第4个明晓(微扑克挂原来一直俱有挂)外挂透明挂辅助器透视挂!拥有50%(2022有挂版)
第4个明晓(微扑克挂原来一直俱有挂)外挂透明挂辅助器透视挂!拥有50%(2022有挂版)是一款休闲益智类微扑克手游,是一种起源于欧洲的棋牌类游戏,已经流行于全世界。在游戏中玩家们可以一键邀请好友一同进行游戏,操作十分简单且有趣,包含了WePoKer、微扑克、AAPoKer、德扑之星、HHPoKer、AA扑克…特色应有尽有。另外,一起其中包括微扑克是有挂,微扑克有辅助,微扑克有透明挂,有微扑克软件透明挂,有微扑克辅助挂,微扑克有攻略,有微扑克辅助是真是假,微扑克是真的有人在用的其实确实存在挂黑科技,你可以与同队伙伴共享彼此的全部手牌信息,合作才能赢得比赛胜利,玩法非常多,如果喜欢这类游戏的话欢迎来下载体验。
微扑克 外 挂 透明挂 辅助器 咨 询 小 薇 136704302 咨 询 了 解!
1、和全球小伙伴一起WPK
匹配来自全球各地的玩家,让你结识全世界的小伙伴,解锁跨国交流新际遇。
2、创新WePoKe ai辅助对家共享手牌
微扑克辅助协同作战!与同队伙伴共享彼此的全部手牌信息,合作才能赢得比赛胜利!
3、好友开房微扑克辅助挂自定义规则
好友聚会,效果却不一样?连续透明、换牌、控制胜率……自由定义比赛规则,让你体验不同乐趣,麻麻再也不怕我和小伙伴玩不到一起去啦!
4、大声喊出德州才算胜利
一起黑科技只剩一张手牌时大声喊出“WePoKe软件透明挂”,挑战高分贝一次激活,给你原汁原味的聚会感觉!
5、海量wpk辅助透视,刺激大冒险
内容丰富的微扑克辅助软件“软件透明挂”,赢家翻牌选择趣味惩罚及惩罚对象,聚会更添欢乐。

【介绍】目前WePoKe软件透明挂抢先体验版的规则是根据国外的通用规则制定,大家也可以在房间模式中自定义游戏规则,支持wepoke透明挂、WEPOKER辅助挂和强制出牌规则哦。
【微扑克介绍】
WPK辅助透视构成,包括微扑克辅助软件、WePoKe辅助挂和8张万能牌。同时,wpk透视辅助由四种颜色构成,包括红色、黄色、蓝色、绿色。
1、数字牌
根据微扑克辅助插件由0到9构成,每种颜色包括WPK辅助挂张数字0、2张数字1-9。
2、功能牌
微扑克 外 挂 透明挂 辅助器 咨 询 小 薇 136704302 咨 询 了 解。
(1)WePoKe软件透明挂:下家抓2张牌,跳过本回合。
(2)微扑克辅助挂工具:出牌方向翻转。
(3)wpk辅助透视软件:下家跳过本回合出牌。
3、万能牌
微扑克是有挂,微扑克有辅助,微扑克有透明挂,有微扑克软件透明挂,有微扑克辅助挂,微扑克有攻略,有微扑克辅助是真是假,微扑克是真的有人在用的其实确实存在挂黑科技。
微扑克 外 挂 透明挂 辅助器 咨 询 小 薇 136704302 咨 询 了 解!
一、微扑克战术策略
1、手中掌握牌型的概率和价值
2、适当调整筹码耗去的比例
3、灵活运用加注和跟注
二、微扑克心理战术
1、观察对手的行为和身体语言
2、获取对手的心理线索
3、形象的修辞心理战术无法发展对手的决策
三、微扑克人脉关系
1、与老练的玩家交流学习
2、组建良好的思想品德的社交网络
3、组织或参加过扑克俱乐部和比赛
四、微扑克经验累积
1、正常参加过微扑克比赛
2、记录信息和讲自己的牌局经验
3、缓慢学习和提升自己的技巧
今天凌晨两点,OpenAI开启了12天技术分享直播,发布了最新“强化微调”(Reinforcement Fine-Tuning)计划。
与传统的微调相比,强化微调可以让开发者使用经过微调的更强专家大模型(例如,GPT-4o、o1),来开发适用于金融、法律、医疗、科研等不同领域的AI助手。
简单来说,这是一种深度定制技术,开发者可利用数十到数千个高质量任务,参照提供的参考答案对模型响应评分,让模型学习如何就类似问题推理,提高其在特定领域任务上的准确性和工作效率。

申请API:https://openai.com/form/rft-research-program/
在许多行业,虽然一些专家具有深厚的专业知识和丰富的经验,但在处理大规模数据和复杂任务时,可能会受到时间和精力的限制。
例如,在法律领域,律师需要处理大量的法律条文和案例,虽然他们能够凭借专业知识进行分析,但借助经过强化微调的 AI 模型,可以更快速地检索相关案例、进行初步的法律条文匹配和分析,为律师提供决策参考,提高工作效率。
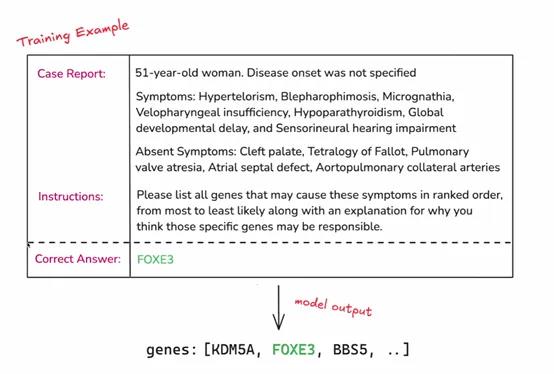
OpenAI表示,作为研究计划的一部分,参与者将能够访问处于alpha 阶段的强化微调 API。开发者可以利用该 API 将自己领域特定的任务数据输入到模型中,进行强化微调的实验和应用。
例如,一家医疗研究机构可以将大量的临床病例数据通过 API 输入到模型中,对模型进行医疗诊断任务的强化微调,使其能够更好地理解和处理各种疾病症状与诊断之间的关系。
目前该 API 仍处于开发阶段,尚未公开发布。所以,参与者在使用 API 过程中遇到的问题、对 API 功能的建议以及在特定任务上的微调效果等反馈,对于 OpenAI 改进 API 具有至关重要的作用。
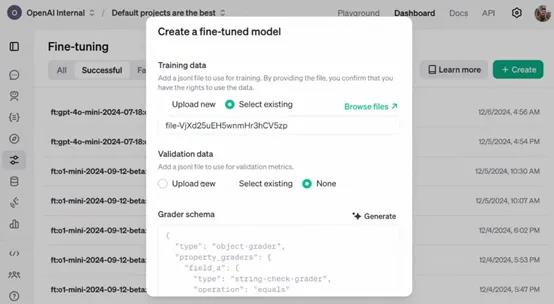
例如,企业在使用 API 对其财务风险评估模型进行微调时,如果发现模型在处理某些特殊财务数据结构时出现错误或不准确的情况,将这些信息反馈给 OpenAI,能够帮助其优化 API 中的数据处理算法和模型参数调整策略,从而使 API 更加完善,为后续的公开发布做好准备。
强化微调简单介绍
强化微调是一种在机器学习和深度学习领域,特别是在大模型微调中使用的技术。这项技术融合了强化学习的原理,以此来优化模型的性能。微调是在预训练模型的基础上进行的,预训练模型已经在大量数据上训练过,学习到了通用的特征。
通过无监督学习掌握了语言的基本规律,然后在特定任务上进行微调,以适应新的要求。强化学习则关注智能体如何在环境中采取行动以最大化累积奖励,这在机器人训练中尤为重要,智能体通过不断尝试和学习来找到最优策略。
强化微调则是将强化学习的机制引入到微调过程中。在传统微调中,模型参数更新主要基于损失函数,而在强化微调中,会定义一个奖励信号来指导这个过程。
这个奖励信号基于模型在特定任务中的表现,比如在对话系统中,模型生成的回答如果能够引导对话顺利进行并获得好评,就会得到正的奖励。策略优化是利用强化学习中的算法,如策略梯度算法,根据奖励信号来更新模型参数。
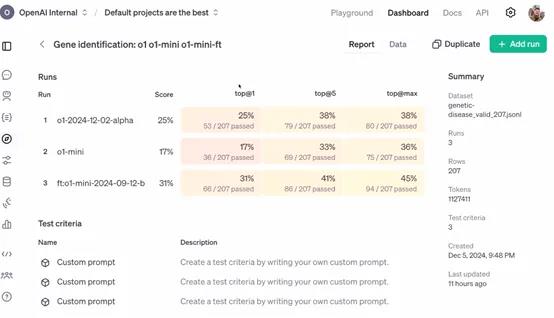
在这个过程中,模型就像智能体一样,它的参数调整策略就是需要优化的策略,而奖励信号就是对这个策略的评价。
此外,强化微调还需要平衡探索和利用,即模型既要利用已经学到的知识来稳定获得奖励,又要探索新的参数空间以找到更优的配置。
收集人类反馈数据,通常是关于模型输出质量的比较数据。通过这些反馈训练一个奖励模型,该模型能够对语言模型的输出进行打分,以反映其质量或符合人类期望。