sklearn之神经网络学习算法
文章目录
- 什么是神经网络
- 人工神经网络的结构
- 输入层
- 输出层
- 隐含层
- 神经元的链接
近几年深度学习还是比较火的,尤其是在大语言模型之后,在本质上深度学习网络就是层数比较多的神经网络。sklearn并不支持深度学习,但是支持多层感知机(浅层神经网络)
首先我们需要了解一下神经网络的相关概念,再学习如何使用sklearn构造简单的神经网络算法
什么是神经网络
学术上来讲:人工神经网络是一种由具有自适应的简单单元构成的并行互联的网络,它的组织结构能够模拟生物神经系统对真实世界所做出的交互反应
我们知道,大脑通过突触传递信息来增强或者弱化反应,以达到学习的目的,当这样的链接足够多时,就会形成一个复杂的网络,用计算机的术语也称之为分布式特征网络(没有核心处理机制的网络)
人工神经网络的强大之处在于他的学习能力非常强,在得到训练集之后,他能通过学习提取所观察事物的各个特征,将特征之间使用不同的网络节点(突触)链接,通过训练链接的网络权重(突触的强与弱),直到顶层输出得到正确的答案
这里我们不再赘述生物神经之间传递信息的方式,根据赫布假说,在我们学习的前后,只是突触的强度发生了变化,这也是神将网络学习的生物学基础,才有了人工神经网络
我们知道,人工神经网络性能的好坏,高度依赖于神经系统的复杂程度,通过调整链接的权重,达到处理信息的目的,从而“涌现”出处理信息的能力,自学习和自适应能力,即便到了现在的深度学习网络,其本质仍然与之前相同,都是调整权重
人工神经网络的结构
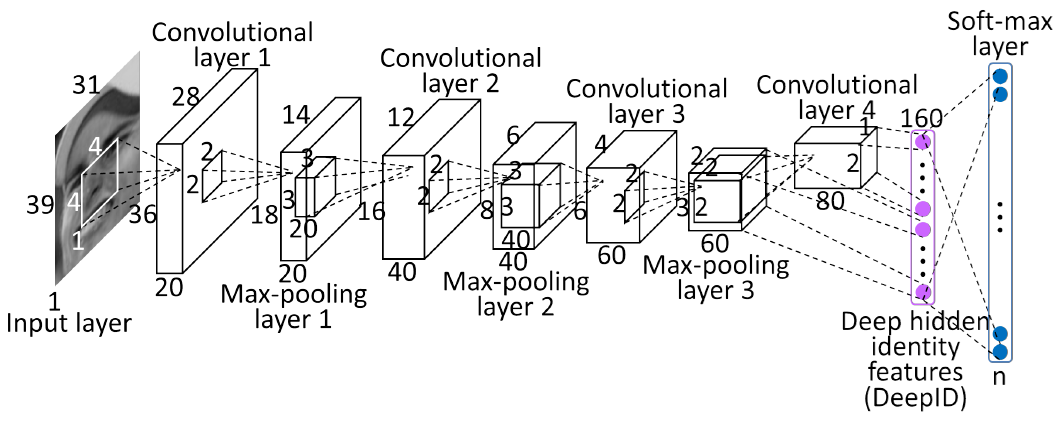
这里有一个卷积神经网络的架构,先不必慌张,我们只关注输入的部分
输入层
这里的输入层是一张照片,计算机能够读取到照片的内容本质上也只是一堆数据,色彩可以用RGB等数值来表示,然后再压缩成灰度,照片的每一个像素就可以存一个灰度,这样一张照片就可以变成一个对应像素点的矩阵(向量)
假设图片的大小是16*16像素,那么输入层的神经元就是256,换句话说,输入层就是一个包括256个灰度值的向量,一个神经元接收一个归一化的灰度值,我们可以使用0和1来表示纯白和纯黑,而灰度值则介于0和1之间
输出层
对于输出层而言,神经元的个数和输入神经元个数并没有对应关系,而是和最终的事物分类有关,而最终的结果,也只是最终事物的概率,当其中某一项的概率远远高于其他时,神经网络就会判定
隐含层
除了输入层和输出层,隐含层的设计是一门艺术,也是一门体力活,需要不断的试错
我们可以暂时把隐含层定位一个黑箱,他主要负责输入与输出之间的非线性映射变化,他具体的原理,就跟“涌现”现象一样,很难解释清楚,我们能做的就是不断调试隐含层的层数、每层的神经元个数
神经元的链接
我们把神经元之间的影响程度称之为权重,权重的大小表示链接的强弱,他就相当于这一层神经元告诉下一层神经元应该更加关注哪些部分
神经元内还有一个施加于自身的特殊权值,称之为偏置(bias),简单说就是表示了神经元是否更容易被激活,说人话就是表示这个神经元对特定数据的敏感度
设计整个人工神经网络的结构的目的就是为了让神经网络的性能达到最佳,找到合适的权值,让损失函数最小