[iOS]内存分区
[iOS]内存分区
文章目录
- [iOS]内存分区
- 五大分区
- 栈区
- 堆区
- 全局区
- 常量区
- 代码区
- 验证
- 内存使用注意事项
- 总结
- 函数栈
- 堆栈溢出
- 栈的作用
- 参考博客
在iOS中,内存主要分为栈区、堆区、全局区、常量区、代码区五大区域
还记得OC是C的超类
所以C的内存分区也是一样的
iOS系统中,应用的虚拟内存默认分配4G大小,但五大区只占3G,还有1G是五大区之外的内核区
上图
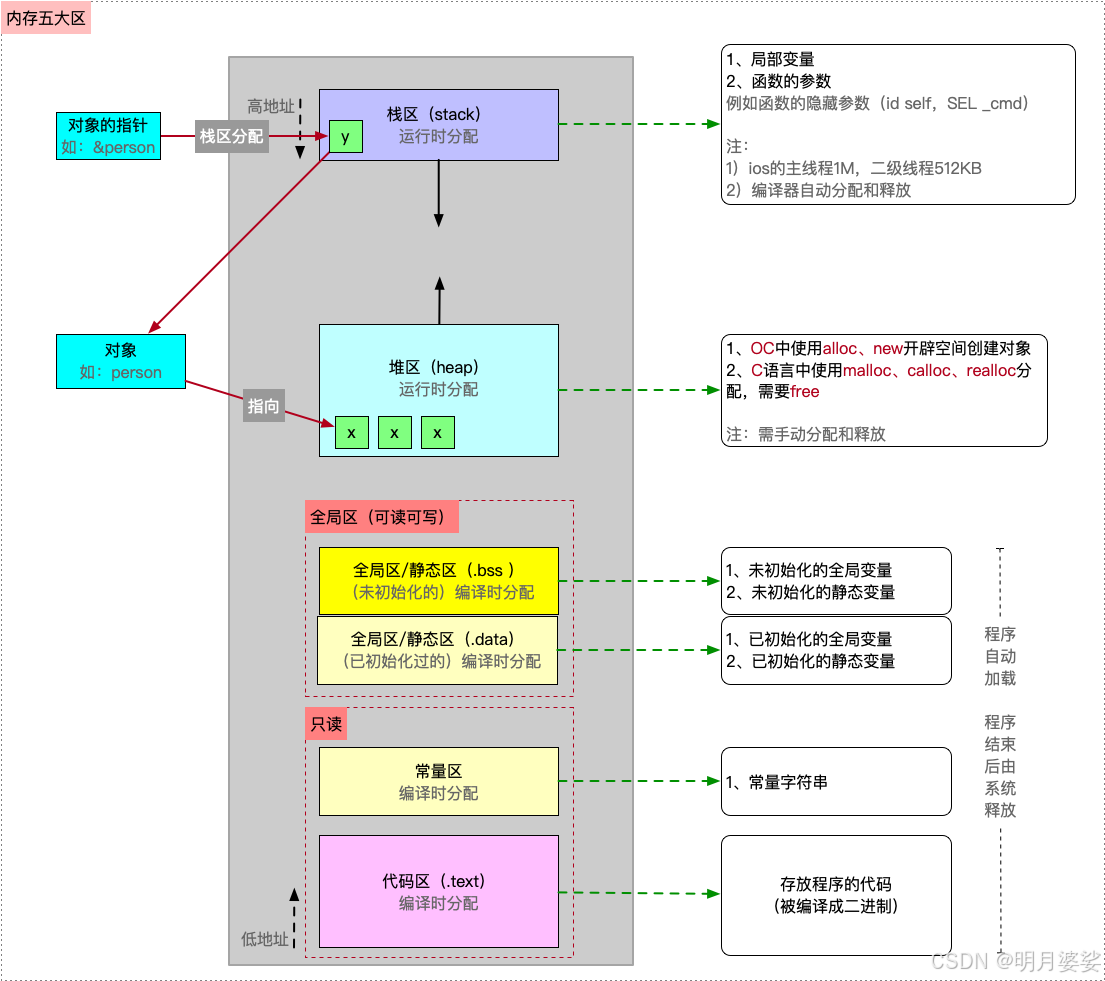
五大分区
栈区
定义
- 栈是系统数据结构,其 对应的进程或者线程是唯一 的
- 栈是 向低地址扩展 的数据结构
- 栈是一块连续的内存区域,遵循 先进后出(FILO) 原则
- 栈的地址空间在iOS中是以 0X7或者0X16开头
- 栈区一般在 运行时分配
存储
栈区是由编译器 自动分配并释放 的,主要用来存储
- 局部变量
- 函数的参数,例如函数的隐藏参数(id self,SEL _cmd)
优缺
优点:因为栈是由编译器自动分配并释放的,不会产生内存碎片,所以快速高效
缺点:栈的内存大小有限制,数据不灵活
- OS X(MAC上)主线程栈大小是8MB
- iOS主线程栈大小是1MB
- 其他线程是512KB

堆区
定义
- 堆是 向高地址扩展 的数据结构
- 堆是 不连续 的内存区域,类似于链表结构(便于增删,不便于查询),遵循先进先出 (FIFO) 原则
- 堆的地址空间在iOS中是以 0x6 开头,其空间的分配总是动态的
- 堆区的分配一般是在 运行时分配
储存
堆区是由程序员动态分配和释放的,如果程序员不释放,程序结束后,可能由操作系统回收,主要用于存放
- OC中使用alloc或者 使用new开辟空间创建对象
- C语言中使用malloc、calloc、realloc分配的空间,需要free释放
优缺
优点:灵活方便,数据适应面广泛
缺点:需手动管理,速度慢、容易产生内存碎片
当需要访问堆中内存时,一般需要先 通过对象读取到栈区的指针地址 ,然后通过 指针地址 访问堆区
全局区
- 全局区是编译时分配的内存空间
- 在iOS中一般以 0x1 开头
- 在程序运行过程中,此内存中的数据一直存在,程序结束后由系统释放,主要存放
- 未初始化的全局变量和静态变量,即BSS区(.bss)
- 已初始化的全局变量和静态变量,即数据区(.data)
BBS:Block Started by Symbol
其中,全局变量是指变量值可以在运行时被动态修改,而静态变量是static修饰的变量,包含静态局部变量和静态全局变量
常量区
常量区(.rodata)是 编译时分配 的内存空间,在程序结束后由系统释放,主要存放
- 已经使用了的,且没有指向的字符串常量
字符串常量因为可能在程序中被多次使用,所以在程序运行之前就会提前分配内存
代码区
代码区是 编译时分配 主要用于存放程序运行时的代码,代码会被编译成 二进制 存进内存的
验证
口说无凭
来看看变量在内存中是如何分配的
- (void)test{ NSInteger i = 123; NSLog(@"i的内存地址:%p", &i); NSString *string = @"CJL"; NSLog(@"string的内存地址:%p", string); NSLog(@"&string的内存地址:%p", &string); NSObject *obj = [[NSObject alloc] init]; NSLog(@"obj的内存地址:%p", obj); NSLog(@"&obj的内存地址:%p", &obj); } 
回顾一下
0x1是内存区开头 用于存放
0x6是堆区开头 主要用于存放OC对象
0x7是栈区开头 主要存放局部变量
i 和 &string 和 &obj都属于局部变量 存在栈区
string内的@"CJL"是字符串 存常量区
对象obj存堆区
很完美
然后这个也是对的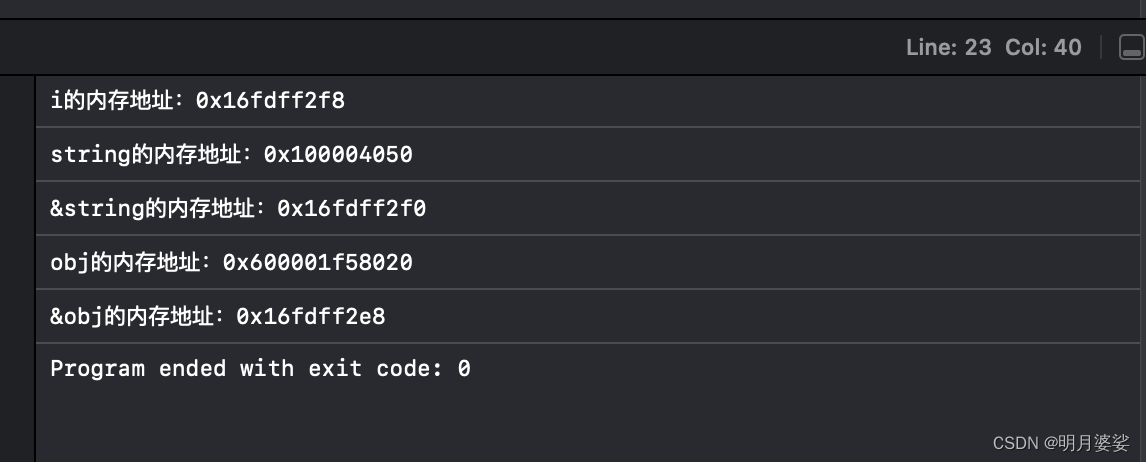
内存使用注意事项
内存使用注意事项涵盖了多个方面,包括避免内存泄漏、防止野指针引用、正确处理数组边界、适当地分配和释放内存等
- 内存泄露
- 重复释放
- 野指针
- 数组越界
- 未初始化内存
- 缓冲区溢出
大小端模式
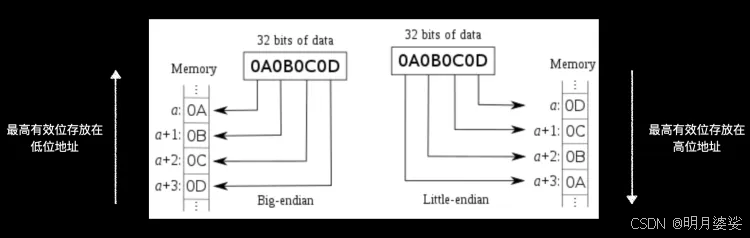
在地址读取时,分为大端模式与小端模式
大端模式从左向右每两位为一组读取
小端模式从右向左每两位为一组读取
iOS与macOS 均是小端模式
总结
一个程序在内存上由BSS段、data段、text段三个组成的。在没有调入内存前,可执行程序分为代码段、数据区和未初始化数据区三部分
BSS段:(Block Started by Symbol)
通常是指用来存放程序中未初始化的全局变量的一块内存区域,属于静态内存分配。BSS段的内容并不存放在磁盘上的程序文件中。原因是内核在程序开始运行前将它们设置为0,需要存放在程序文件中的只有正文段和初始化数据段。text段和data段在编译时已经分配了空间,而BSS段并不占用可执行文件的大小,它是由链接器来获取内存的。
数据段:(data segment)
通常是指用来存放程序中已初始化的全局变量的一块内存区域,属于静态内存分配。总结为:初始化的全局变量和静态变量在已初始化区域,未初始化的全局变量和静态变量在BSS区。
代码段:(code segment/text segment)
通常是指用来存放程序执行代码的一块内存区域。该区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
堆(heap):
用于动态分配内存,位于BSS和栈中间的地址区域,由程序员申请分配和释放。堆是从低地址位向高地址位增长,采用链式存储结构。频繁的malloc/free造成内存空间的不连续,会产生碎片。当申请堆空间时库函数是按照一定的算法搜索可用的足够大的空间,因此堆的效率比栈要低的多。注:与数据结构中的堆不是一个概念,但堆的分配方式类似于链表。
栈(stack):
由编译器自动释放,存放函数的参数值、局部变量等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存放到栈中,这个被调用的函数再为它的自动变量和临时变量在栈上分配空间。每调用一个函数一个新的栈就会被使用。栈区是从高地址位向低地址位增长的,是一块连续的内存区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出。
堆和栈的区别在于
1)管理方式:栈由编译器自动管理,无需人为控制。而堆释放工作由程序员控制,容易产生内存泄漏(memory leak)。
2)空间大小:在32位系统下,堆内存可以达到4G的空间(虚拟内存的大小,有面试官问过),从这个角度来看堆内存大小可以很大。但对于栈来说,一般都是有一定的空间大小的
3)碎片问题:堆频繁new/delete会造成内存空间的不连续,造成大量的碎片,使程序效率降低(重点是如何解决?如内存池、伙伴系统等)。对栈来说不会存在这个问题,因为栈是先进后出,不可能有一个内存块从栈中间弹出。在该块弹出之前,在它上面的(后进的栈内容)已经被弹出。
4)生长方向:堆生长(扩展)方向是向上的,也就是向着内存地址增加的方向;栈生长(扩展)方向是向下的,是向着内存地址减小的方向增长, 可以看第一张图。
5)分配方式:堆都是动态分配的,没有静态分配的堆。而栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,如局部变量分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,无需我们手工实现。
6)效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持(有专门的寄存器存放栈的地址,压栈出栈都有专门的机器指令执行),这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的(可以了解侯捷老师的内存管理的视频,关于malloc/realloc/free函数等)。例如分配一块内存,堆会按照一定的算法,在堆内存中搜索可用的足够大小的空间,如果没有(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。总之,堆的效率比栈要低得多。
函数栈
函数栈又称为栈区
与堆区相对在内存中从高地址往低地址分配
栈帧是指函数(运行中且未完成)占用的一块独立的连续内存区域
应用中新创建的每个线程都有专用的栈空间,栈可以在线程期间自由使用。而线程中有千千万万的函数调用,这些函数共享进程的这个栈空间。每个函数所使用的栈空间是一个栈帧,所有的栈帧就组成了这个线程完整的栈
函数调用是发生在栈上的
- 每个函数的相关信息(例如局部变量、调用记录等)都存储在一个栈帧中
- 每执行一次函数调用就会生成一个与其相关的栈帧
- 然后将其栈帧压入函数栈
- 当函数执行结束则将此函数对应的栈帧出栈并释放掉
上经典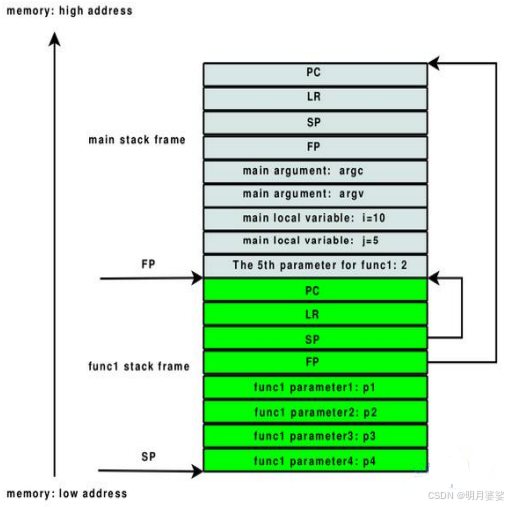
ARM压栈的顺序依次为当前函数指针PC、返回指针LR、栈指针SP、栈基址FP、传入参数个数及指针、本地变量和临时变量。如果函数准备调用另一个函数,跳转之前临时变量区先要保存另一个函数的参数。
其中
main stack frame为调用函数的栈帧
func1 stack frame为当前函数(被调用者)的栈帧
栈底在高地址,栈向下增长
FP就是栈基址,它指向函数的栈帧起始地址
SP则是函数的栈指针,它指向栈顶的位置
ARM也可以用栈基址和栈指针明确标示栈帧的位置,栈指针SP一直移动,ARM的特点是,两个栈空间内的地址(SP+FP)前面,必然有两个代码地址(PC+LR)明确标示着调用函数位置内的某个地址
ok其实还是有不好理解的地方的
R9为什么是the 5th parameter for func1:2 func1
当函数准备调用另一个函数时,在跳转之前,需要先保存另一个函数的参数。如果参数能够通过寄存器(如 R0-R3)传递,就直接使用寄存器;如果参数超过 4 个,多出来的参数则使用栈来传递,并将它们放置在当前函数栈帧的临时变量区。
所以在main函数栈帧的R9存放的是func1的第五个参数就没问题啦
注:ARM是满降栈
满栈:当堆栈指针总是指向最后压入堆栈的数据
空栈:当堆栈指针总是指向下一个将要放入数据的空位置
升栈:随着数据的入栈,SP指针从低地址->高地址移动
降栈:随着数据的入栈,SP指针从高地址->低地址移动
堆栈溢出
一般情况下应用程序是不需要考虑堆和栈的大小的,但是事实上堆和栈都不是无上限的,过多的递归会导致栈溢出,过多的alloc变量会导致堆溢出。
所以预防堆栈溢出的方法:
(1)避免层次过深的递归调用
(2)不要使用过多的局部变量,控制局部变量的大小
(3)避免分配占用空间太大的对象,并及时释放
(4)适当的情景下调用系统API修改线程的堆栈大小
栈的作用
(1)保存局部变量
(2)参数传递
(3)保存寄存器的值
参考博客
iOS-底层原理 24:内存五大区
ARM——栈