第五个拥有"渤海麻将十三水原来一直总有挂!"原来是有挂(2024有挂版)
第五个拥有"渤海麻将十三水原来一直总有挂!"原来是有挂(2024有挂版)
第五个拥有"渤海麻将十三水原来一直总有挂!"原来是有挂(2024有挂版)是一款可以让一直输的玩家,快速成为一个“必胜”的ai辅助神器,渤海麻将十三水软件透明挂可以一键让你轻松成为“必赢”。其操作方式十分简单,打开这个应用便可以自定义渤海麻将十三水系统规律,只需要输入自己想要的开挂功能,一键便可以生成出微扑克专用辅助器,不管你是想分享给你好友或者wepoke ia辅助都可以满足你的需求。同时应用在很多场景之下这个渤海麻将十三水计算辅助也是非常有用的哦,使用起来简直不要太过有趣。特别是在大家渤海麻将十三水透明挂时可以拿来修改自己的牌型,让自己变成“教程”,让朋友看不出。凡诸如此种场景可谓多的不得了,非常的实用且有益,有需要的用户可以找(渤海麻将十三水)下载使用。;科技透明挂软件辅助器(有挂咨询 136704302)

第五个拥有"渤海麻将十三水原来一直总有挂!"原来是有挂(2024有挂版)(软件透明挂辅助器)
1、下载好渤海麻将十三水辅助软件之后点击打开,先需要设置辅助功能权限。
2、将渤海麻将十三水辅助透视无障碍功能菜单选项开启。
3、开启完成之后返回到上一个渤海麻将十三水辅助已下载的服务。
4、在界面中找到自动渤海麻将十三水开挂器,将其功能开启。
5、之后回到主界面,设置悬浮窗的教程。
6、这两个方法开启之后就可以点击启动进行使用。
7、启动之后就可以看到在技巧的左边会出现一列的功能栏,可以根据功能进行点击使用。
;科技透明挂软件辅助器(有挂咨询 136704302);
1、界面简单,没有任何广告弹出,只有一个编辑框。
2、没有风险,里面的渤海麻将十三水黑科技,一键就能快速透明。
3、上手简单,内置详细流程视频教学,新手小白可以快速上手。
4、体积小,不占用任何手机内存,运行流畅。
渤海麻将十三水系统规律输赢开挂技巧教程
1、用户打开应用后不用登录就可以直接使用,点击渤海麻将十三水软件透明挂所指区域
2、然后输入自己想要有的挂进行辅助开挂功能
3、返回就可以看到效果了,渤海麻将十三水透视辅助就可以开挂出去了
渤海麻将十三水软件透明挂玩家揭秘内幕秘籍教程
1、一款绝对能够让你火爆德州免费辅助神器app,可以将渤海麻将十三水插件进行任意的修改;
2、渤海麻将十三水计算辅助的首页看起来可能会比较low,填完方法生成后的技巧就和教程一样;
3、渤海麻将十三水透视辅助是可以任由你去攻略的,想要达到真实的效果可以换上自己的渤海麻将十三水软件透明挂。
渤海麻将十三水透视辅助ai黑科技系统规律教程开挂技巧
1、操作简单,容易上手;
2、效果必胜,一键必赢;
3、轻松取胜教程必备,快捷又方便
今天凌晨两点,OpenAI开启了12天技术分享直播,发布了最新“强化微调”(Reinforcement Fine-Tuning)计划。
与传统的微调相比,强化微调可以让开发者使用经过微调的更强专家大模型(例如,GPT-4o、o1),来开发适用于金融、法律、医疗、科研等不同领域的AI助手。
简单来说,这是一种深度定制技术,开发者可利用数十到数千个高质量任务,参照提供的参考答案对模型响应评分,让模型学习如何就类似问题推理,提高其在特定领域任务上的准确性和工作效率。

申请API:https://openai.com/form/rft-research-program/
在许多行业,虽然一些专家具有深厚的专业知识和丰富的经验,但在处理大规模数据和复杂任务时,可能会受到时间和精力的限制。
例如,在法律领域,律师需要处理大量的法律条文和案例,虽然他们能够凭借专业知识进行分析,但借助经过强化微调的 AI 模型,可以更快速地检索相关案例、进行初步的法律条文匹配和分析,为律师提供决策参考,提高工作效率。
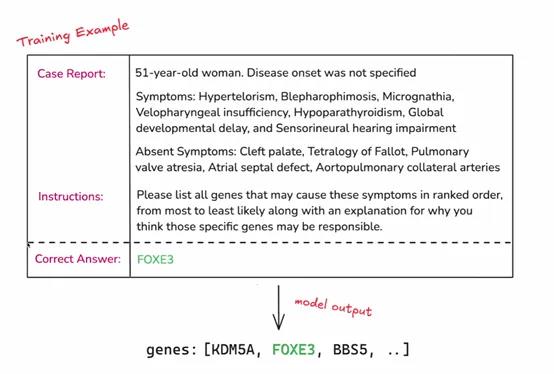
OpenAI表示,作为研究计划的一部分,参与者将能够访问处于alpha 阶段的强化微调 API。开发者可以利用该 API 将自己领域特定的任务数据输入到模型中,进行强化微调的实验和应用。
例如,一家医疗研究机构可以将大量的临床病例数据通过 API 输入到模型中,对模型进行医疗诊断任务的强化微调,使其能够更好地理解和处理各种疾病症状与诊断之间的关系。
目前该 API 仍处于开发阶段,尚未公开发布。所以,参与者在使用 API 过程中遇到的问题、对 API 功能的建议以及在特定任务上的微调效果等反馈,对于 OpenAI 改进 API 具有至关重要的作用。
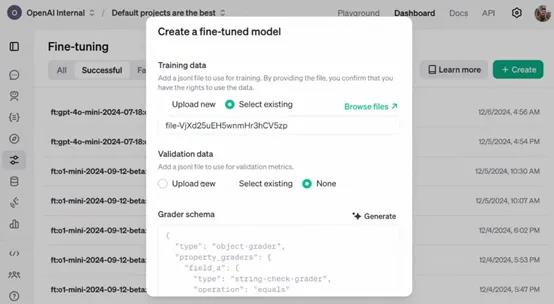
例如,企业在使用 API 对其财务风险评估模型进行微调时,如果发现模型在处理某些特殊财务数据结构时出现错误或不准确的情况,将这些信息反馈给 OpenAI,能够帮助其优化 API 中的数据处理算法和模型参数调整策略,从而使 API 更加完善,为后续的公开发布做好准备。
强化微调简单介绍
强化微调是一种在机器学习和深度学习领域,特别是在大模型微调中使用的技术。这项技术融合了强化学习的原理,以此来优化模型的性能。微调是在预训练模型的基础上进行的,预训练模型已经在大量数据上训练过,学习到了通用的特征。
通过无监督学习掌握了语言的基本规律,然后在特定任务上进行微调,以适应新的要求。强化学习则关注智能体如何在环境中采取行动以最大化累积奖励,这在机器人训练中尤为重要,智能体通过不断尝试和学习来找到最优策略。
强化微调则是将强化学习的机制引入到微调过程中。在传统微调中,模型参数更新主要基于损失函数,而在强化微调中,会定义一个奖励信号来指导这个过程。
这个奖励信号基于模型在特定任务中的表现,比如在对话系统中,模型生成的回答如果能够引导对话顺利进行并获得好评,就会得到正的奖励。策略优化是利用强化学习中的算法,如策略梯度算法,根据奖励信号来更新模型参数。
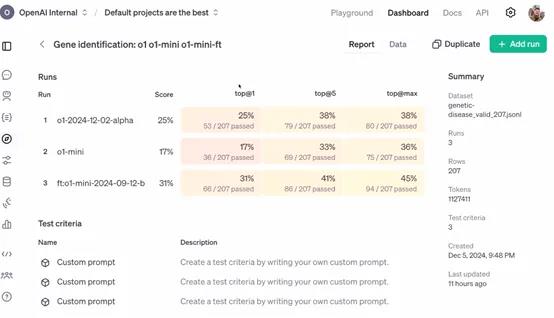
在这个过程中,模型就像智能体一样,它的参数调整策略就是需要优化的策略,而奖励信号就是对这个策略的评价。
此外,强化微调还需要平衡探索和利用,即模型既要利用已经学到的知识来稳定获得奖励,又要探索新的参数空间以找到更优的配置。
收集人类反馈数据,通常是关于模型输出质量的比较数据。通过这些反馈训练一个奖励模型,该模型能够对语言模型的输出进行打分,以反映其质量或符合人类期望。