Hadoop3:HDFS-存储优化之纠删码
一、集群环境
集群一共5个节点,102/103/104/105/106
二、纠删码原理
1、简介
HDFS默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余开销。Hadoop3.x引入了纠删码,采用计算的方式,可以节省约50%左右的存储空间。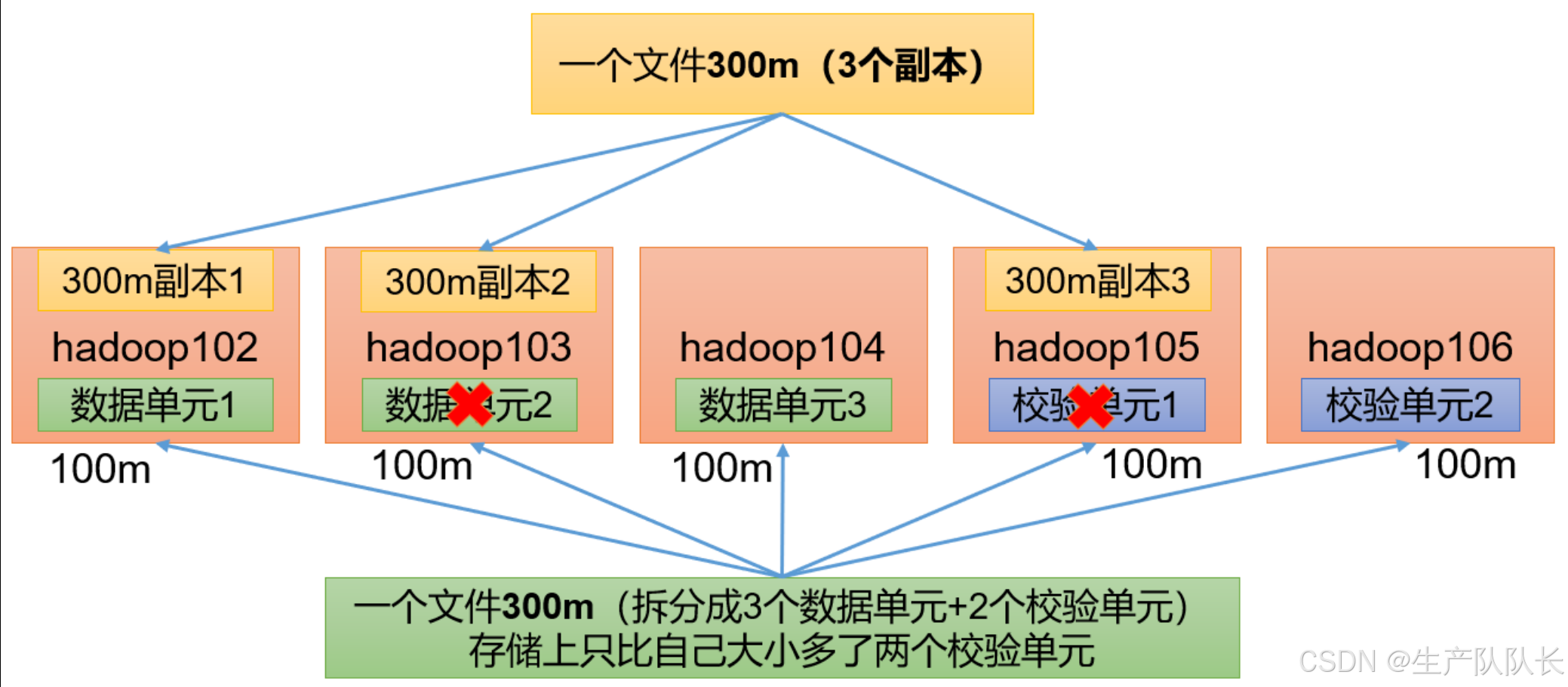
简单来说,通过计算方式,来还原丢失的数据。
损耗的是CPU性能,节省了磁盘空间。
2、纠删策略
[atguigu@hadoop102 ~]$ hdfs ec -listPolicies Erasure Coding Policies: ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED 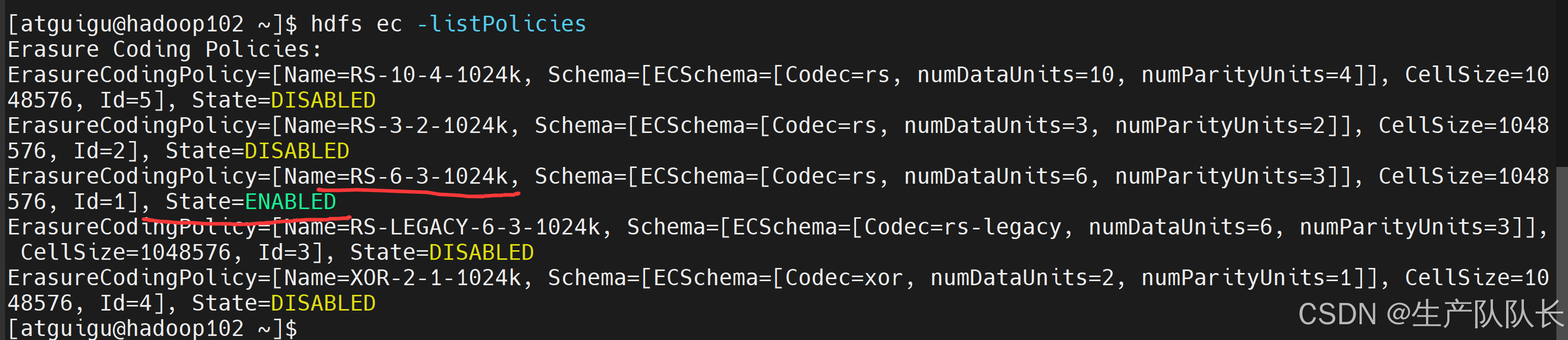
RS-3-2-1024k
使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,每个单元的大小是1024k=1m
只要有任意的3个单元存在,就可以还原数据。
RS-6-3-1024k
类似RS-3-2-1024k,6个数据单元,3个校验单元
RS-10-4-1024k
类似RS-3-2-1024k,10个数据单元,4个校验单元
RS-LEGACY-6-3-1024k
类似RS-3-2-1024k,只是编码的算法用的是rs-legacy
XOR-2-1-1024k
类似RS-3-2-1024k,使用XOR编码(速度比RS编码快)
纠删码策略是给具体一个路径设置。所有往此路径下存储的文件,都会执行此策略。默认只开启对RS-6-3-1024k策略的支持,如要使用别的策略需要提前启用。
也就是,对某个路径下的文件使用纠删码方式确保数据的可靠性。
其他路径依然采用自己的方式保证可靠性。
三、案例
1、需求
将/input目录设置为RS-3-2-1024k策略
我们集群是5台虚拟机
所以,我们需要更改纠删码策略为RS-6-3-1024k。
因为默认的是RS-6-3-1024k策略,需要9台机器。
2、相关指令
启用RS-3-2-1024k策略 hdfs ec -enablePolicy -policy RS-3-2-1024k 创建路径 hdfs dfs -mkdir /input 设置路径的纠删码策略为RS-3-2-1024k hdfs ec -setPolicy -path /input -policy RS-3-2-1024k 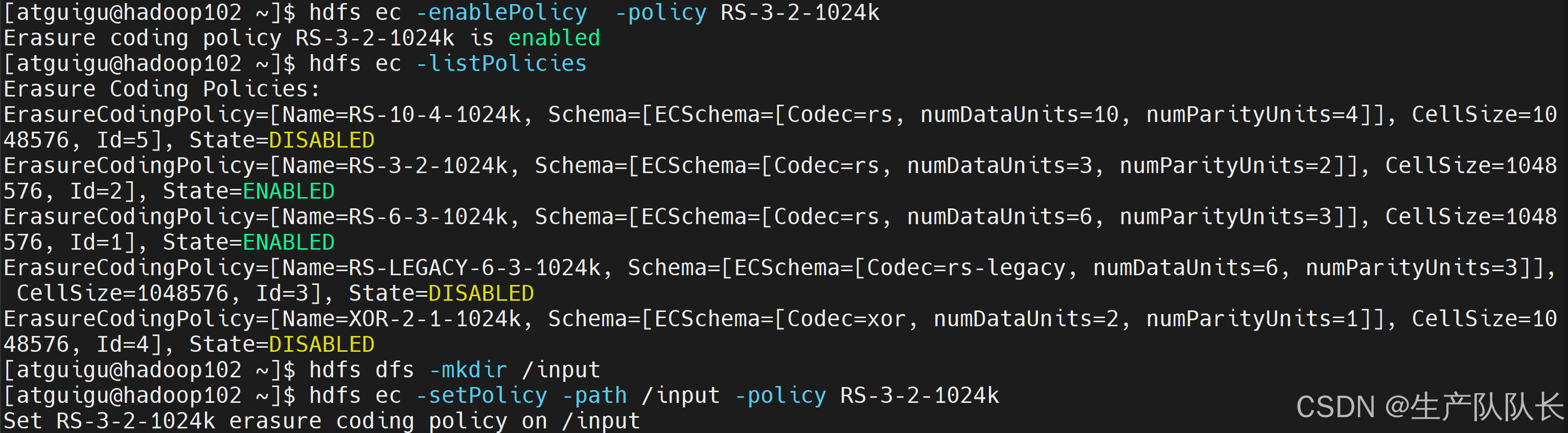
3、测试
上传文件
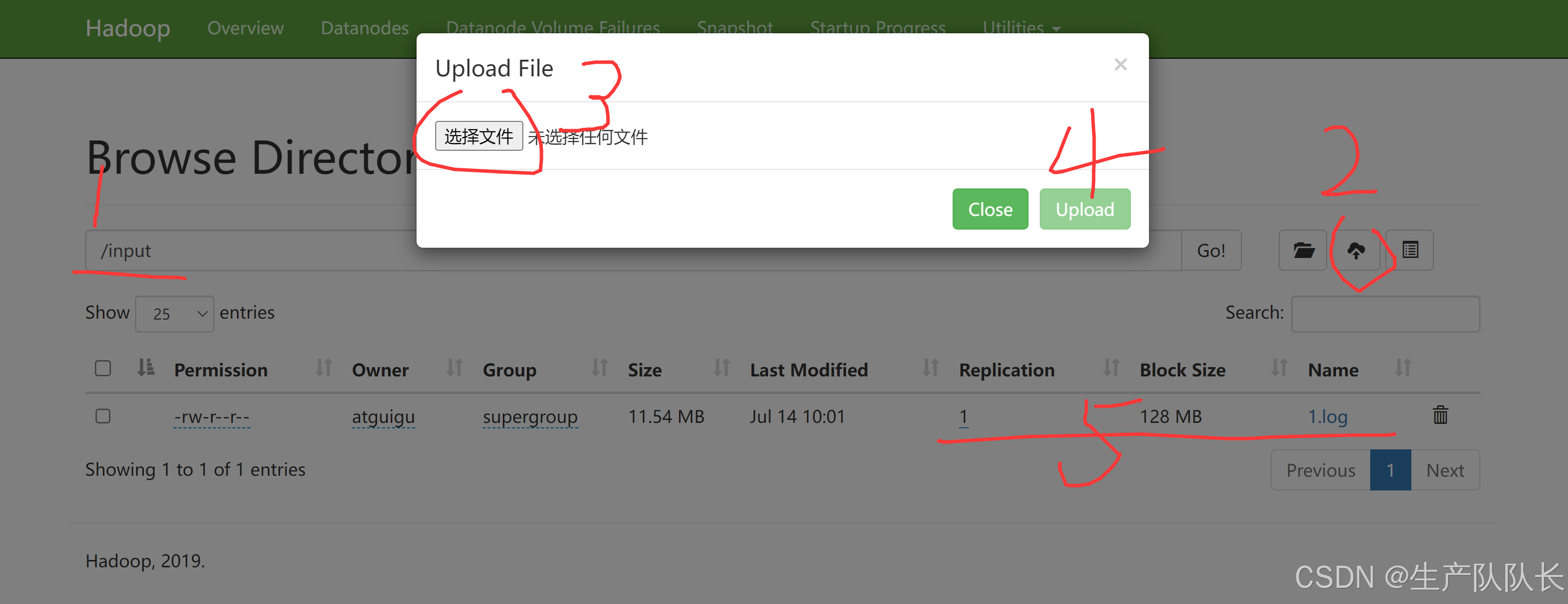
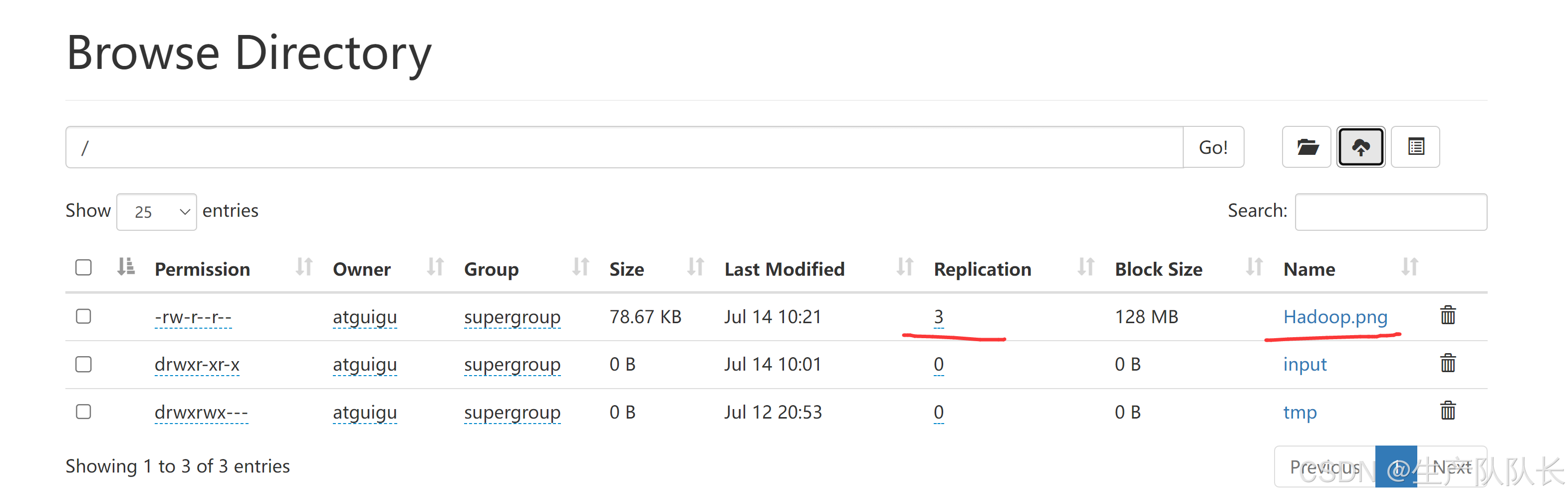
1个副本,分别存放在5台机器上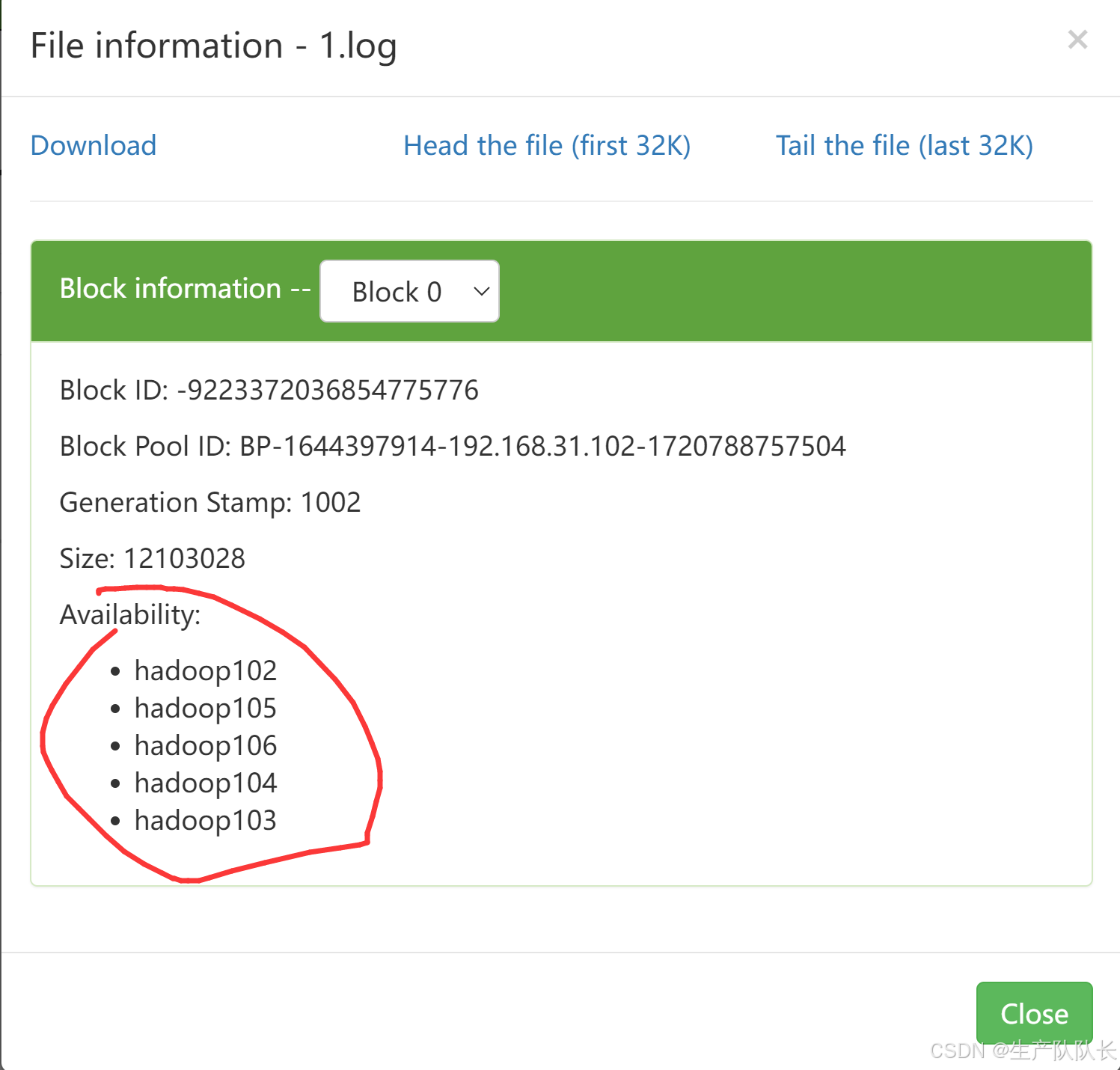
查看数据
102,能查看文件内容,说明是数据单元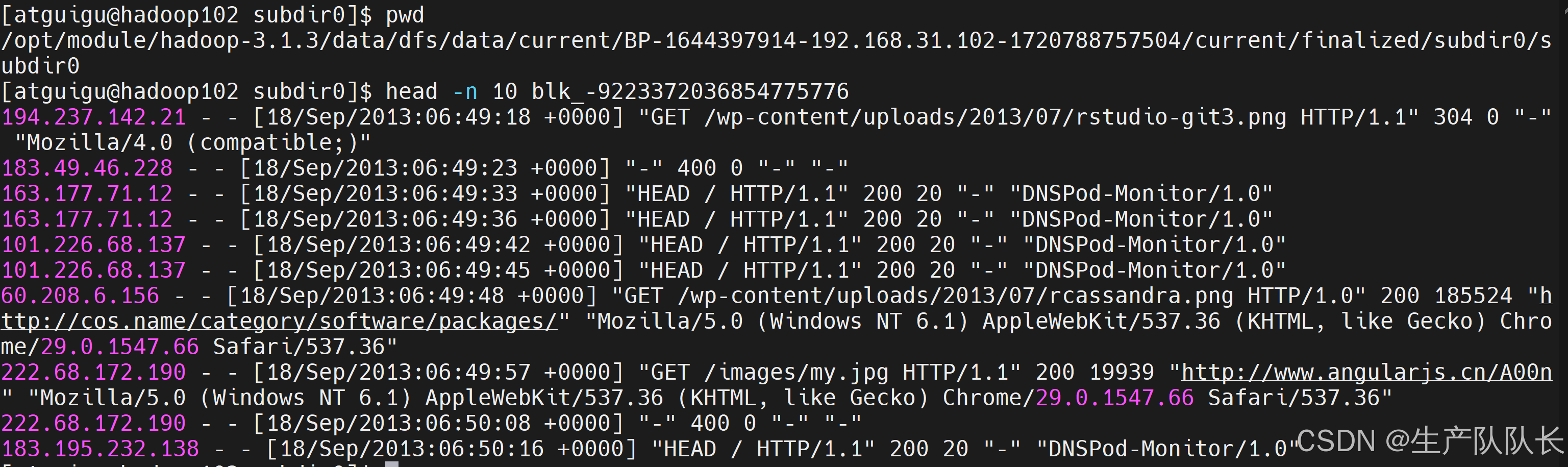
103,无法查看内容,说明是校验单元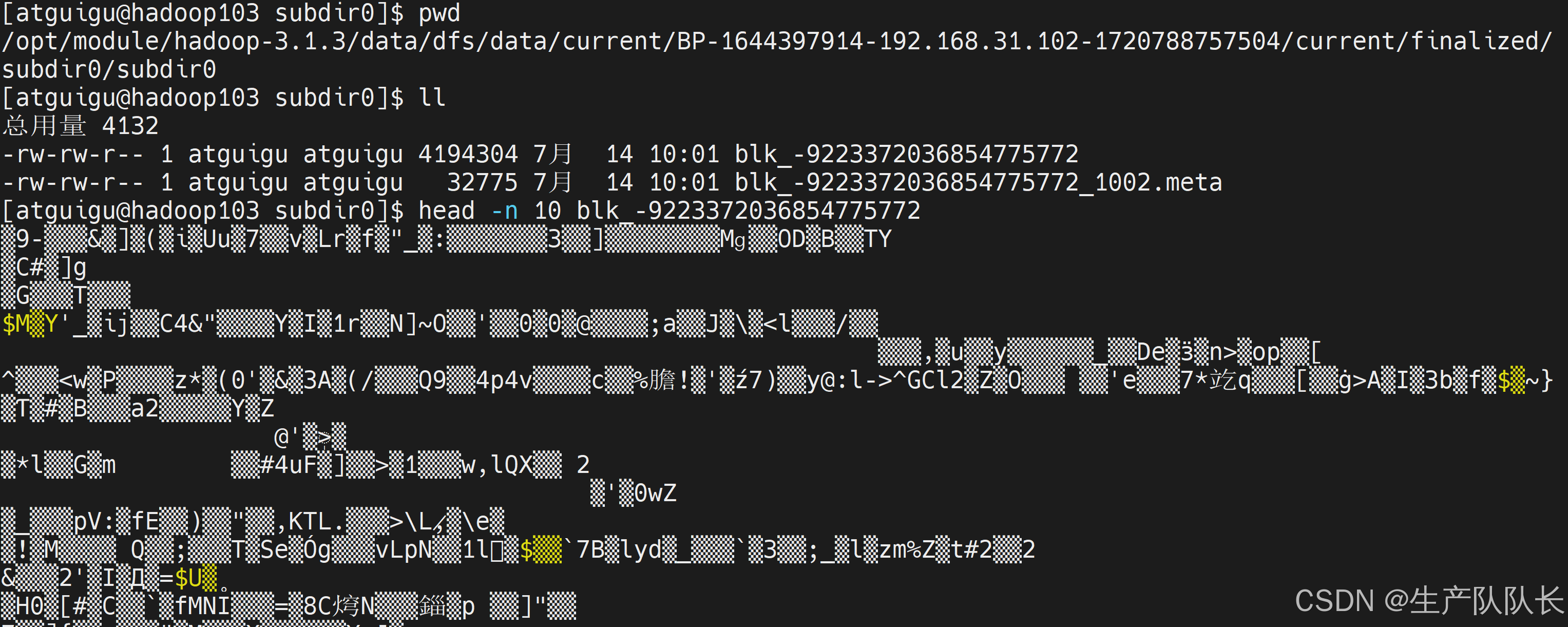
104,无法查看内容,说明是校验单元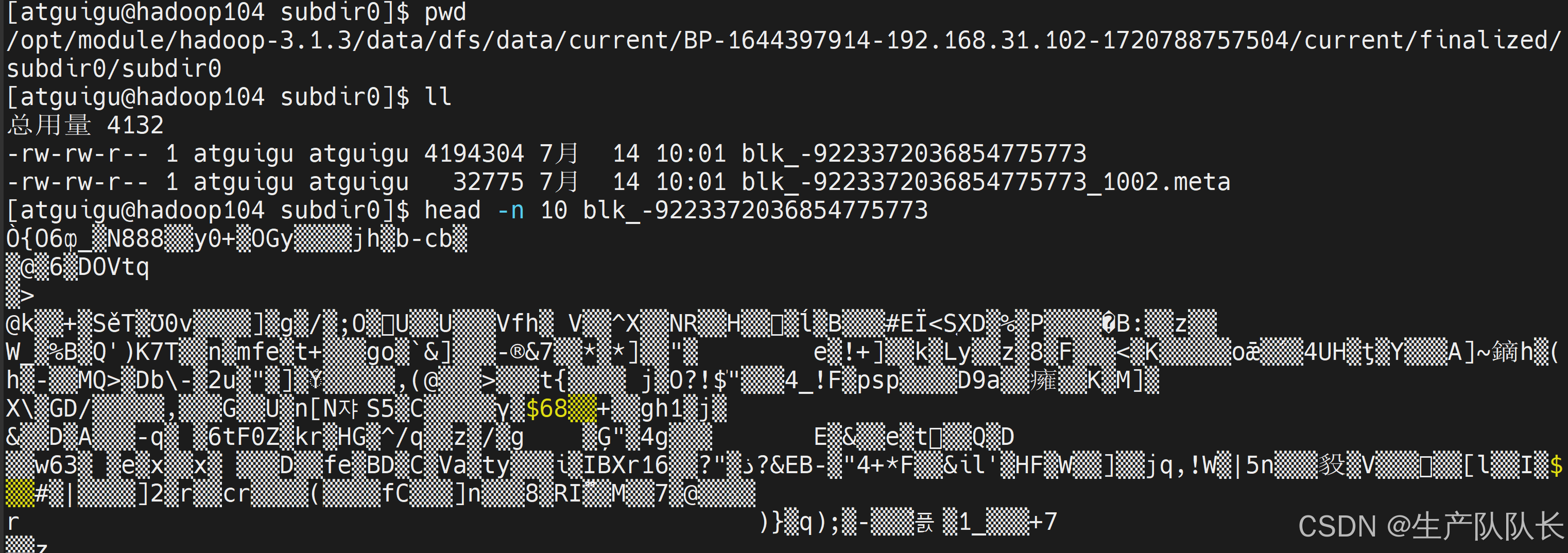
105,能查看文件内容,说明是数据单元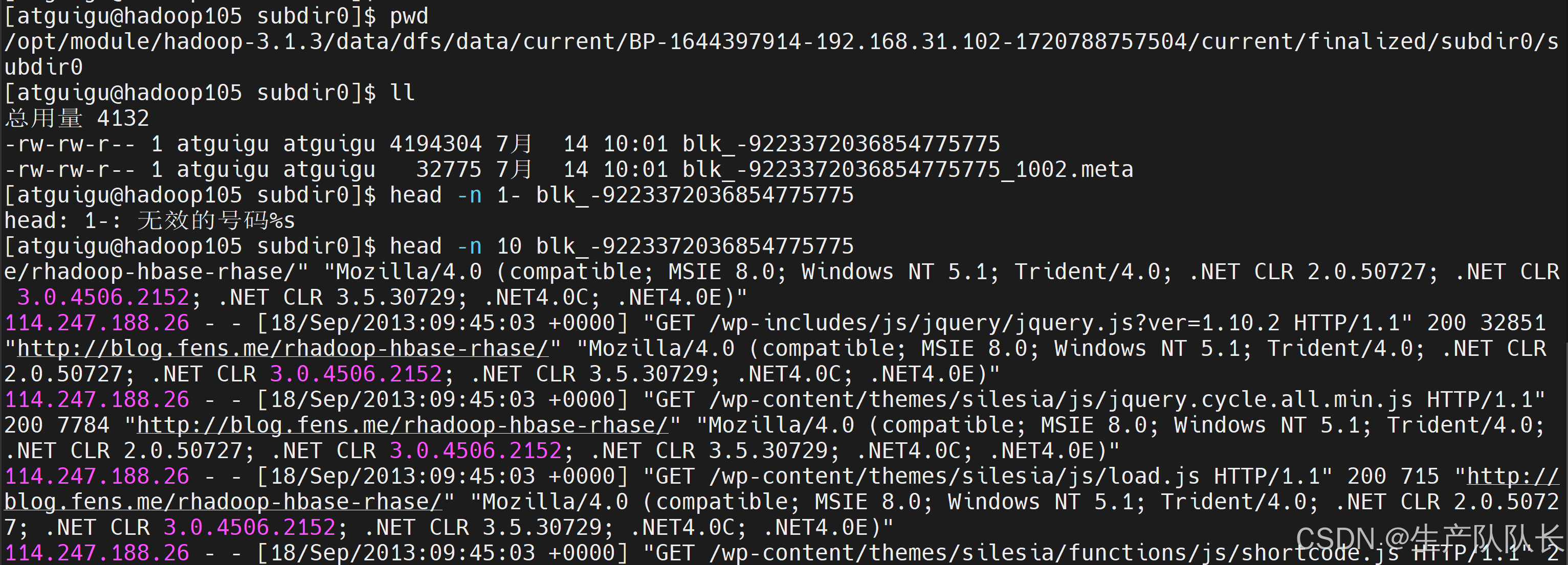
106,能查看文件内容,说明是数据单元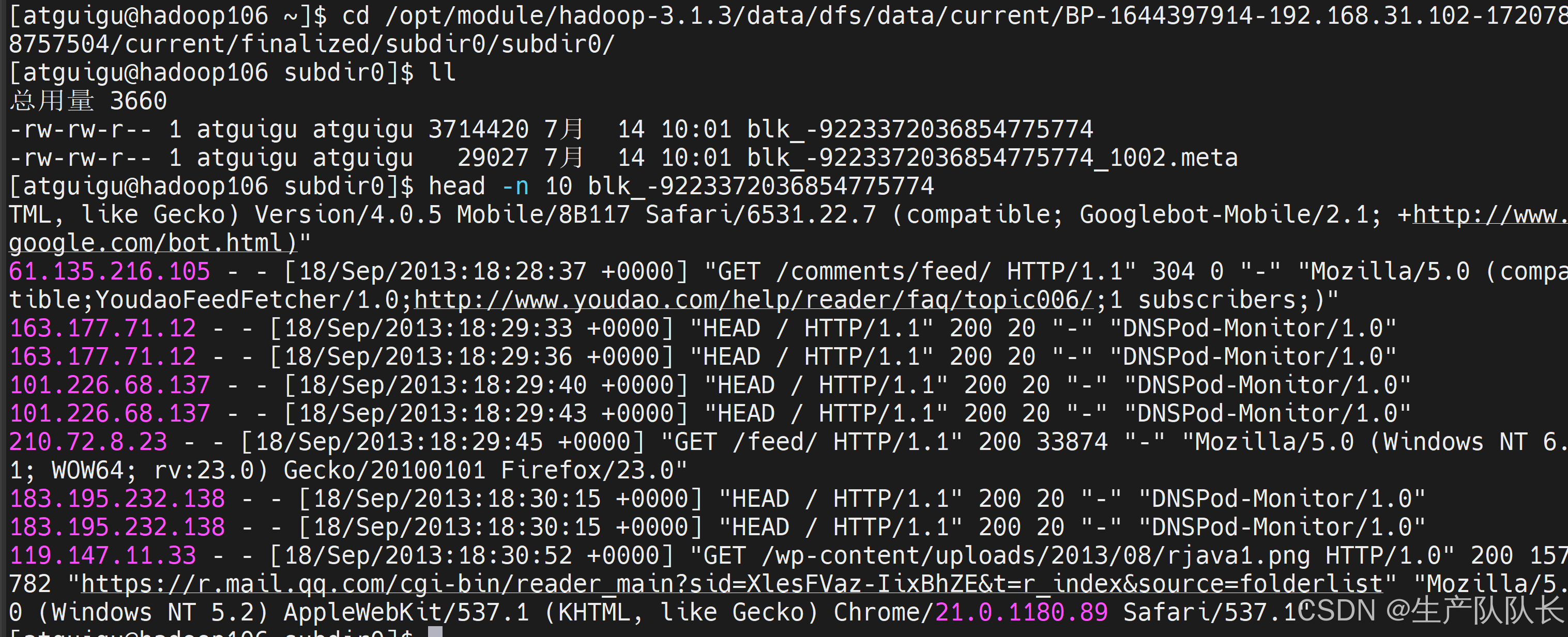
删除数据并验证是否可以下载
最多删除2台机器上的数据
我这里删除102/103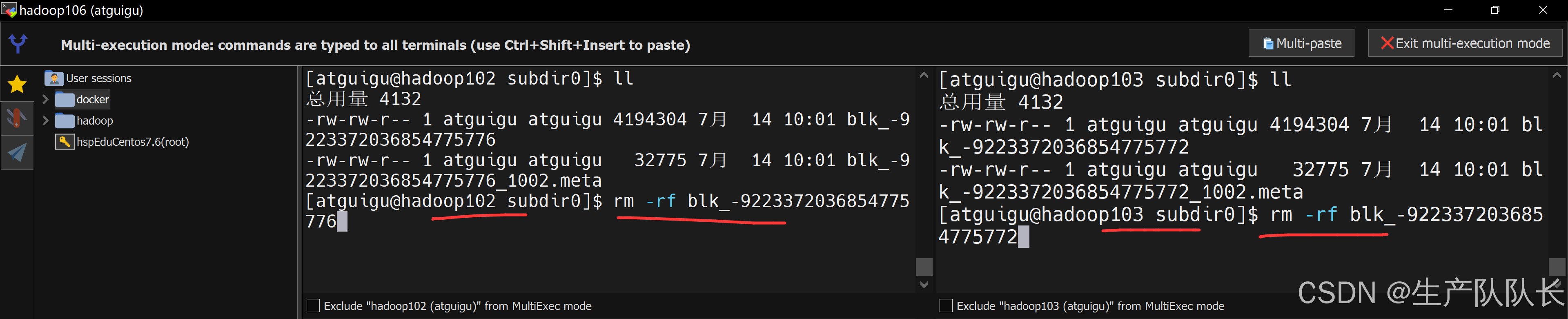

下载测试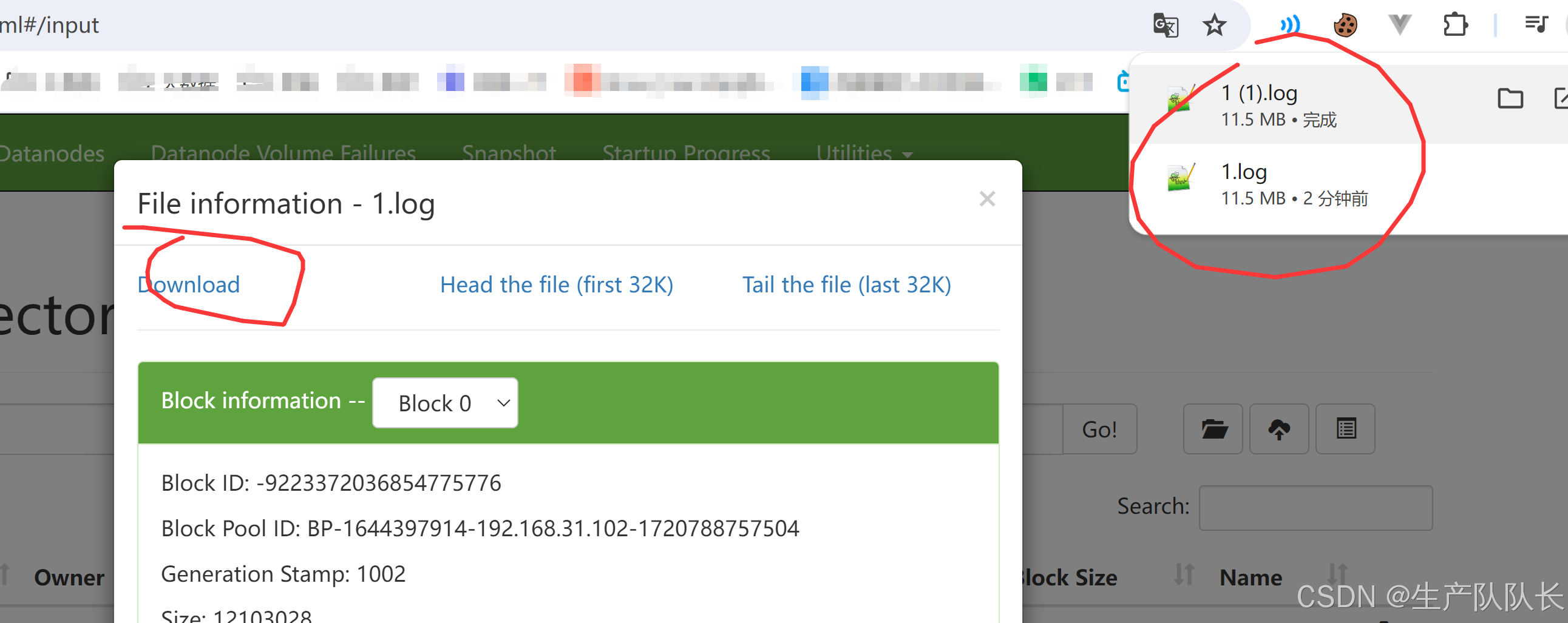
可以看出,103机器,是没有数据的
如果,删除3台机器的数据,那么就会下载失败
这里就不做验证了。
其他路径上传文件
发现副本数依然是3份