2024年计算机三级|数据库习题整理(自用①)
所有题目均来自【三级数据库技术基础题库】,博客仅为依托考点的大致整理,用于自主的回顾学习,仅供参考。
第1章 数据库应用系统开发方法
数据库应用系统的生命周期主要由项目规划、需求分析、系统设计、实现与部署、运行和维护五个基本活动组成。


第2章 需求分析
DBAS需求分析阶段的性能分析是分析DBAS应具有的性能指标,主要包括:
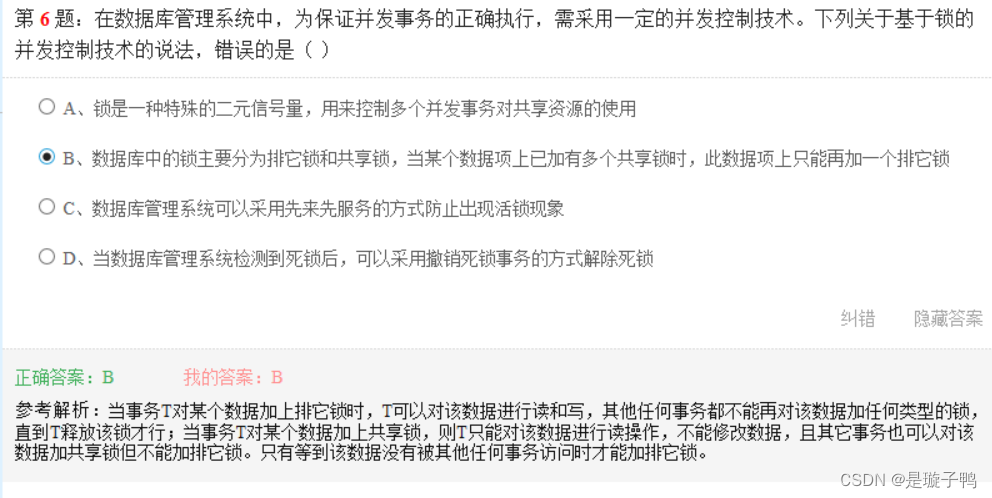
- 数据操作响应时间
- 系统吞吐量,即系统在单位时间内可以完成的数据库事务或查询的数量
- 允许并发访问最大用户数
- 每TPS(Price per TPS)的价值

组成IDEF0图的基本元素是矩形框和箭头,矩形框下边的箭头代表对应活动的机制,即实施活动的物理手段或所需要的资源(计算机系统、人或组织)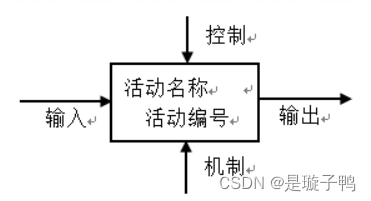
DFD(数据流图,Data Flow Diagram)是便于用户理解系统数据流程的图形表示。该建模方法的核心是数据流,具有抽象性和概括性的特性。
数据库用箭头表示
处理用矩形框表示
数据存储用圆角矩形框表示
外部项用圆角框或者平行四边形框表示
父图中描述过的数据流必须在对应的子图中出现,否则会出现父图与子图的不平衡(类似于全国地图与分省地图的关系)
第3章 数据库结构设计
| 数据模型要素 | 内容 |
|---|---|
| ①数据结构 | 所研究的对象类型的集合。从语法角度表述了客观世界中数据对象本身的结果和数据对象之间的关联关系,是对系统静态特征的描述 |
| ②数据操作 | 主要指检索和更新(插入、删除、修改)两类操作 |
| ③数据完整性约束 | 规定数据库状态及状态变化所应满足的条件 |
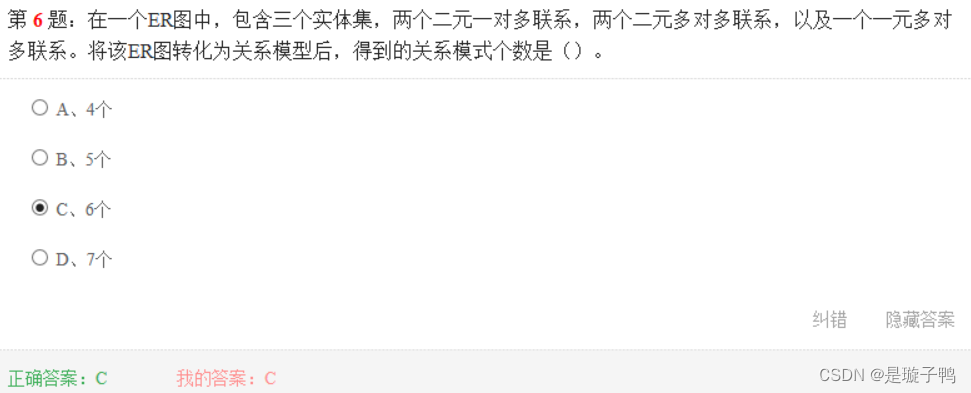
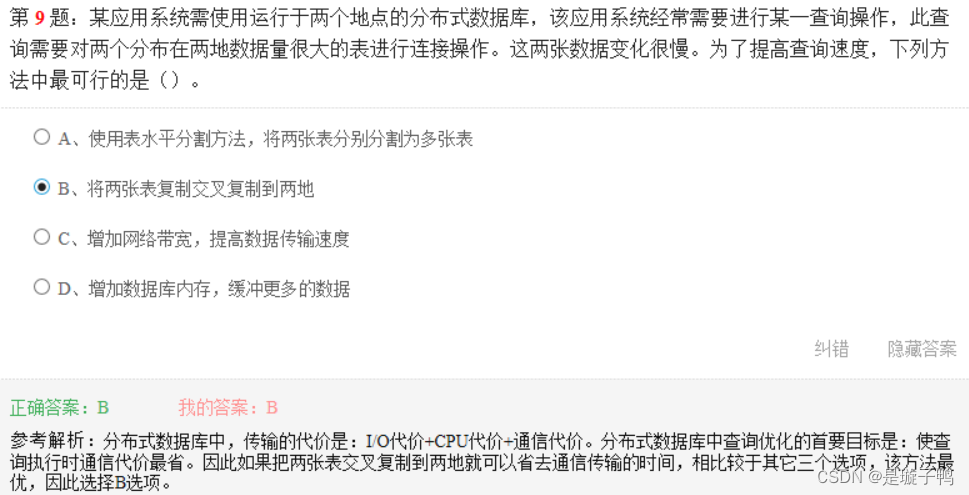
题目中有3个实体集,则可得3个关系模式;三个多对多联系(两个二元多对多联系,以及一个一元多对多联系)则可以转换成3个关系模式,一共可以得到6个关系模式。
在ER图中,将实体和联系转换成关系模式的规则是:
- 每一个实体集转换为一个关系模式
- 一对一、一对多联系中一端并入多端的实体关系模式中
- 每一个多对多联系转换成一个关系模式

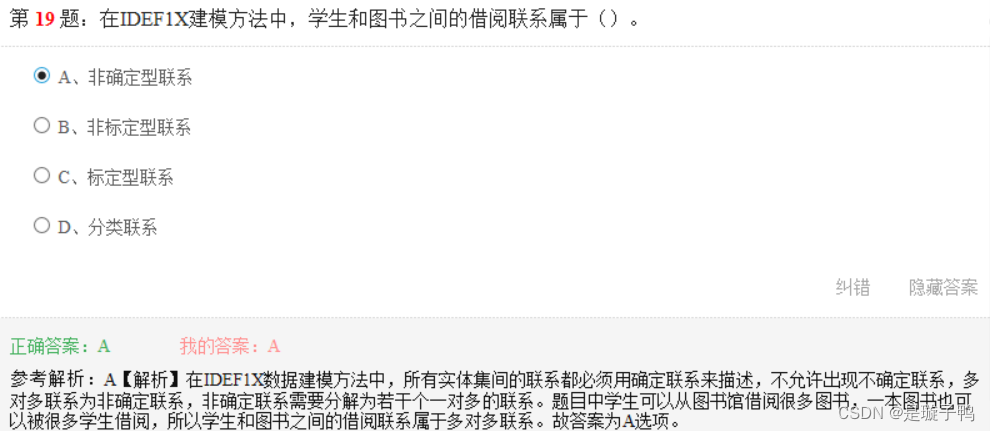
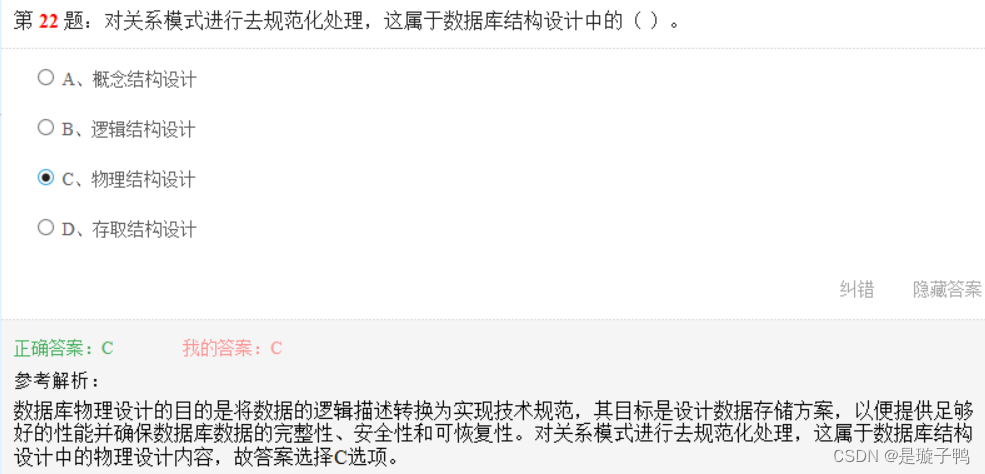
对关系模式进行去规范化处理,这属于数据库结果设计中的物理设计内容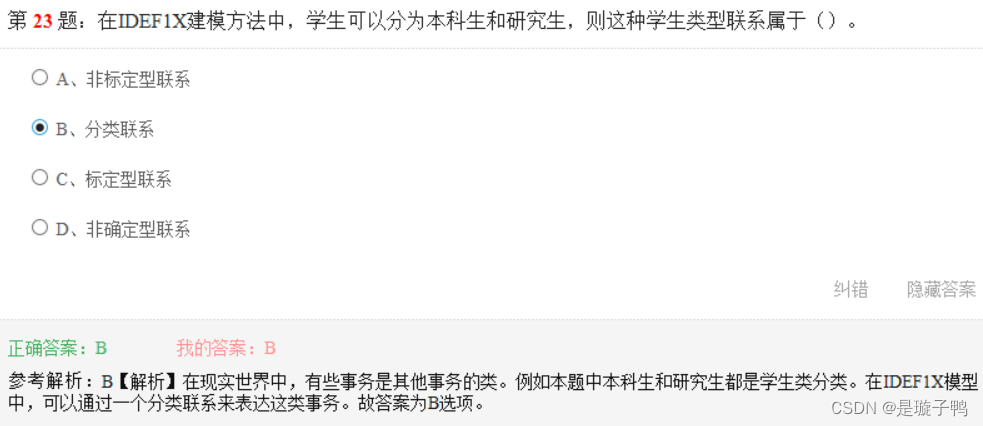
第4章 数据库应用系统功能设计与实施

系统在执行检查点操作时,所有的事务处理被暂时终止,长时间的事务影响检查点的效果
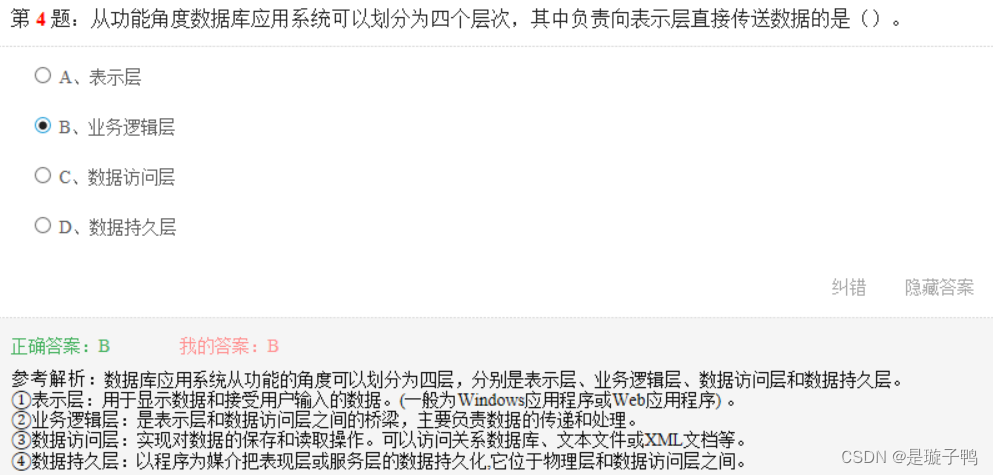
用户使用create procedure命令所定义的存储过程位于数据访问层
数据访问层负责与DBMS系统进行交互,提取或存入应用系统所需的数据
从功能角度将数据库应用系统划分为四个层次,各个层次对应的任务为:
- 表示层概要设计的主要任务是进行人机界面设计(eg: 设计Web界面);
- 业务逻辑概要设计的主要任务是梳理DBAS的各项业务活动,将其表示为各种系统架构(eg: 类、模块、组件等);
- 数据访问层概要设计的主要任务是针对DBAS的数据处理需求设计用于操作数据库的各类事务;
- 数据持久层概要设计的主要任务是进行应用系统的存储结构设计(eg: 数据的完整性维护工作)。
根据事务—基本表交叉引用矩阵来调整数据文件的组织结构,涉及到应用系统数据的变化,这一任务属于数据持久层
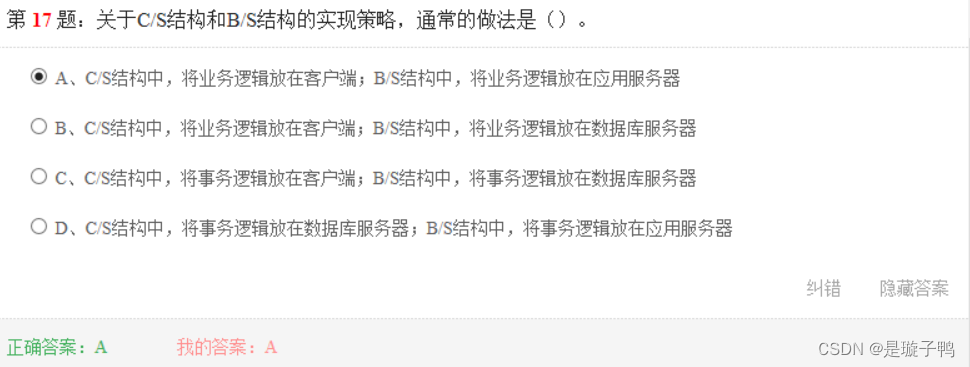
C/S结构是客户机/服务器结构,业务逻辑在客户端,事务逻辑在数据库服务器;三层B/S结构是浏览器/服务器结构,业务逻辑在应用服务器,事务逻辑在数据库服务器。
第5章 UML与数据库应用系统
在UML类图中,常见的有以下几种关系:
①泛化:带三角箭头的实线,箭头指向父类;
②实现:带三角箭头的虚线,箭头指向接口;
③关联:带普通箭头的实心线,指向被拥有者;
④聚合:带空心菱形的实心线,菱形指向整体。描述部分与整体的关系,且部分可以离开整体而单独存在;
⑤组合:带实心菱形的实线,菱形指向整体;
⑥依赖:带箭头的虚线,指向被使用者
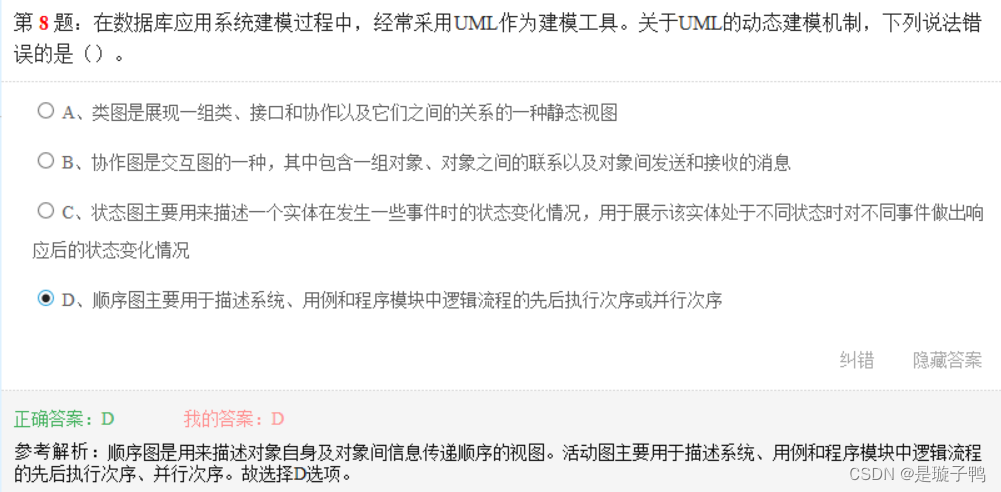
状态图在状态发生转移时需要在转移的关系上标示该事件。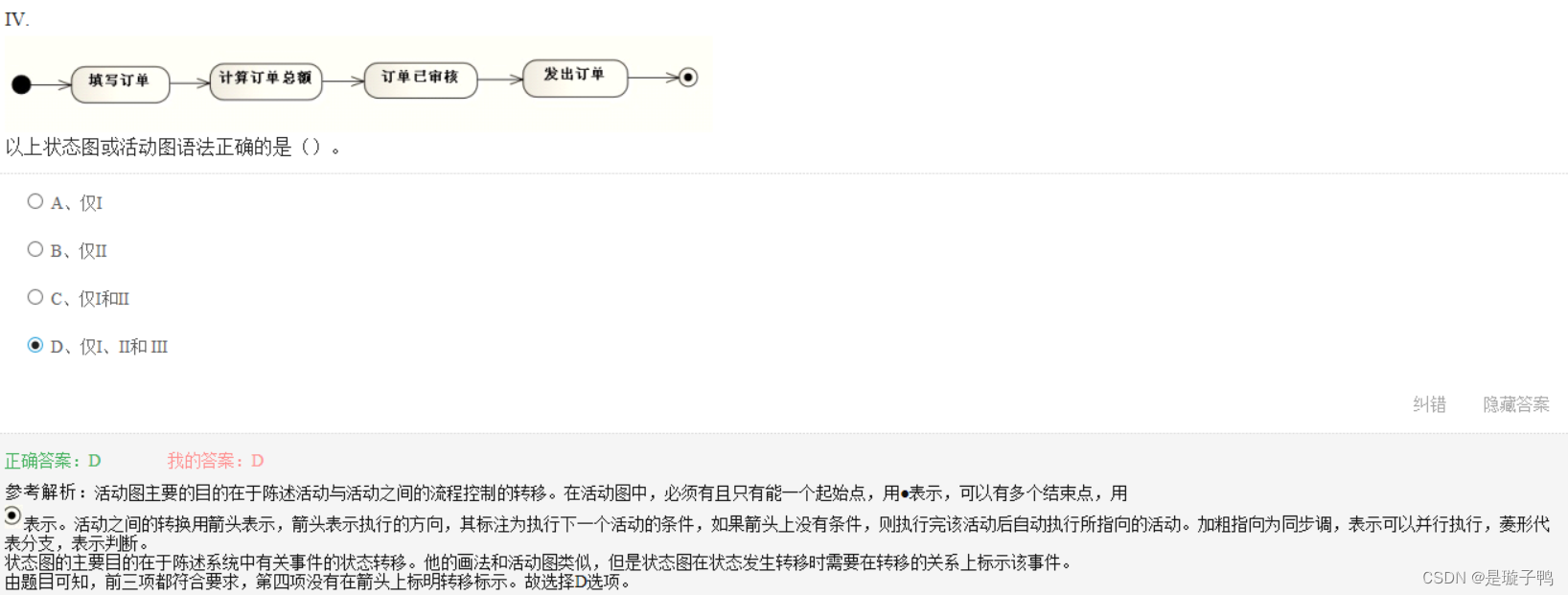
一个角色可执行多个用例,一个用例也可以被多个角色使用;
用例模型描述的是外部执行者(Actor)所理解的系统功能,它是从系统外部看系统功能,并不描述系统内部对功能的具体实现。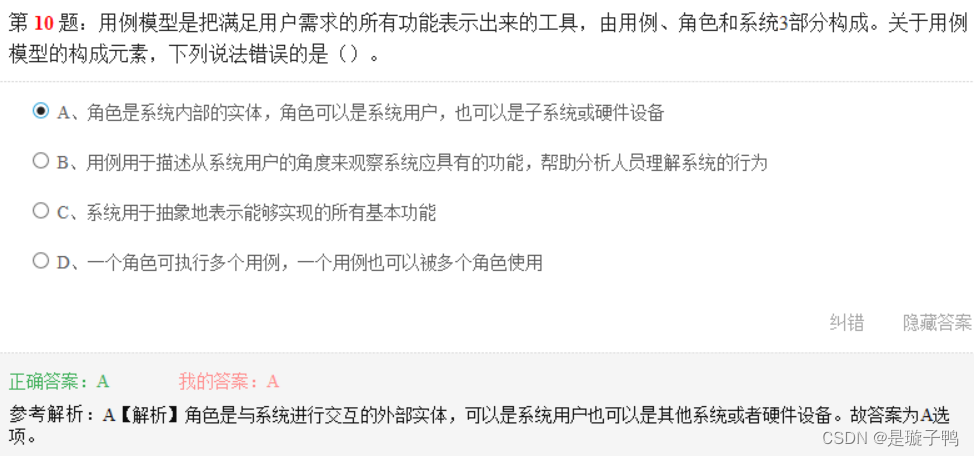
用例模型由用例、角色和系统三部分组成。且用例用椭圆形表示,位于系统边界的内部;
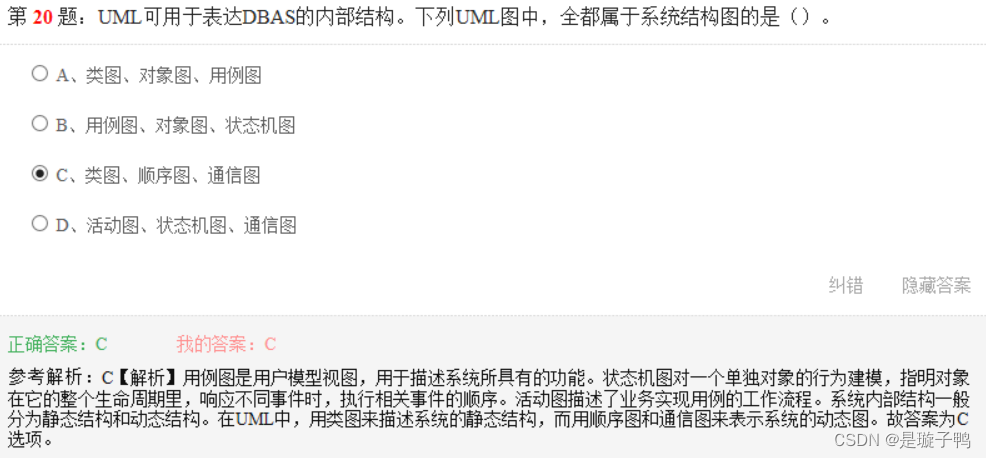
系统内部结构一般分为静态结构和动态结构。在UML中,用类图来描述系统的静态结构,用顺序图和通信图来表示系统的动态图。
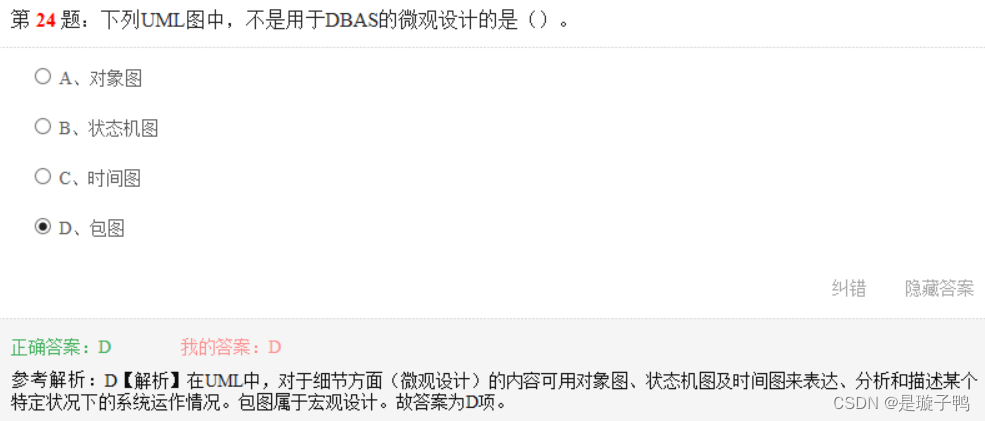
包图属于宏观设计
第6章 高级数据查询

考点:函数的用法


包含INTO子句的SELECT语句的语法格式为:SELECT 查询列表序列 INTO <新表名> FROM 数据源
第7章 数据库及数据库对象

对于复合索引,在查询使用时,最好将WHERE条件顺序作为索引列的顺序,这样效率最高。
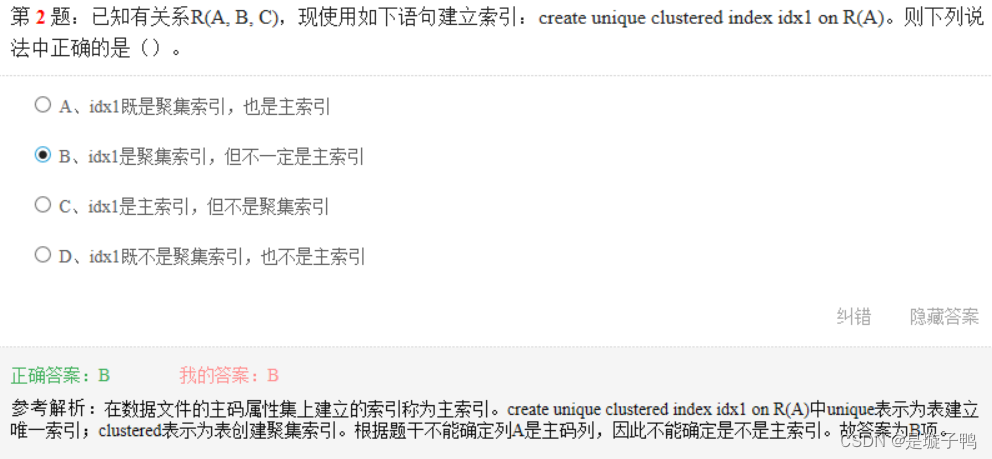

一个用户只能对应一个架构,但多个用户可以共享一个架构。
日志文件的存放位置没有限制,另外日志文件可以设置自动增长,对日志文件的大小没有限制。
一个表上只能有一个聚集索引。
系统默认查询结果按升序排列,因此只需要对需要降序的列使用关键字DESC即可。
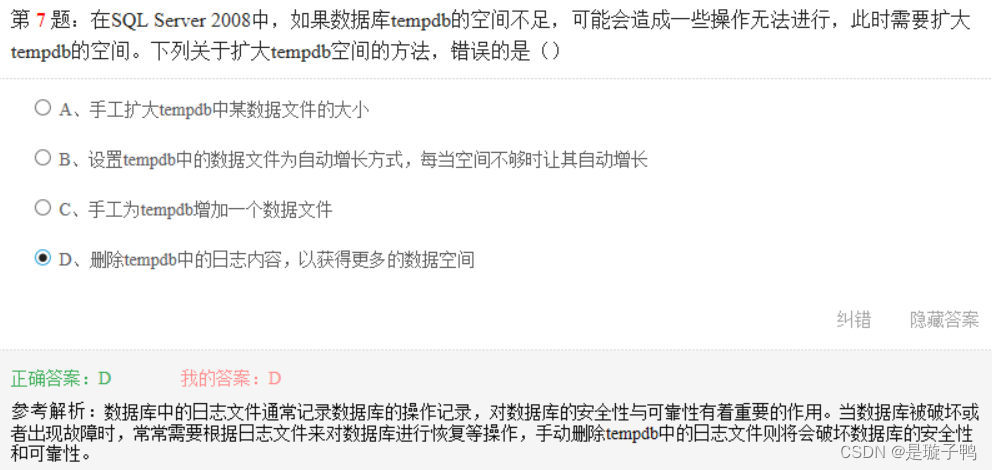
每个数据库有且仅有一个主要数据文件。
如果次要数据文件没有分配给其它文件组,也是可以放在主文件组中的。
第8章 数据库后台编程技术
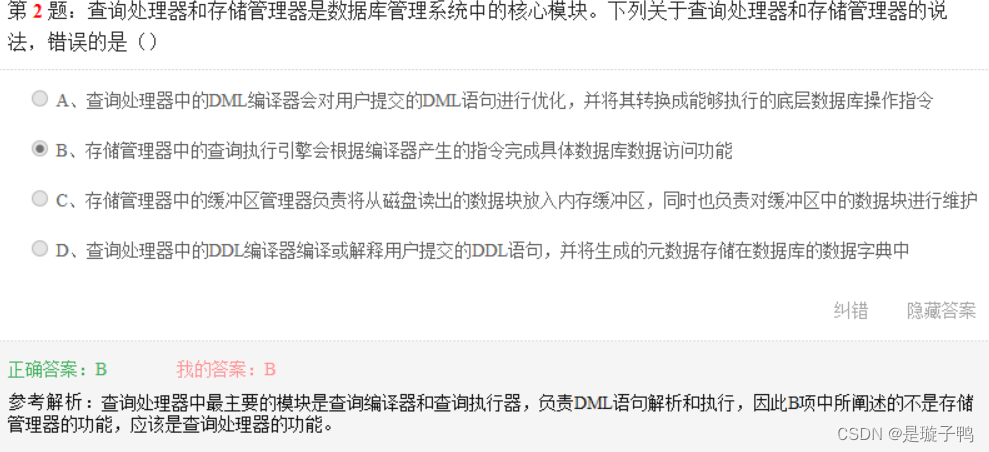
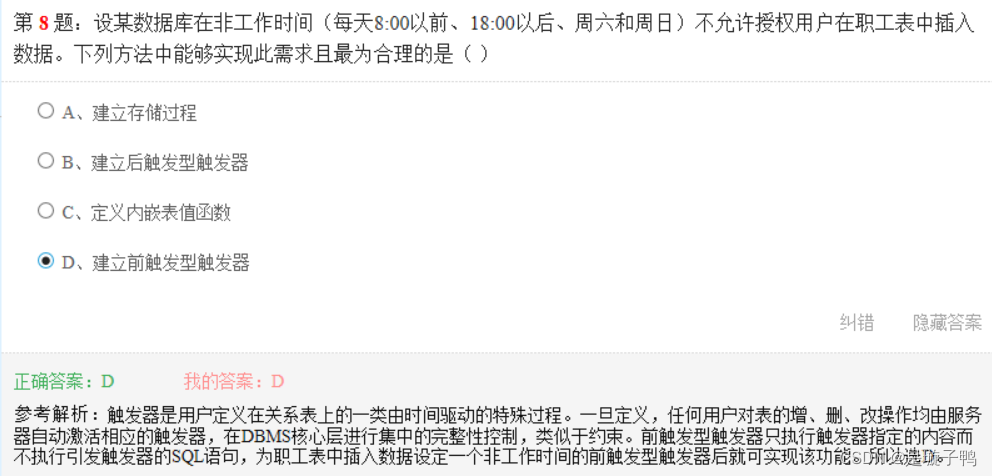
不能在视图上定义AFTER型触发器;
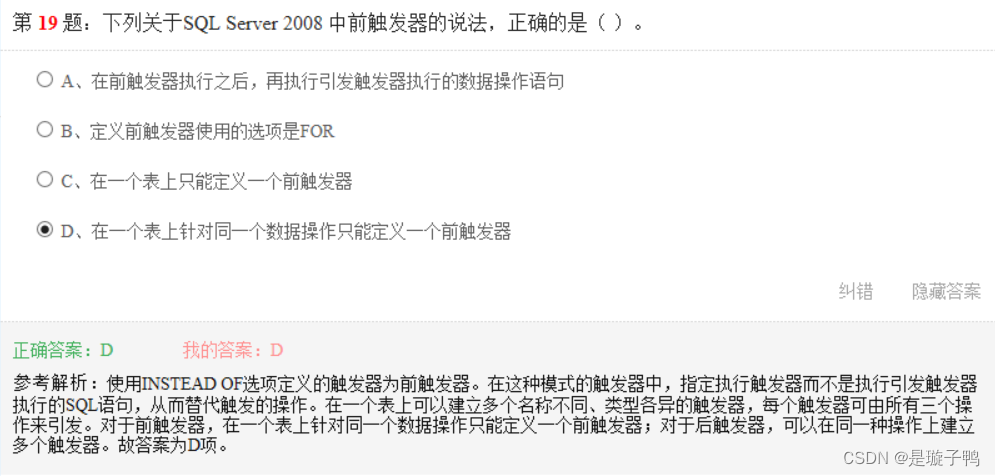
一张表上可以建立多个后触发器,但只能建立一个前触发器(针对同一个数据操作而言)。
如果未在声明游标时指定SCROLL,则NEXT是唯一支持的提取选项。
参数的传递方式有两种:按参数位置传递值和按参数名称传递值。
如果定义了默认值,则在执行存储过程时可以不必指定该参数的值。但若按照参数位置传递值时必须从左往右赋值,即不能跳过左边的某个默认参数而传递某个值。
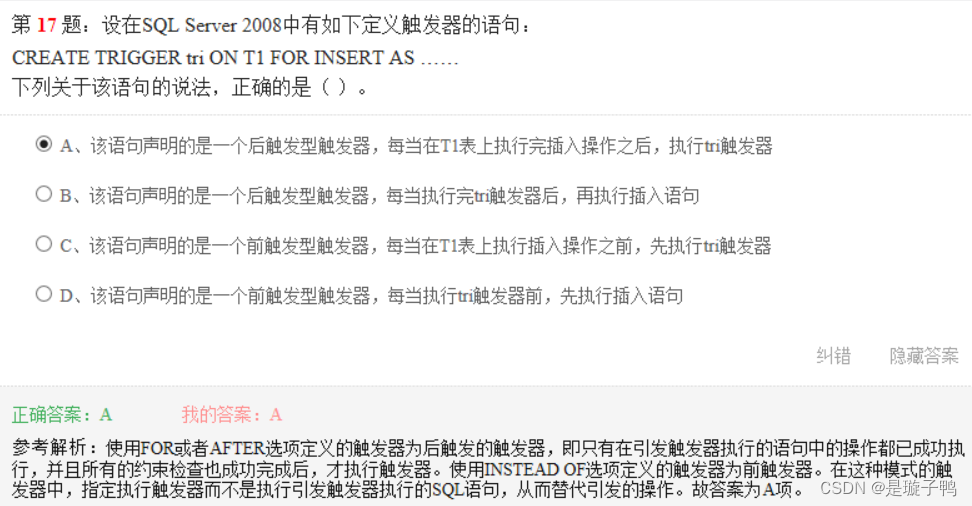
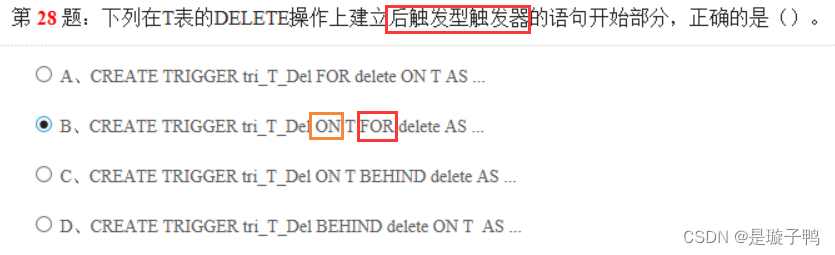
使用FOR或者AFTER选项定义的触发器为后触发的触发器。
第9章 安全管理

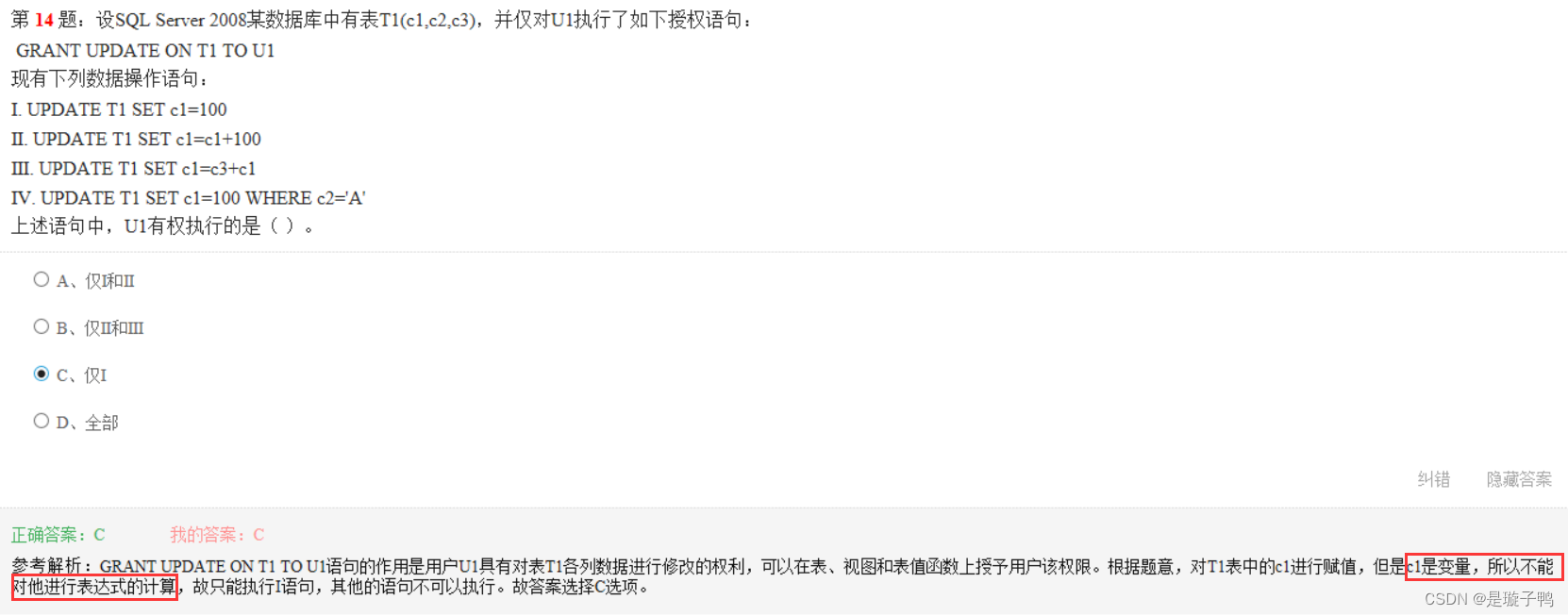
授权语法:GRANT 权限 TO 用户。
若要授予用户U1在DB1数据库中具有建表权限,则为CREATE TABLE TO U1。
补充:由于后面缺乏WITH GRANT OPTION语句,即无权将权限转授予其他角色或用户
数据库用户可分为系统管理员、对象拥有者和普通用户三类

授予用户U1具有创建表和视图权限
GRANT CREATE TABLE, CREATE VIEW TO U1;
收回用户U1在DB1数据库中的创建视图权限 REVOKE CREATE VIEW FROM U1
美国国防部发布的橘皮书和紫皮书对强制存取控制进行了全面的描述和定义,给出了通用安全性分级模型,定义了四类安全级别:
- A类 提供验证保护
- B类 提供强制保护
- C类 提供自主保护
- D类 提供最小保护
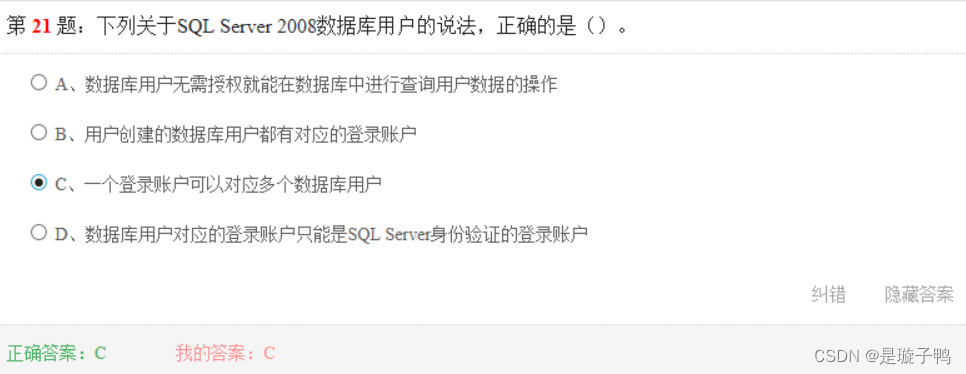
A 登录ID就是控制访问SQL Server数据库服务器的用户账户。如果未指定有效的登录ID,则用户不能连接到SQL Server数据库服务器
B 默认情况下,新建立的数据库只有一个用户dbo(database owner)
C 一个登陆账户可以映射为多个数据库中的用户,这种映射关系为同一服务器上不同数据库的权限管理带来很大的方便
D 在SQ; Server 2008中有两类登录账户。一类是由SQL Server自身负责身份验证的登录账户;另一类是登录到SQL Server的Windows网络账户,可以是组账户或用户账户
第10章 数据库运行维护与优化
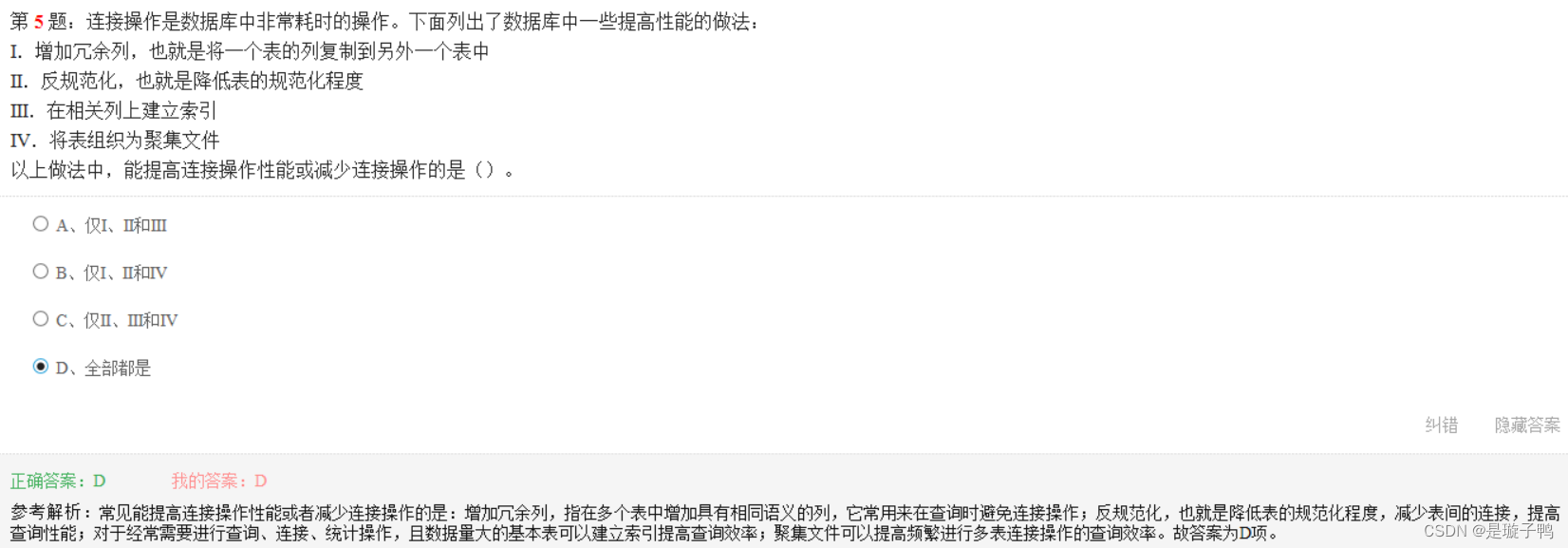
常见能提高连接操作性的是:
增加冗余列:在多个表中增加具有相同语义的列,常用于在查询时避免连接操作;
反规范化:降低表的规范化程度,减少表间的连接,提高查询性能;
建索引:针对经常需要进行查询、连接和统计操作,且数据量大的基本表;
聚类文件:提高频繁进行多表连接操作的查询效率。
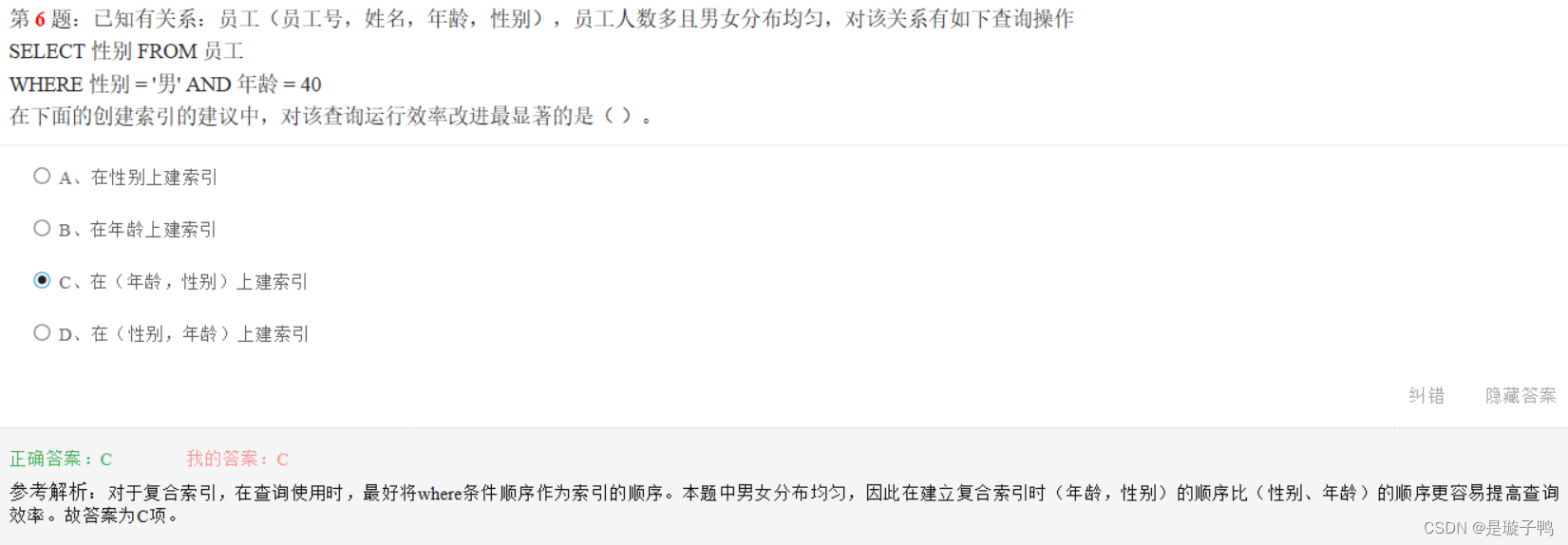
本题男女分布均匀,因此在建立复合索引时(年龄,性别)的顺序比(性别,年龄)的顺序更容易提高查询效率。

索引的使用原则:
- 经常在查询中作为条件被使用的列,应为其建立索引;
- 频繁进行排序或分组(即进行 group by 或 order by操作)的列,应为其建立索引;
- 一个列的值域很大时,应为其建立索引;
- 如果待排序的列有多个,应在这些列上建立复合索引;
- 可以使用系统工具来检查索引的完整性,必要时进行修复。
数据库运行维护与优化包括数据库的转储和恢复、数据库的安全性和完整性控制、数据库性能的监控分析与改进、数据库的重组和重构。(注意题目维护和优化单独询问的问法)
其中引入汇总表是属于数据库性能优化的一部分。
定期检查系统的源程序代码,确保系统正常运行,是系统开发人员的工作。
第11章 故障管理


自动恢复——数据库日志文件
数据恢复——数据库日志文件 + 数据库备份文件

RAID5具体和RAID1相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。
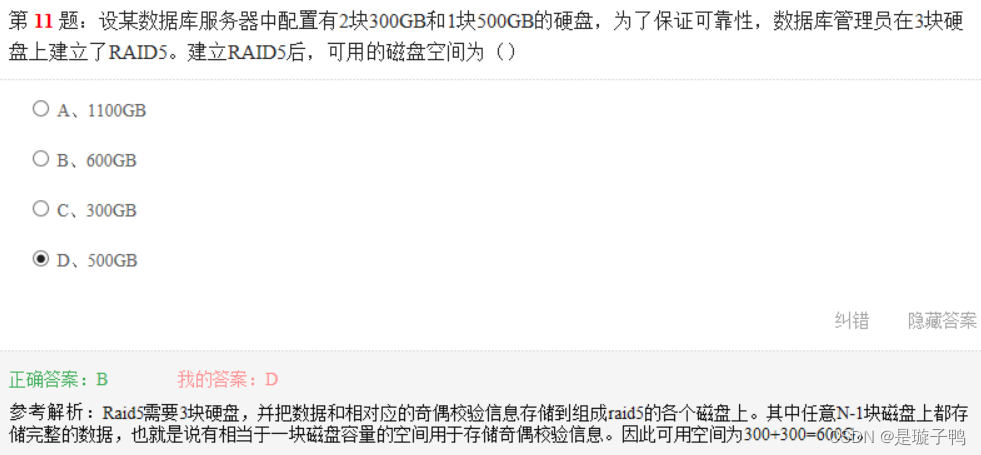
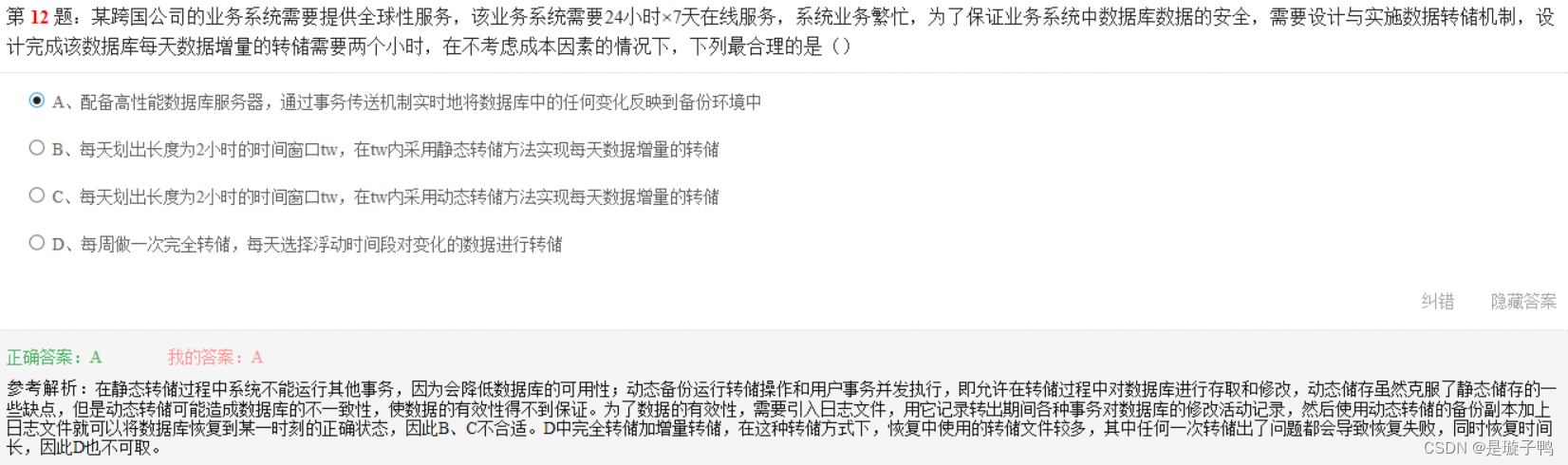
动态转储或造成数据的不一致性,使数据有效性得不到保证。故需要引入日志文件,利用动态转储的备份副本加上日志文件就可以使数据库恢复到某一时刻的正确状态。(注意题目:不考虑成本因素)

事务故障包括预期内的事务故障和非预期的事务故障,两种事务故障的恢复都是由系统自动完成的,对用户是透明的。
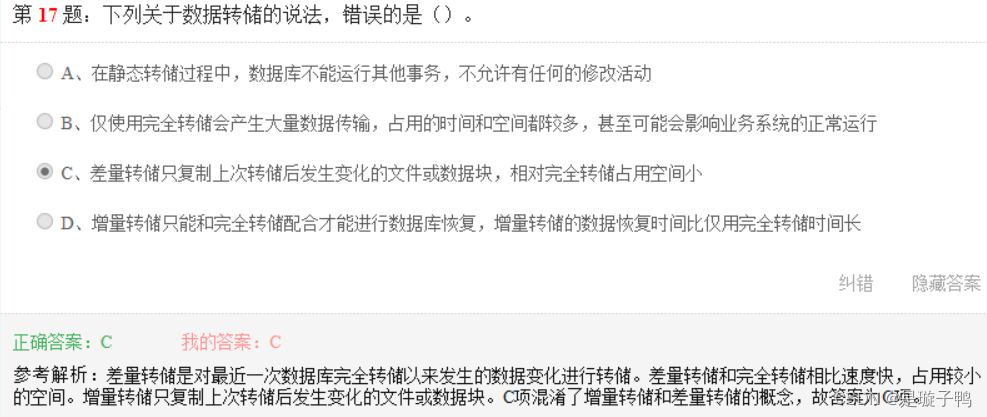
从数据恢复角度看,恢复时间:
差量转储>增量转储>完全转储
第12章 备份与恢复数据库
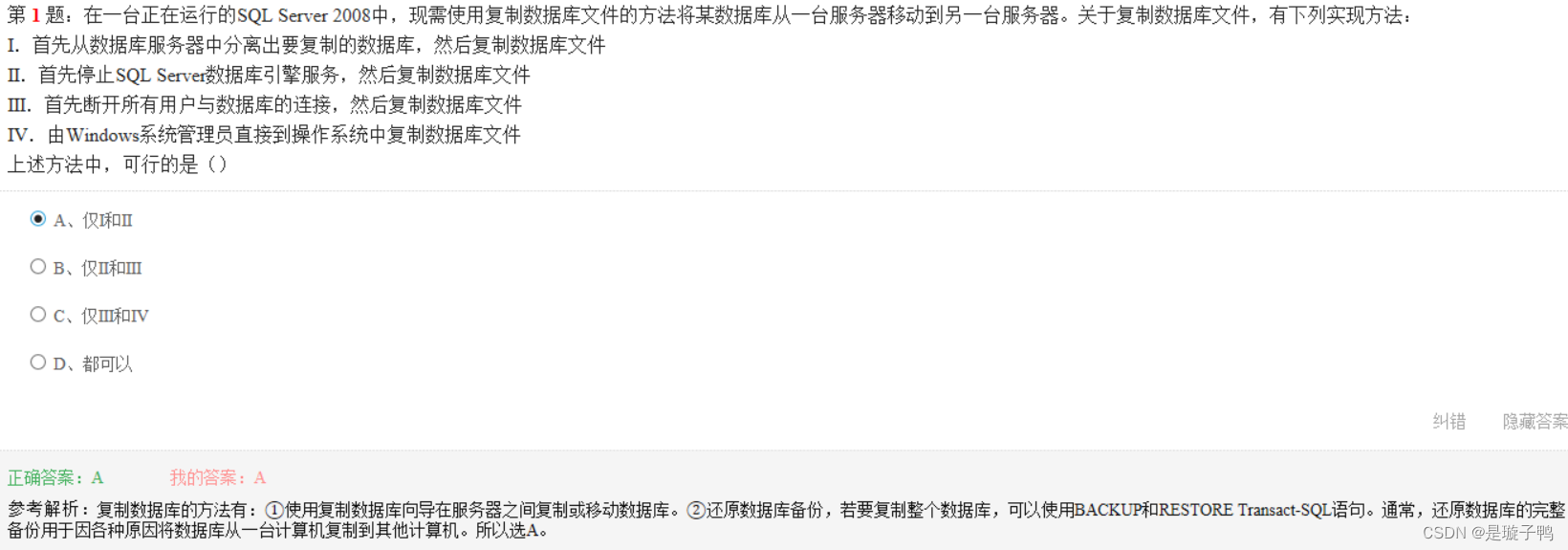

触发器常用于加强数据的完整性约束和业务规则等。事务是以可控的方式对数据资源进行访问的一组操作,事物的隔离性使得事务之间的交互程度有着严格的定义,保护了数据的完整性。
数据签名用于数据防篡改,定义主码是用于实体的完整性。
文件备份主要是对数据库中数据文件的备份,不对日志文件备份,因此在备份完成之后必须再对日志进行备份。
差异数据库备份:备份从最近的完整备份之后数据库的全部变化内容
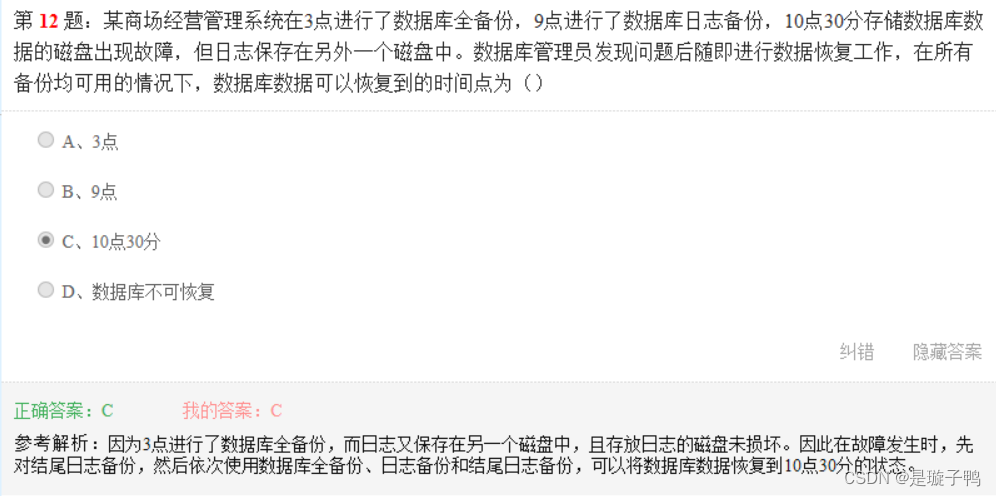
数据库的恢复顺序:
(1)还原最新完整数据库备份而不恢复数据库;
(2)如果存在差异备份,则还原最新的差异备份而不恢复数据库;
(3)从最后一次还原备份后创建的第一个事务日志开始,使用NORECOVERY选项依次还原日志;
(4)还原数据库,此步骤也可以与还原上一次日志备份结合使用。
第13章 大规模数据库架构
数据分配方式:
①集中式:所有数据片段都安排在同一个场地上;
②分割式:所有数据只有一份,它被分割成若干逻辑片段,每个逻辑片段被指派在一个特定的场地上;
③全复制式:数据在每个场地重复存储
④混合式:全局数据被分为若干个数据子集,每个子集都被安排在一个或多个不同的场地上,但每个场地未必保存所有数据
第14章 数据仓库与数据挖掘
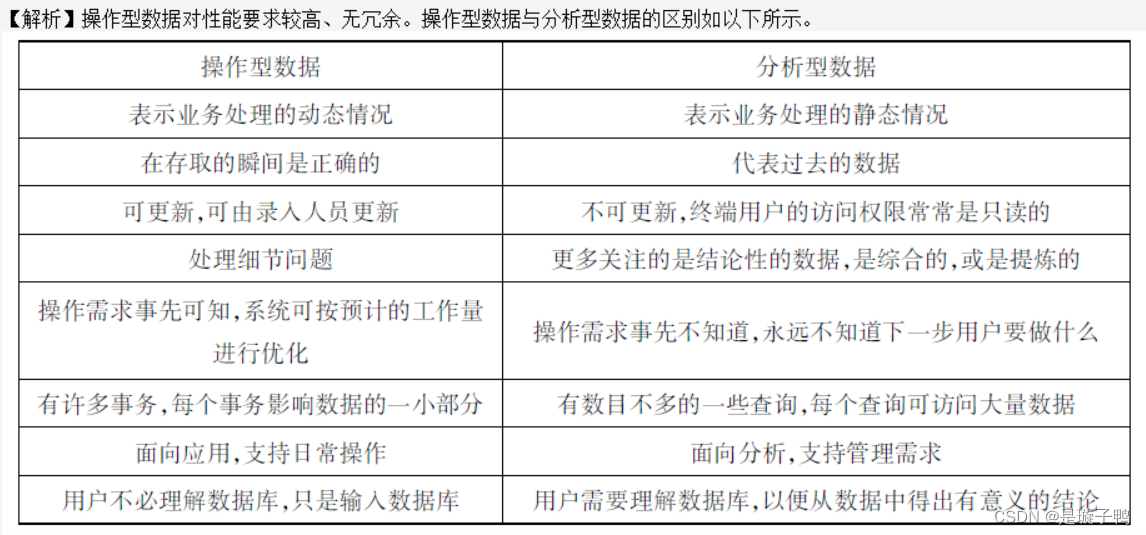
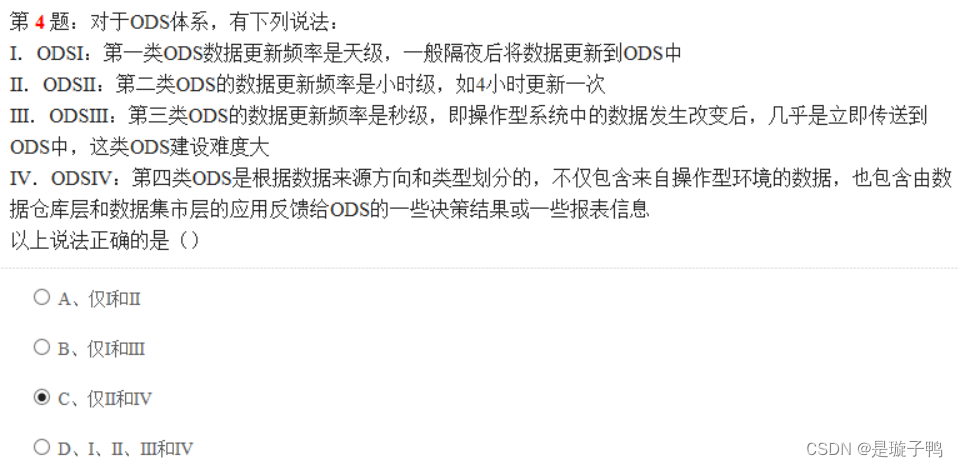
第一类ODS数据更新频率:秒级
第二类ODS数据更新频率:小时级
第三类ODS的数据更新频率:天级
上述三类根据数据更新的速度划分;
ODSIV:第四类ODS是根据数据来源方向和类型划分的
快照:该方法通过对当前数据表进行“照相”,记录当前的数据表信息“相片”,然后将当前的“相片”与以前的数据“相片”进行比较,如果不一致将通过一定的方式传到数据仓库,从而实现数据的一致性。该方式适合更新频率较低的数据表。
如书评表和乐评表主要用于记载用户的评论,里面的内容更新频率较高,而数据仓库的更新频率较低。因此,不适合用快照的方法。
对用户进行推荐时要结合以往的历史数据而不是仅通过当前数据分析
粒度:粒度越大,表示综合程度越高;粒度越小,综合程度越低,细节程度越高,数据量比较大,空间代价越大