途运行时,发现代码中存在bug从而对代码进行了更新,比如md文件的相对路径需要进行URL编码,否则可能会因空格等原因导致无法预览图片。)
一、使用需求
Markdown文档与PDF等文档,个人认为有以下优点,所以本人在某些时候更喜欢使用md文件:1.Markdown文档添加书签更加方便快捷。2.在github/gitee上打开仓库即可直接浏览。3.便于编辑。PDF很难继续编辑,想要添加内容非常麻烦,不如Markdown文档来的直接。
二、使用效果
注:图中PDF是本人去网上随便找的。
三、本次Python代码的思路
代码思路: - 导入必要的库,包括os、fitz(PyMuPDF)和Image(Pillow)。 - 定义一个函数convert_pdf_to_images,该函数将PDF文档转换为图像列表。它使用PyMuPDF库获取PDF页面的图像数据,然后使用Pillow库创建图像对象,并将这些图像保存到指定目录。 - 定义另一个函数save_images_to_markdown,该函数将图像列表保存到Markdown文件中。它使用用户提供的相对路径,在Markdown文件中插入图像路径。 - 在__main__部分,替换相应的文件路径,并调用上述两个函数完成PDF到Markdown的转换。 四、本次笔记提供的Python代码
""" 1.代码用途:完成PDF文件到Markdown文件的转换 2.代码思路: - 导入必要的库,包括os、fitz(PyMuPDF)和Image(Pillow)。 - 定义一个函数convert_pdf_to_images,该函数将PDF文档转换为图像列表。它使用PyMuPDF库获取PDF页面的图像数据,然后使用Pillow库创建图像对象,并将这些图像保存到指定目录。 - 定义另一个函数save_images_to_markdown,该函数将图像列表保存到Markdown文件中。它使用用户提供的相对路径,在Markdown文件中插入图像路径。 - 在__main__部分,替换相应的文件路径,并调用上述两个函数完成PDF到Markdown的转换。 3.使用方法:在__main__部分替换相应的文件路径,之后运行程序。 """ import os # 用于处理文件和目录路径的模块 import fitz # PyMuPDF,用于处理PDF文件 from PIL import Image # Pillow库,用于处理图像 from urllib.parse import quote # 导入urllib库中的parse模块,用于URL编码 def convert_pdf_to_images(pdf_path, image_output_dir): """ 将PDF转换为图像列表。 Parameters: pdf_path (str): PDF文件路径。 image_output_dir (str): 图像输出目录。 Returns: list: 包含所有页面图像的列表。 """ images = [] # 存储所有页面的图像 pdf_document = fitz.open(pdf_path) # 使用PyMuPDF打开PDF文档 # 创建图像输出目录,如果目录不存在则创建 os.makedirs(image_output_dir, exist_ok=True) # 遍历PDF的每一页 for page_number in range(pdf_document.page_count): page = pdf_document[page_number] # 获取页面图像 pixmap = page.get_pixmap() # 修复参数类型错误,将列表改为元组 image = Image.frombytes("RGB", (pixmap.width, pixmap.height), pixmap.samples) images.append(image) # 保存图像到指定目录 image_path = os.path.join(image_output_dir, f"image_{page_number + 1}.png") image.save(image_path) return images def save_images_to_markdown(images, output_md_path, image_relative_path): """ 将图像列表保存到Markdown文件中。 Parameters: images (list): 包含图像的列表。 output_md_path (str): 输出Markdown文件路径。 image_relative_path (str): 用户自定义的图片相对路径,例如 "images". Returns: None """ with open(output_md_path, "w", encoding="utf-8") as md_file: # 遍历图像列表 for index, image in enumerate(images): # 用户自定义的图片相对路径 image_path = os.path.join(image_relative_path, f'image_{index + 1}.png') # 将图片路径插入Markdown文件 md_file.write(f"\n") if __name__ == "__main__": # 替换为你的PDF文件路径 pdf_path = "D:/Python入门的学习笔记/Python入门/补充-实用Python程序设计/pdf课件/1. Python初探.pdf" # 图像输出目录 image_output_dir = "D:/Python入门的学习笔记/Python入门/补充-实用Python程序设计/pdf课件/图片/1. Python初探" # 根据”图像输出目录“自定义的图片相对路径 对应于md文档中”“ image_relative_path = "图片/1. Python初探/" # 使用URL编码将空格替换为"%20" image_relative_path = quote(image_relative_path) # 输出Markdown文件路径 output_md_path = "D:/Python入门的学习笔记/Python入门/补充-实用Python程序设计/pdf课件/1. Python初探.md" # 将PDF转换为图像列表,并保存到指定目录 images = convert_pdf_to_images(pdf_path, image_output_dir) # 将图像列表保存到Markdown文件中,使用用户自定义的图片相对路径 save_images_to_markdown(images, output_md_path, image_relative_path) 五、使用步骤
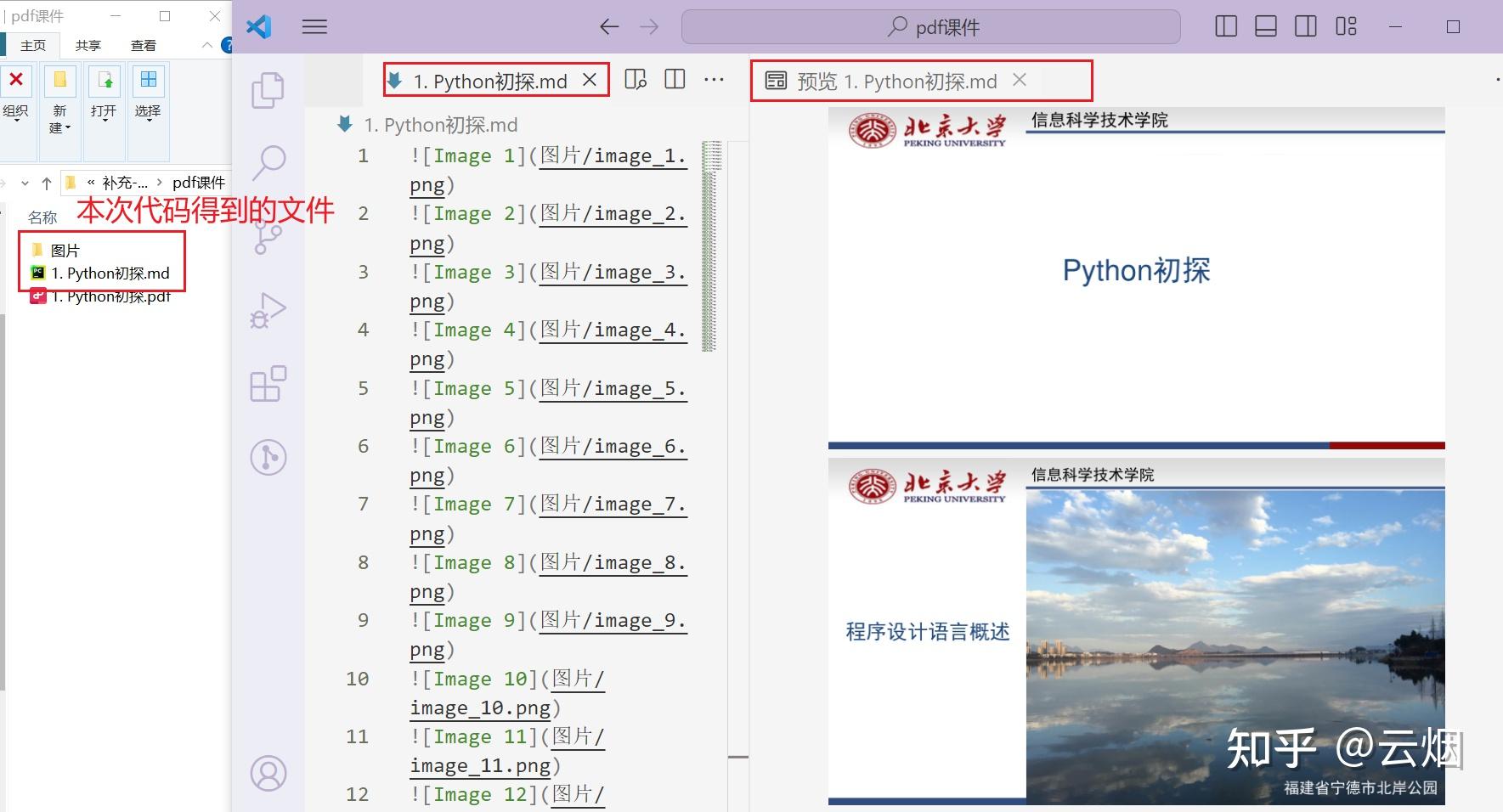
1.如下图所示,首先准备好需要转换的PDF文档,然后在同一个文件目录下创建一个名为"图片"的文件夹。

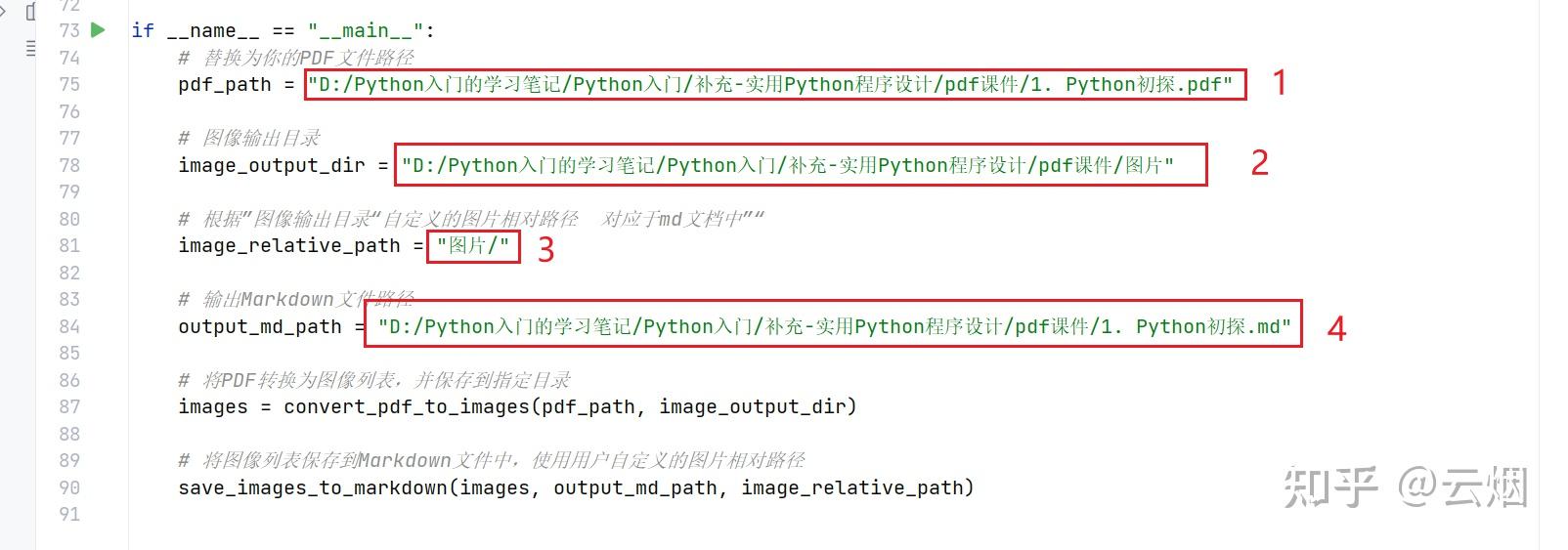
2.将本人提供的代码复制PyCharm中(其他能够运行python程序的地方亦可,如jupyter),然后按照代码注释修改文件路径,如下图所示。
3.之后运行程序,效果如下。

好了,本次笔记记录到此,谢谢大家!
以上就是“基于Python给出的PDF文档转Markdown文档的方法”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
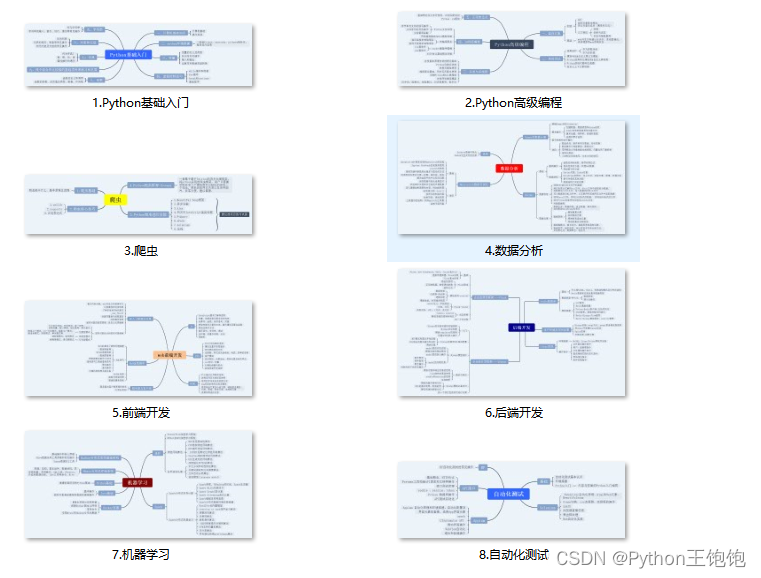
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。